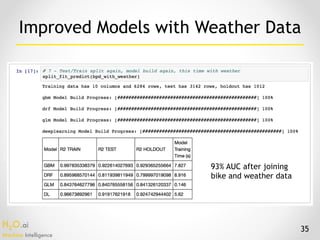
The document presents a comprehensive overview of H2O.ai's capabilities in scalable data science and deep learning, featuring its architecture, real-time applications, and performance benchmarks. It discusses various use cases, such as airline delay predictions and fraud detection, while showcasing live demos and performance statistics. H2O is positioned as a powerful open-source tool suitable for machine learning tasks across different domains, emphasizing speed, accuracy, and scalability.




























































































































![Getting Started with Apache Spark: Big Data Made Simple [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/apachesparkgettingstarted-260203175547-8361bcc3-thumbnail.jpg?width=640&height=640&fit=bounds)







