Downloaded 80 times



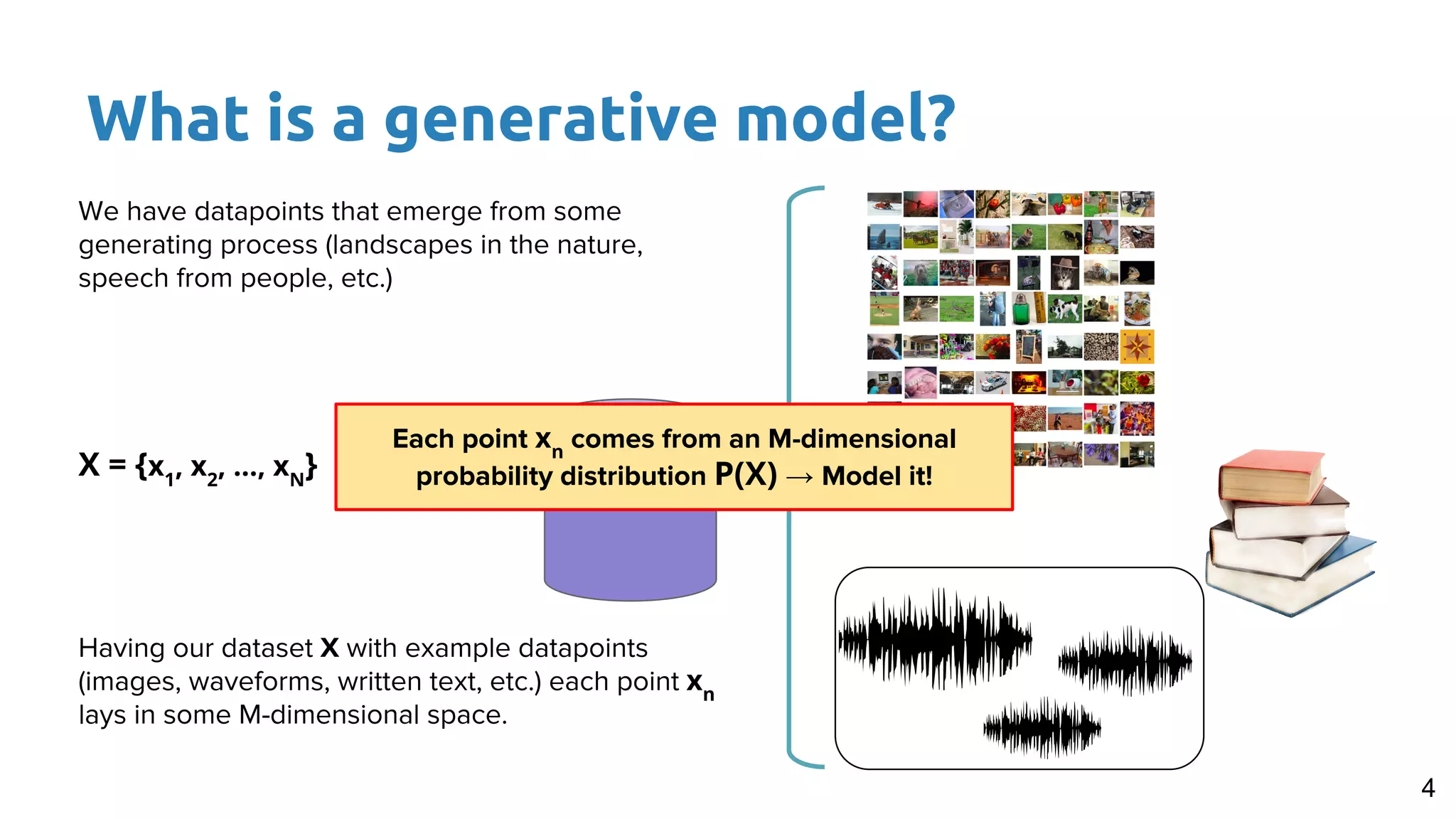
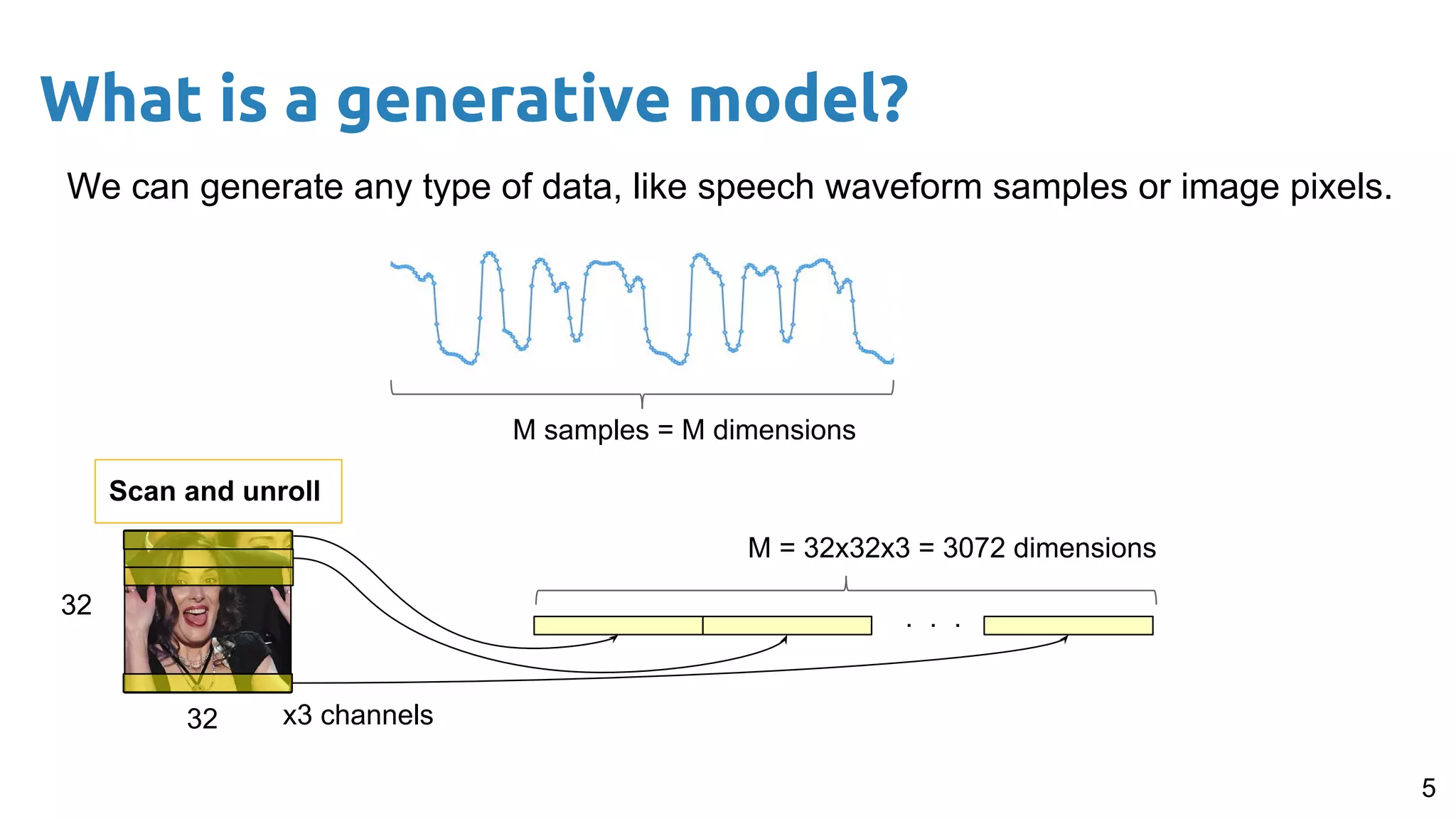


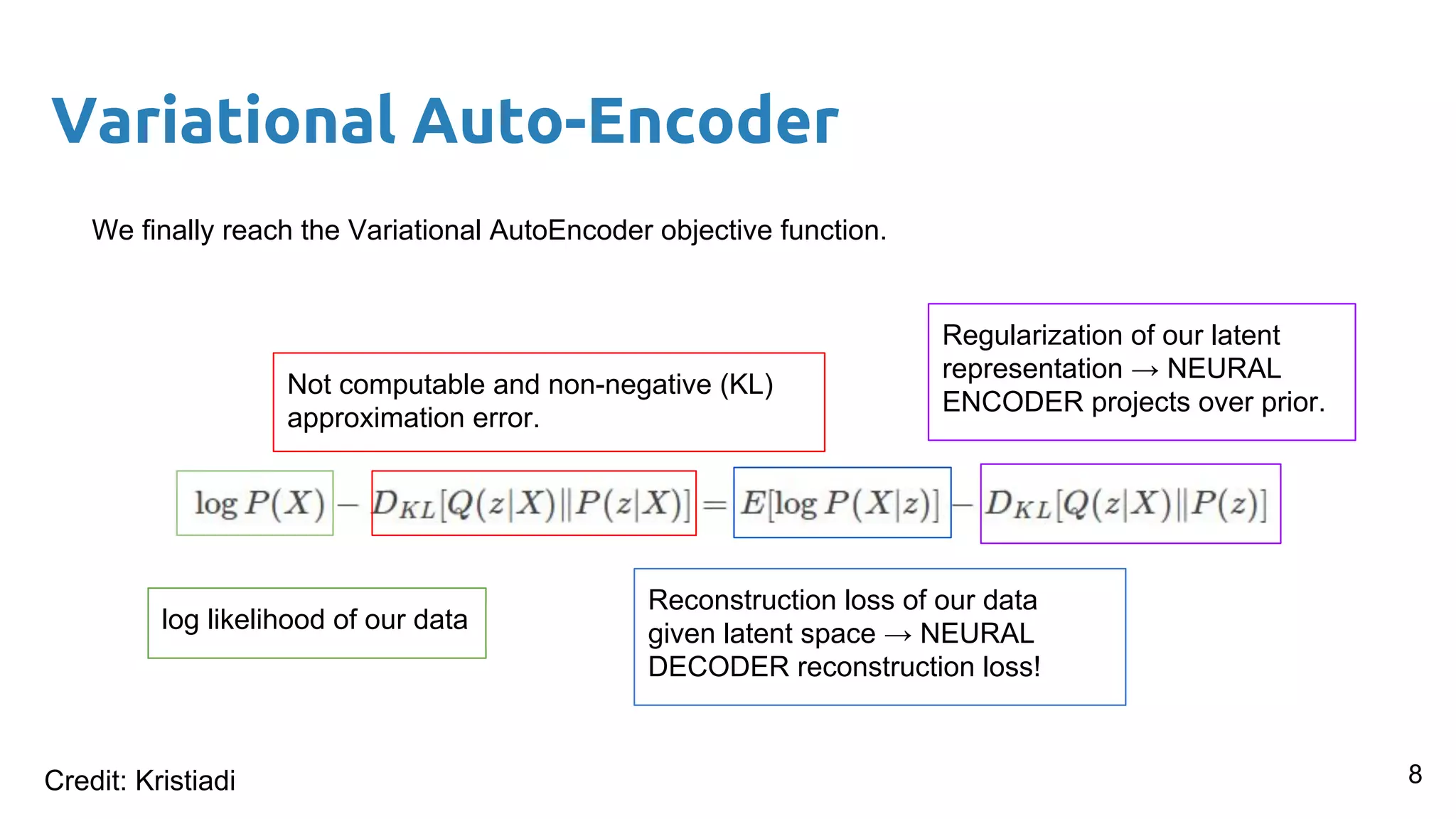
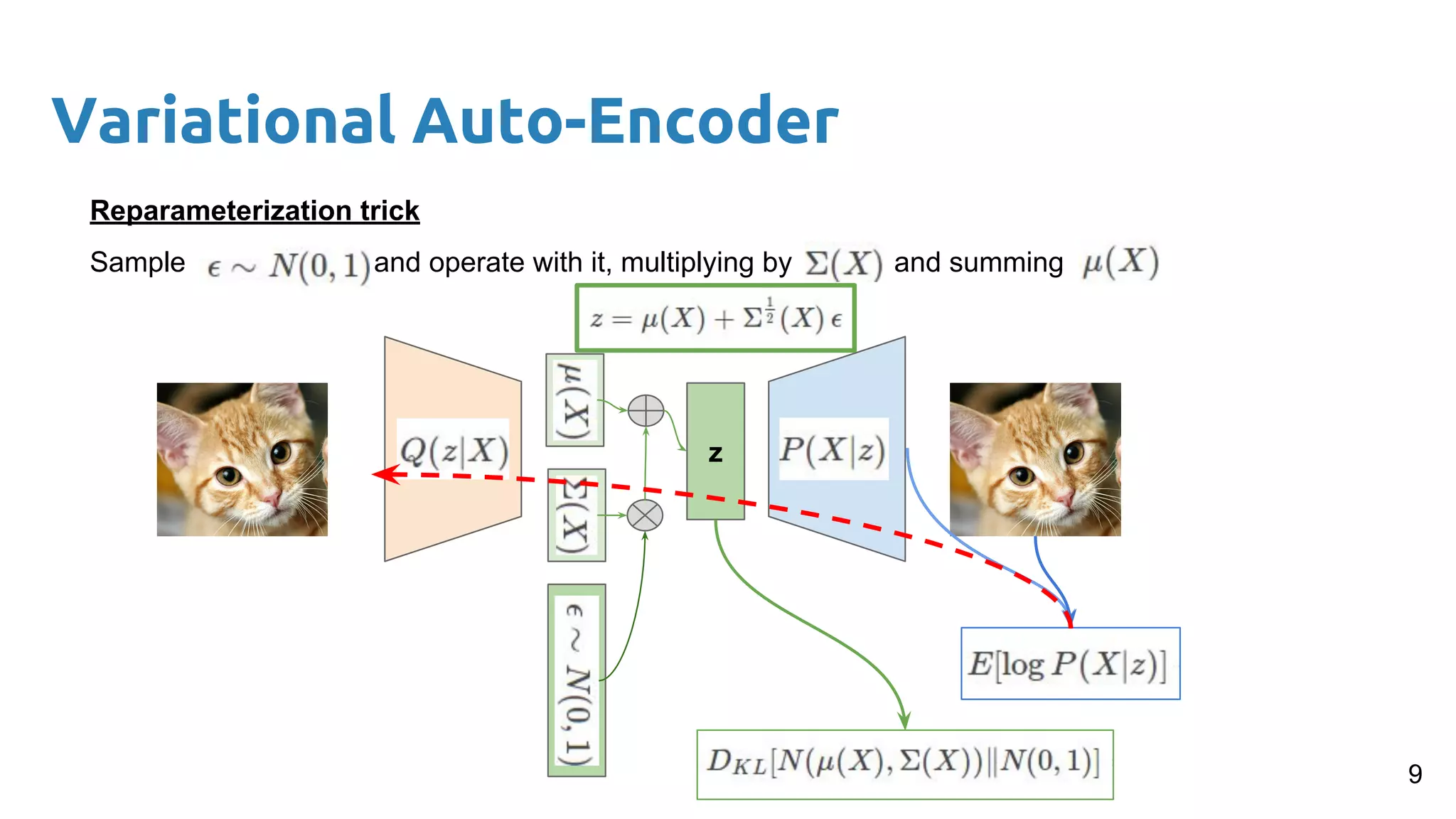
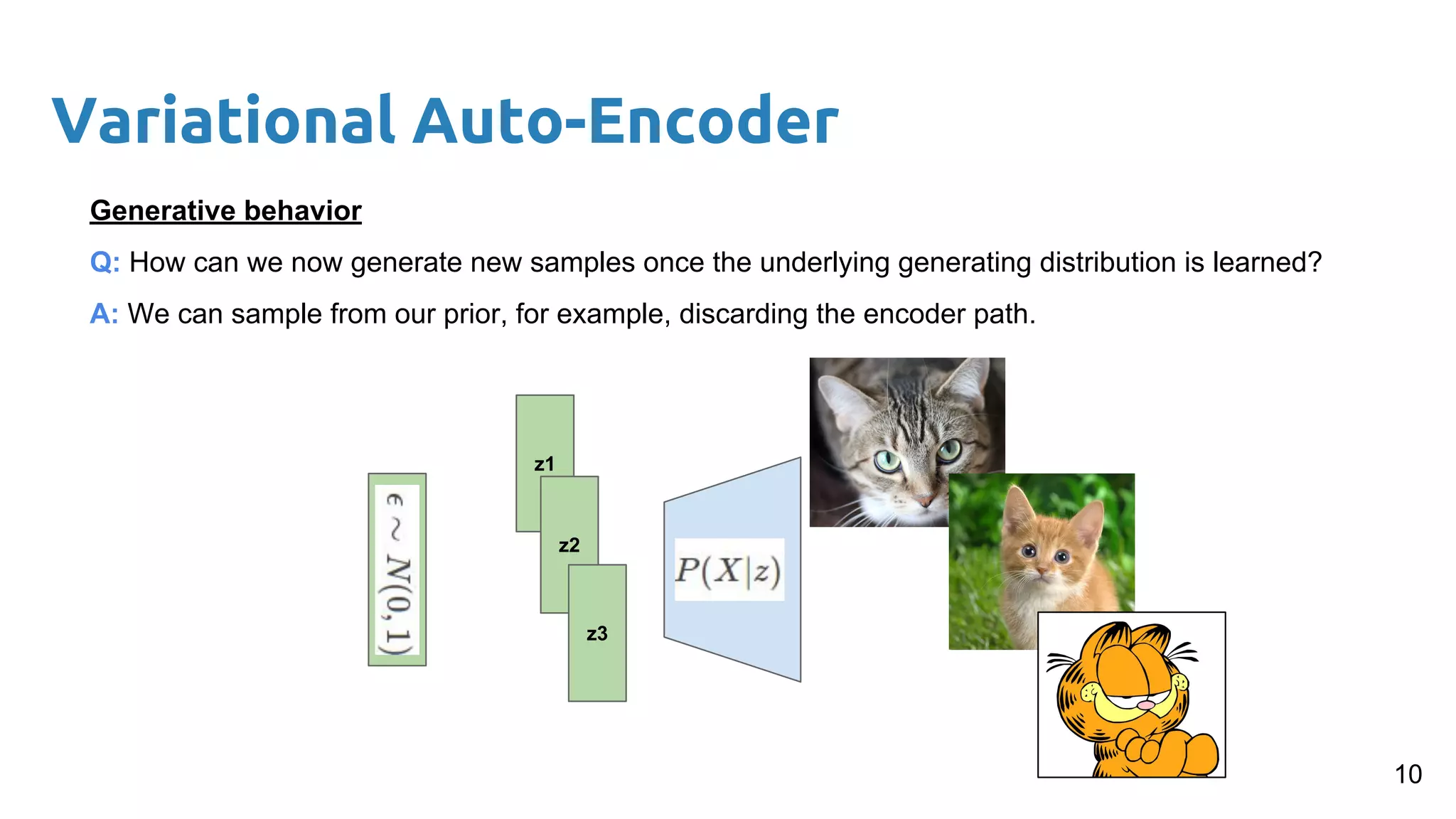
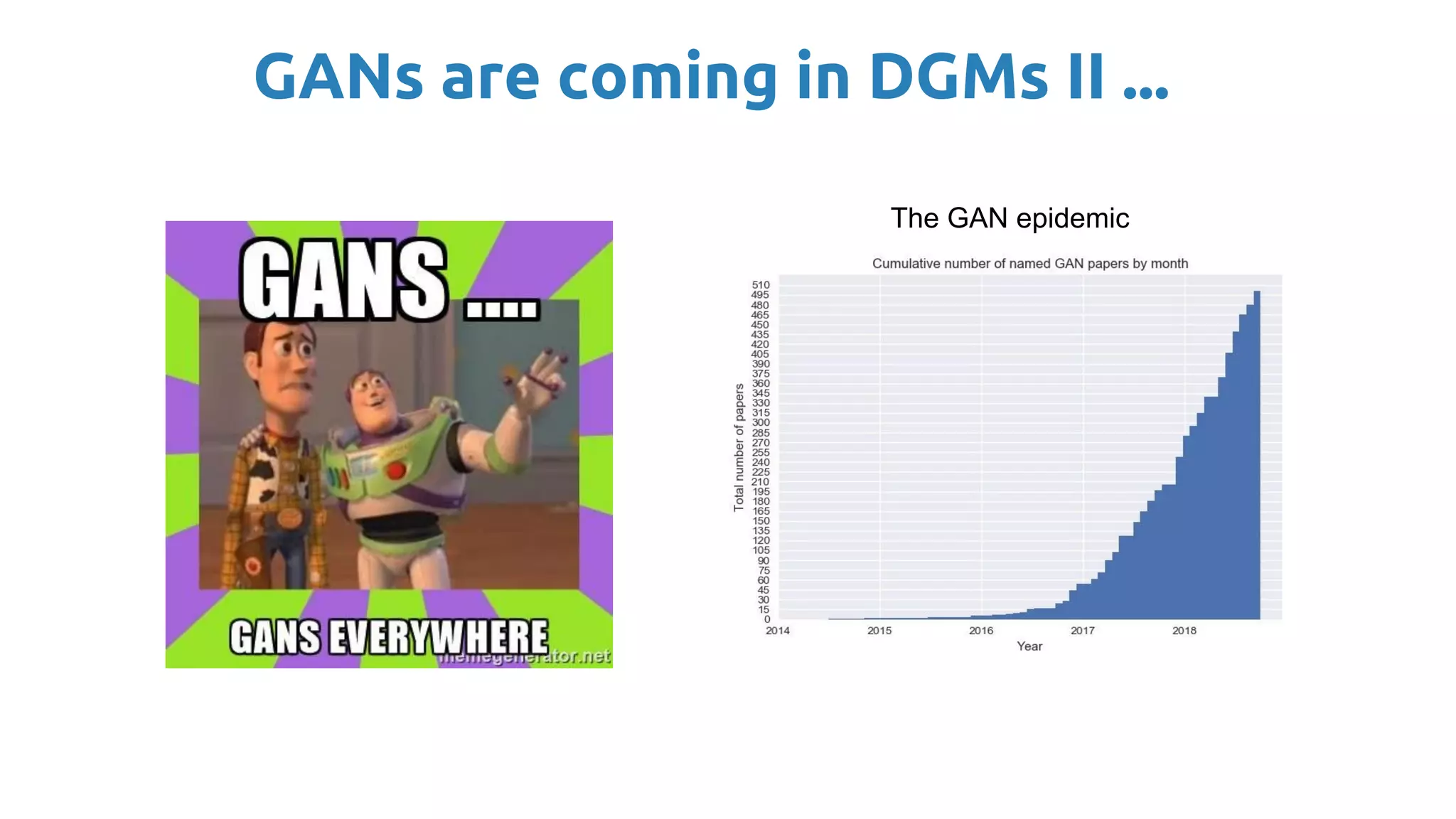



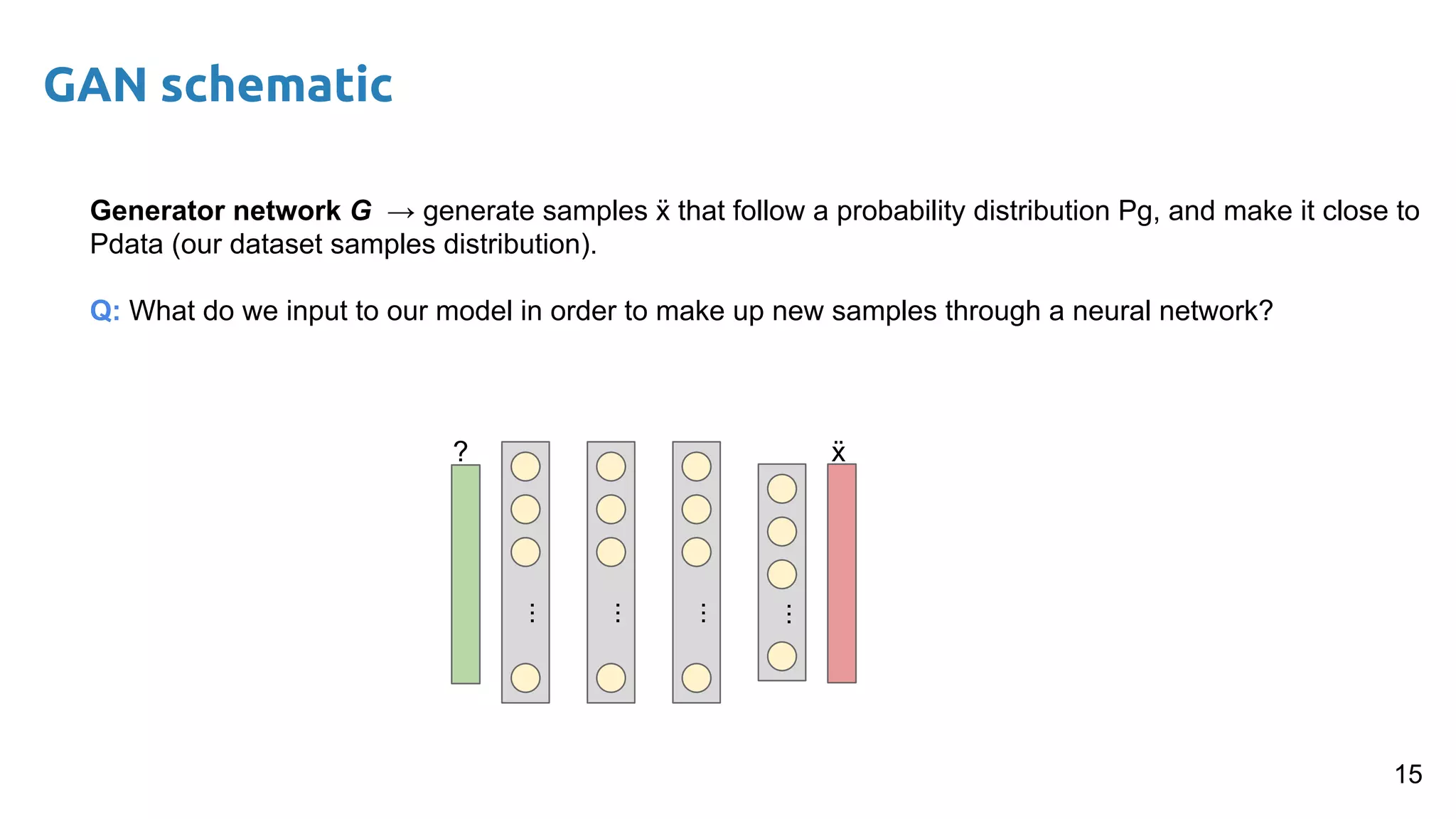

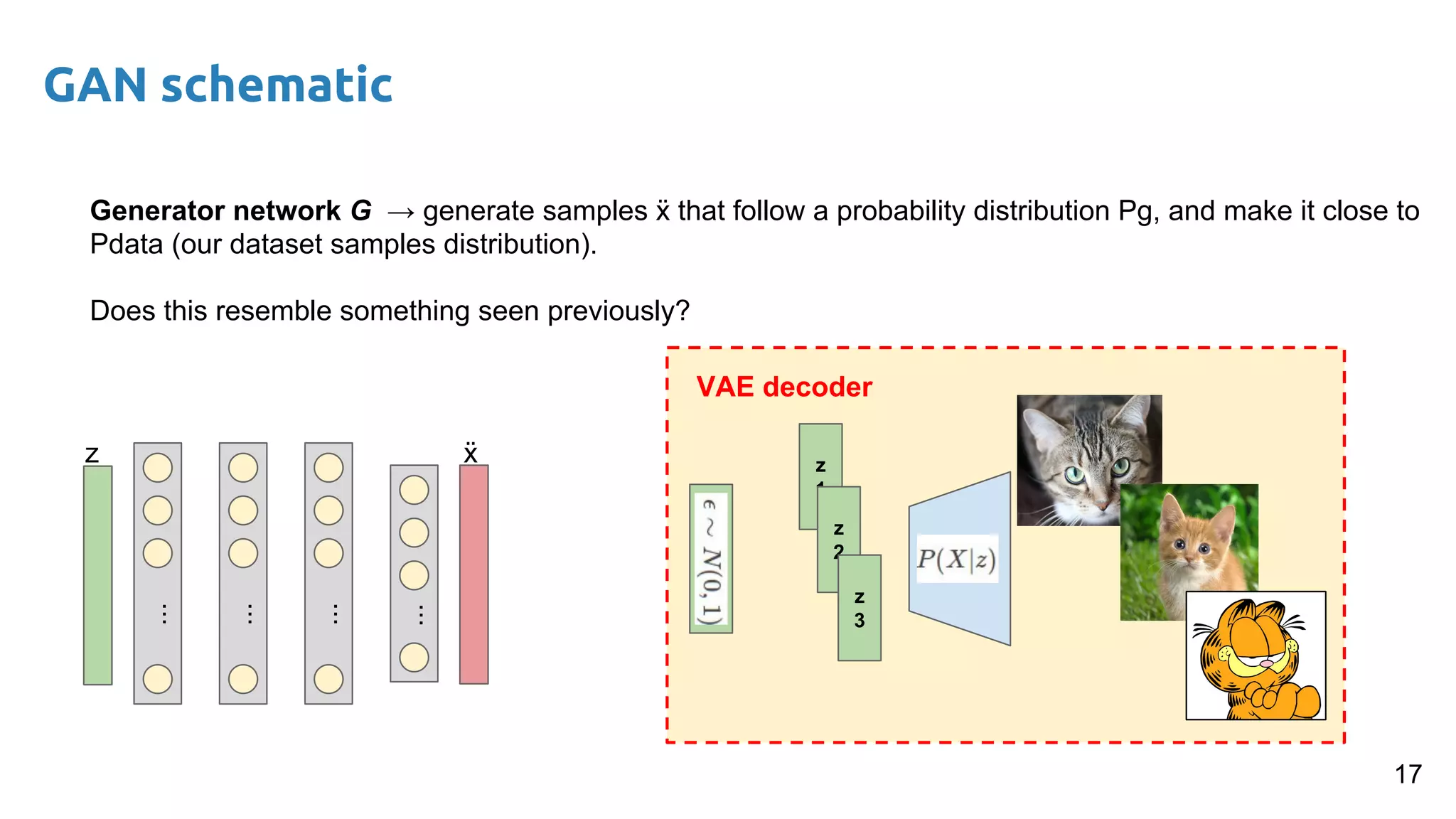
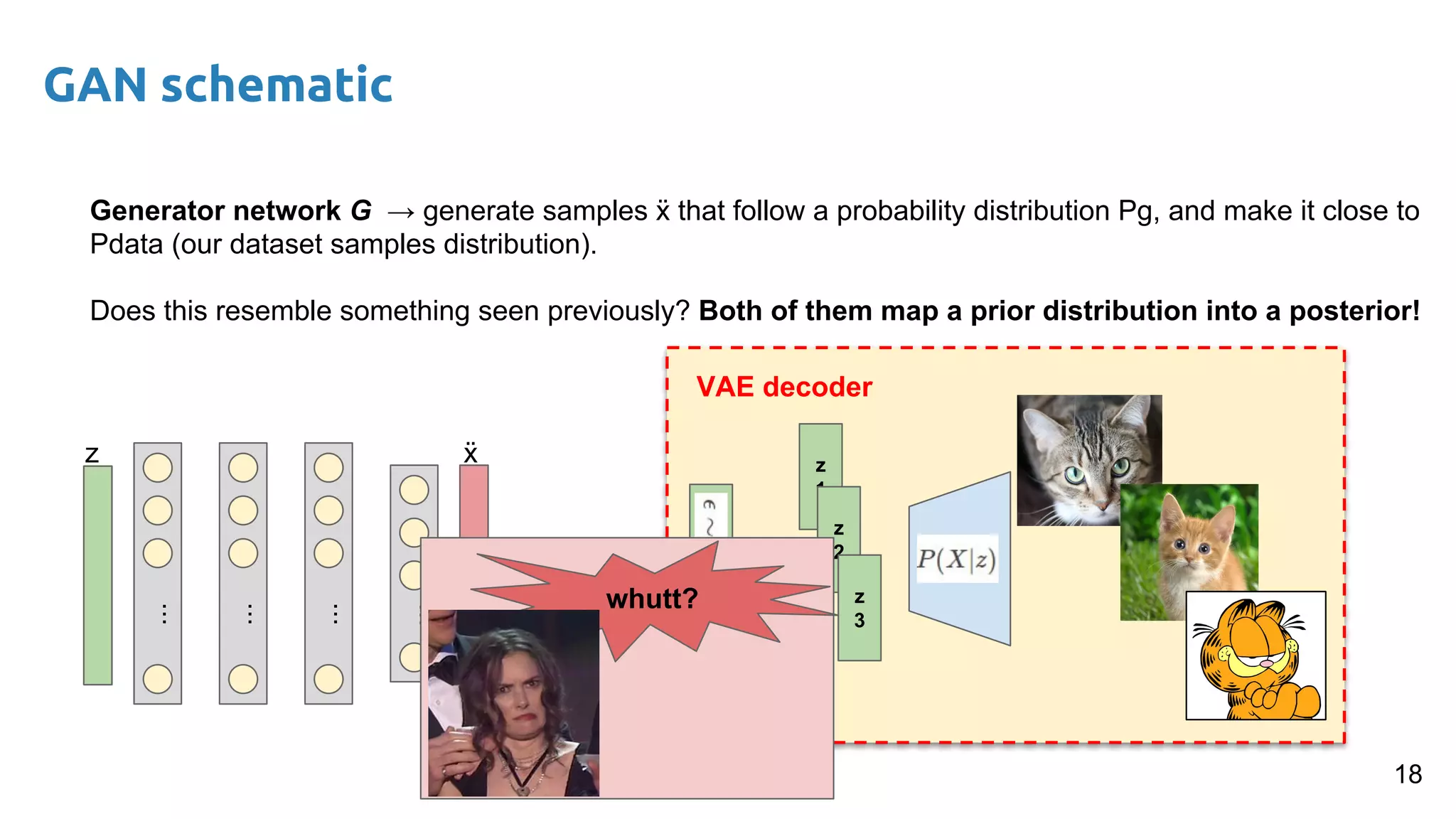
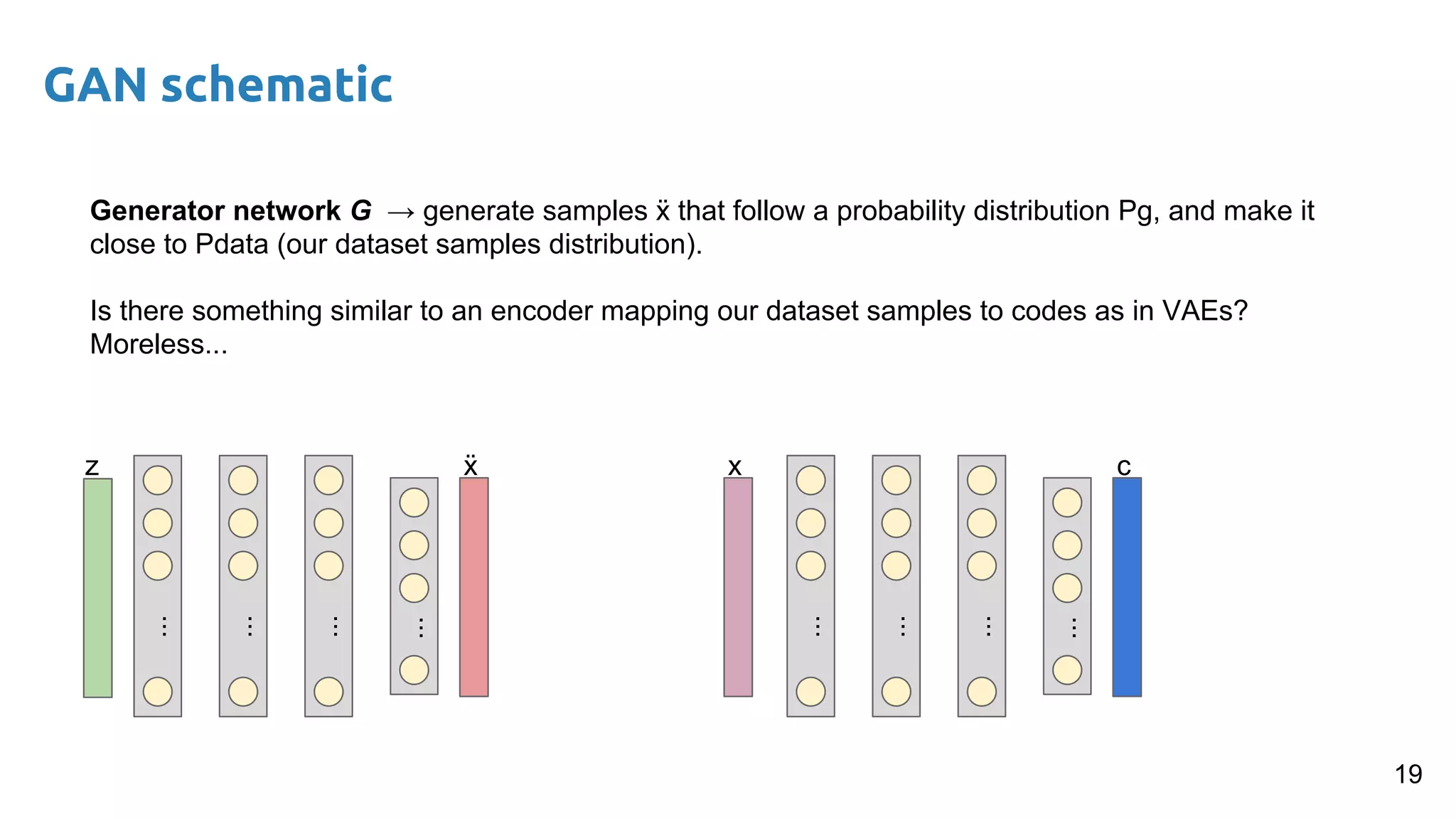



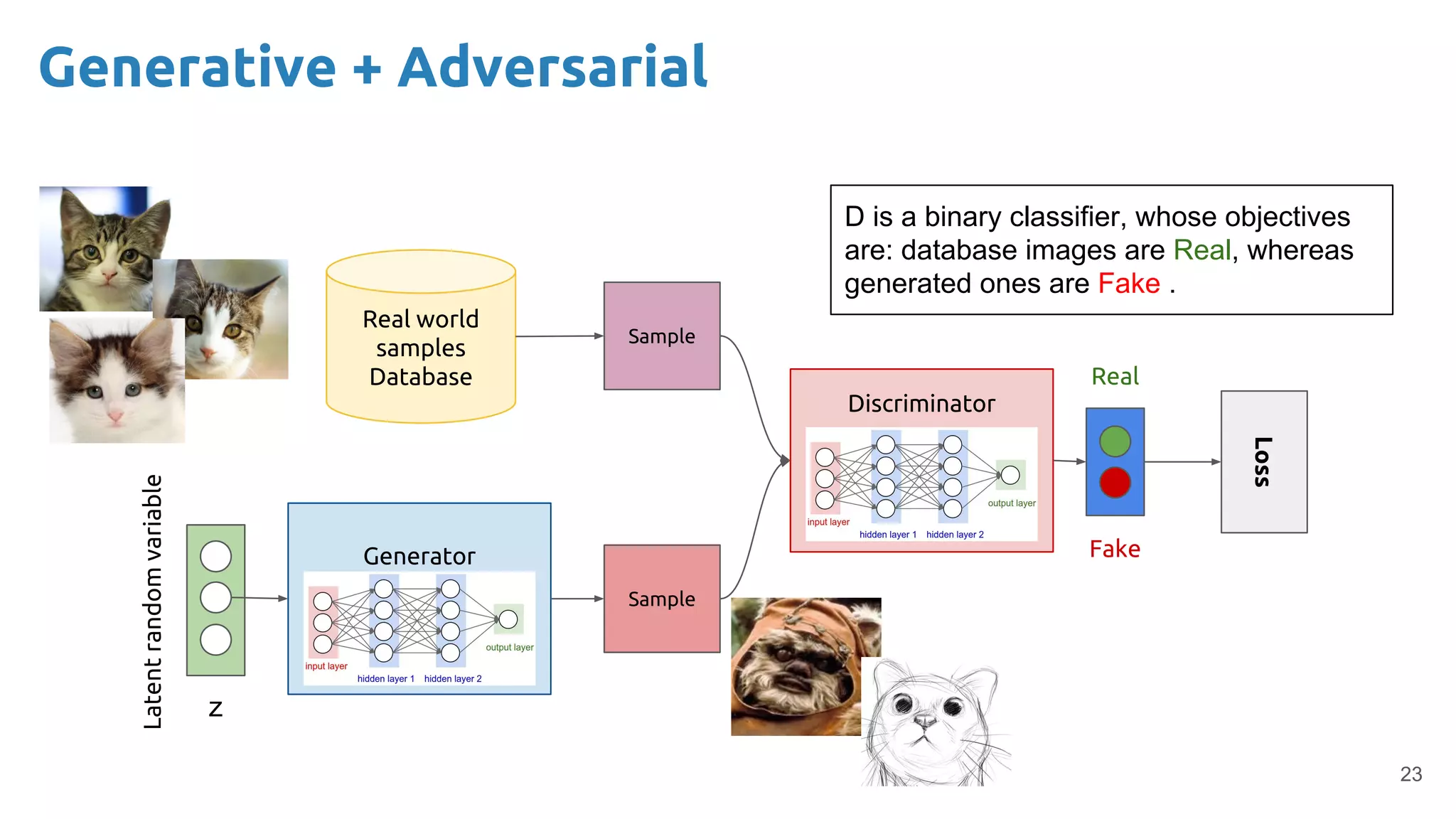


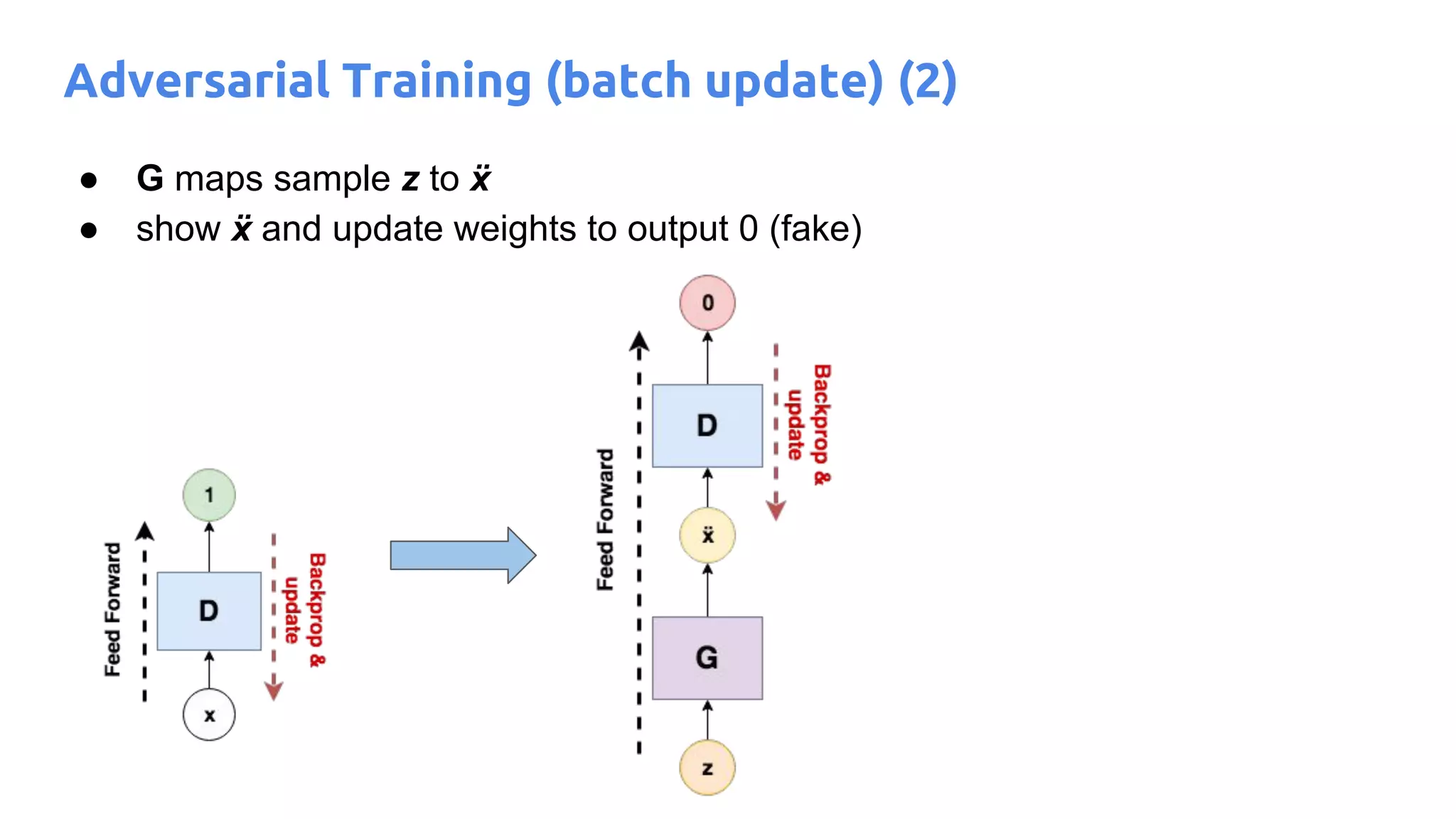
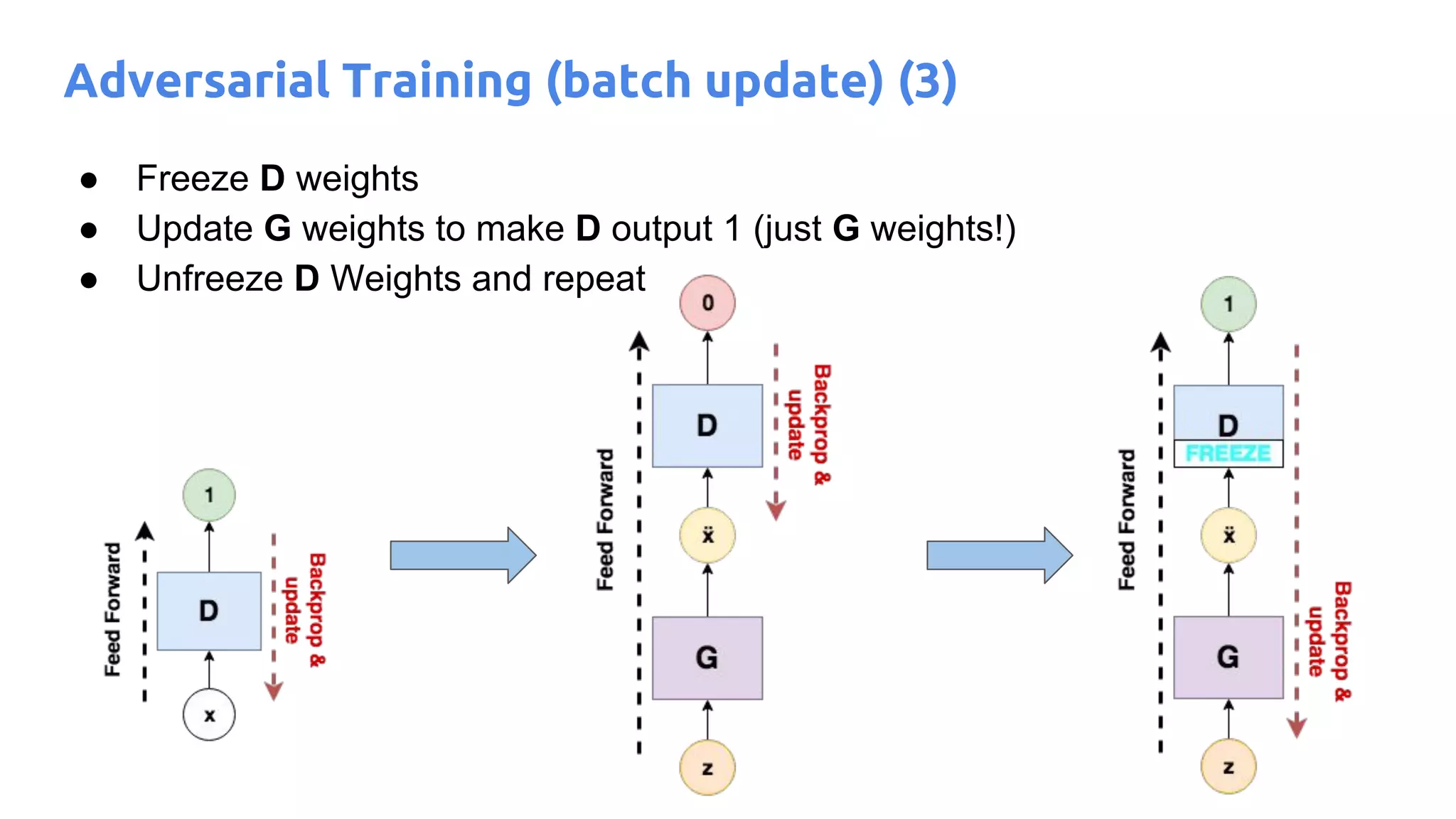











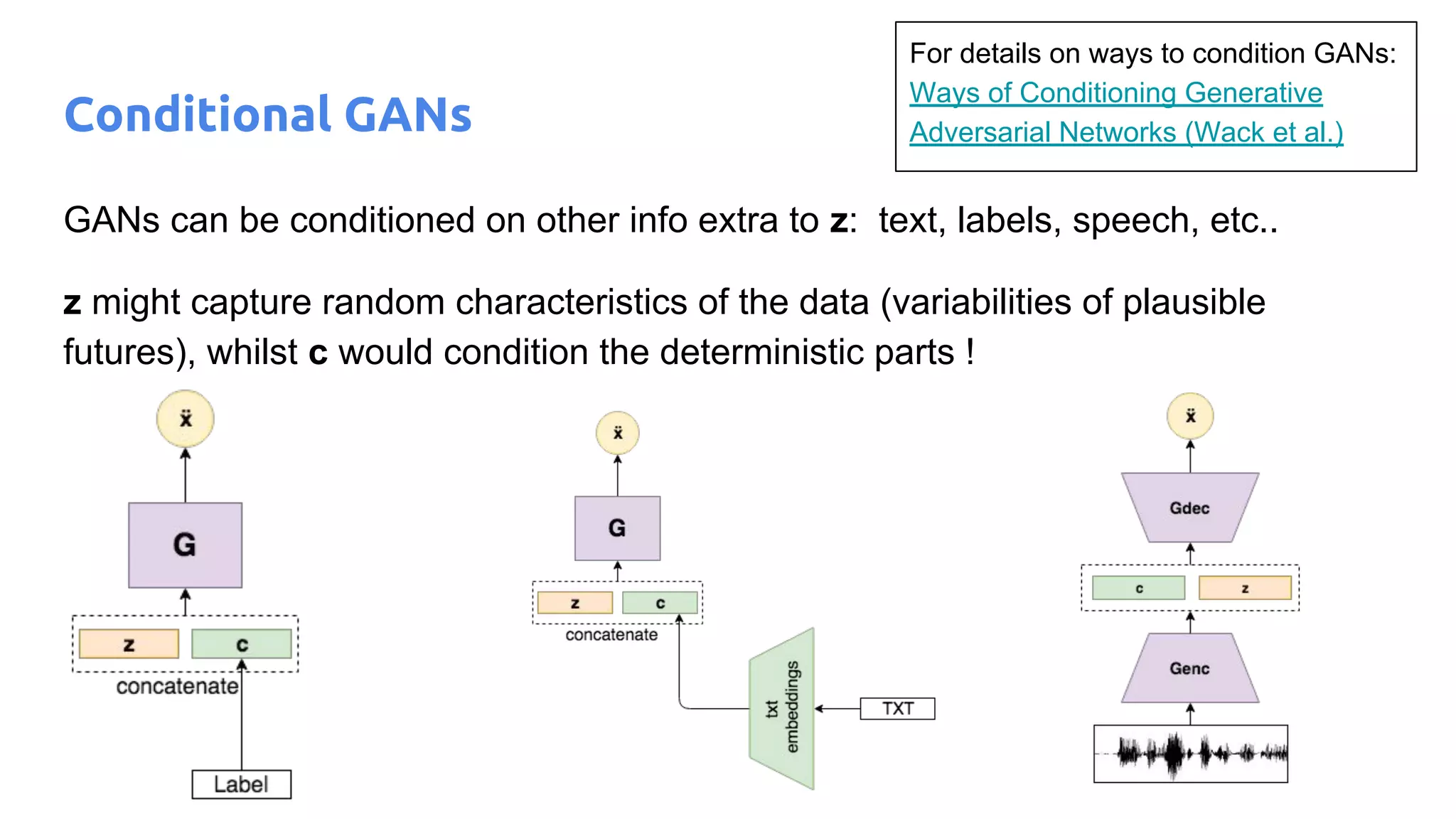





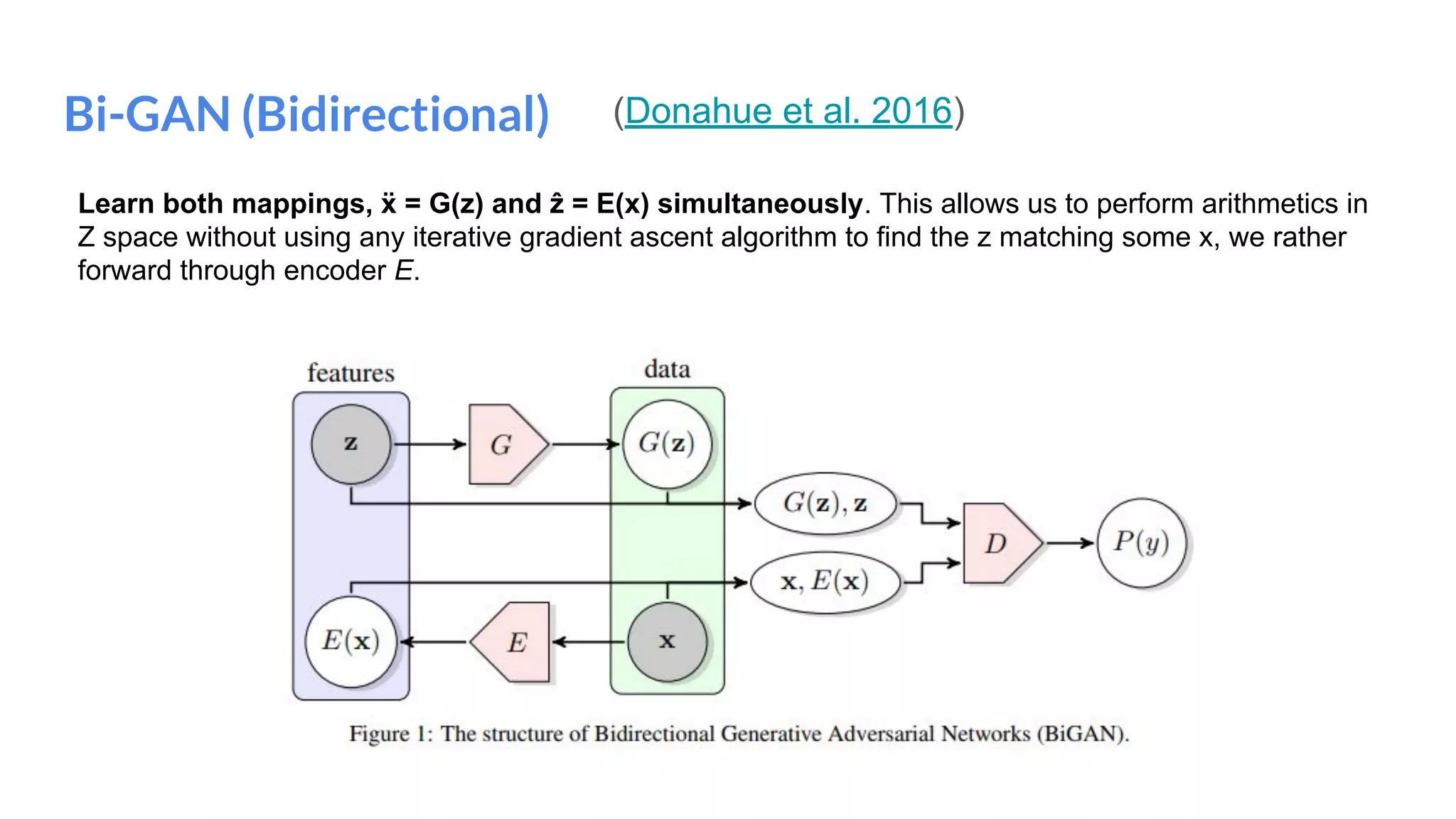
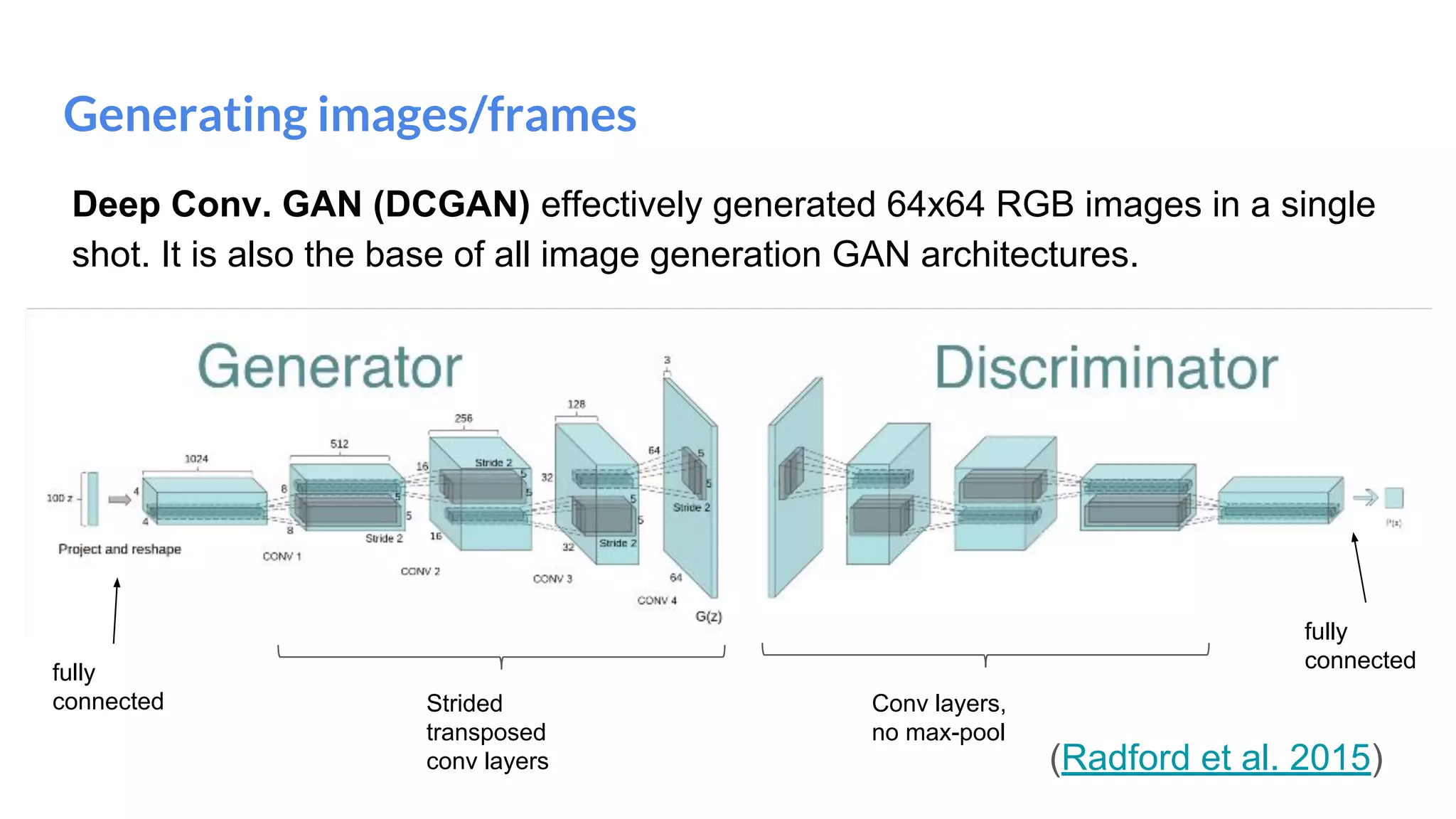

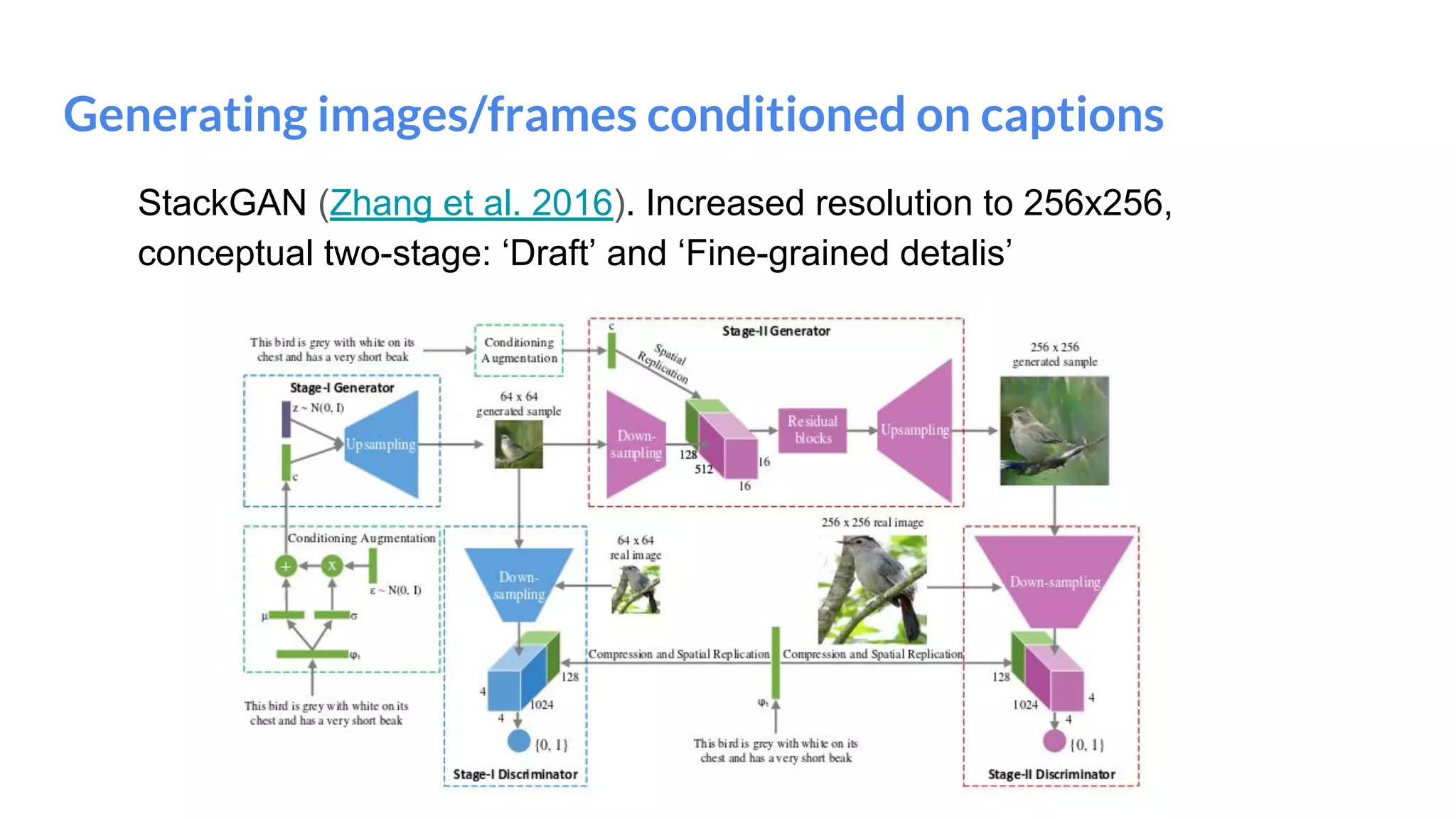



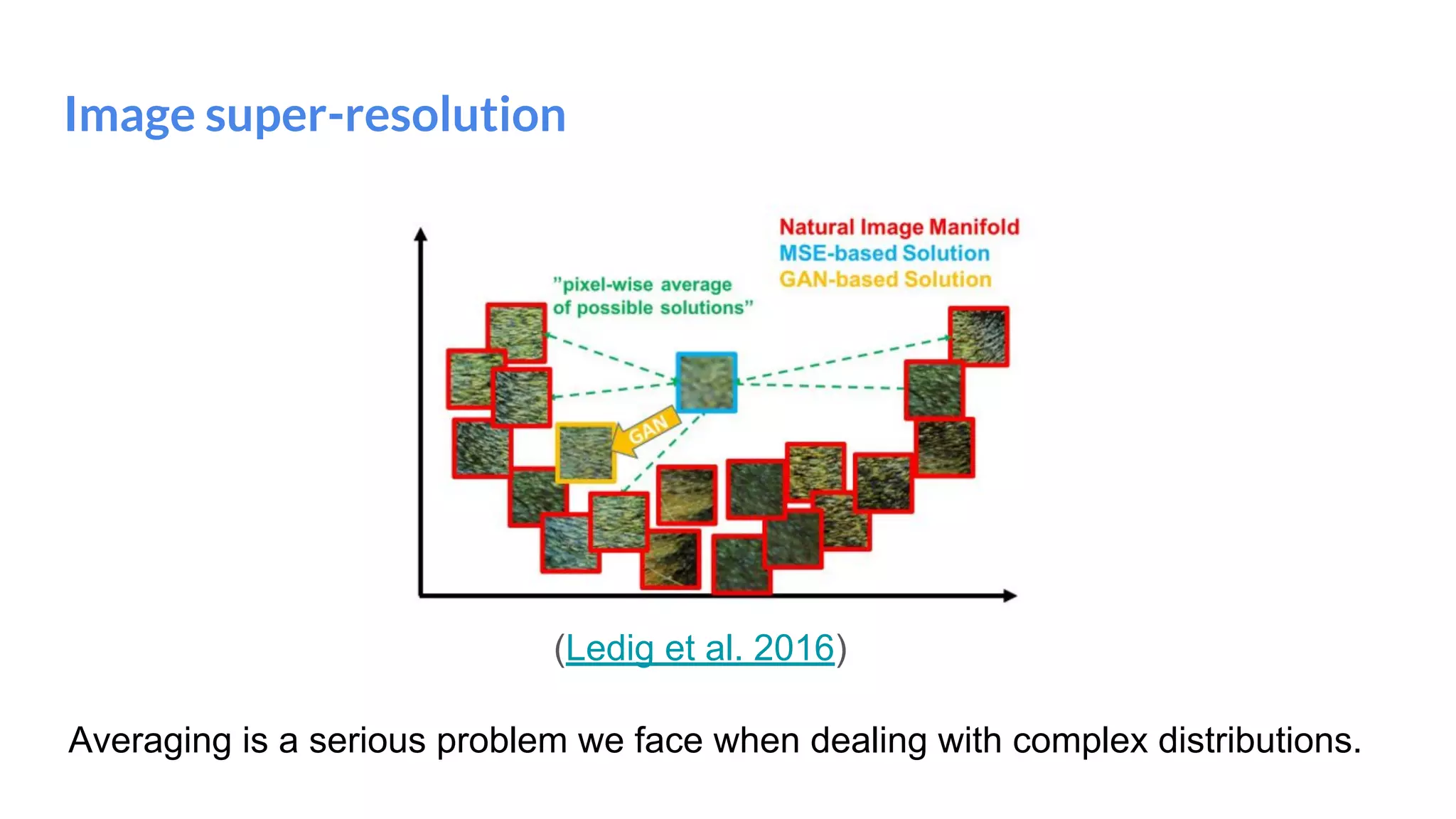

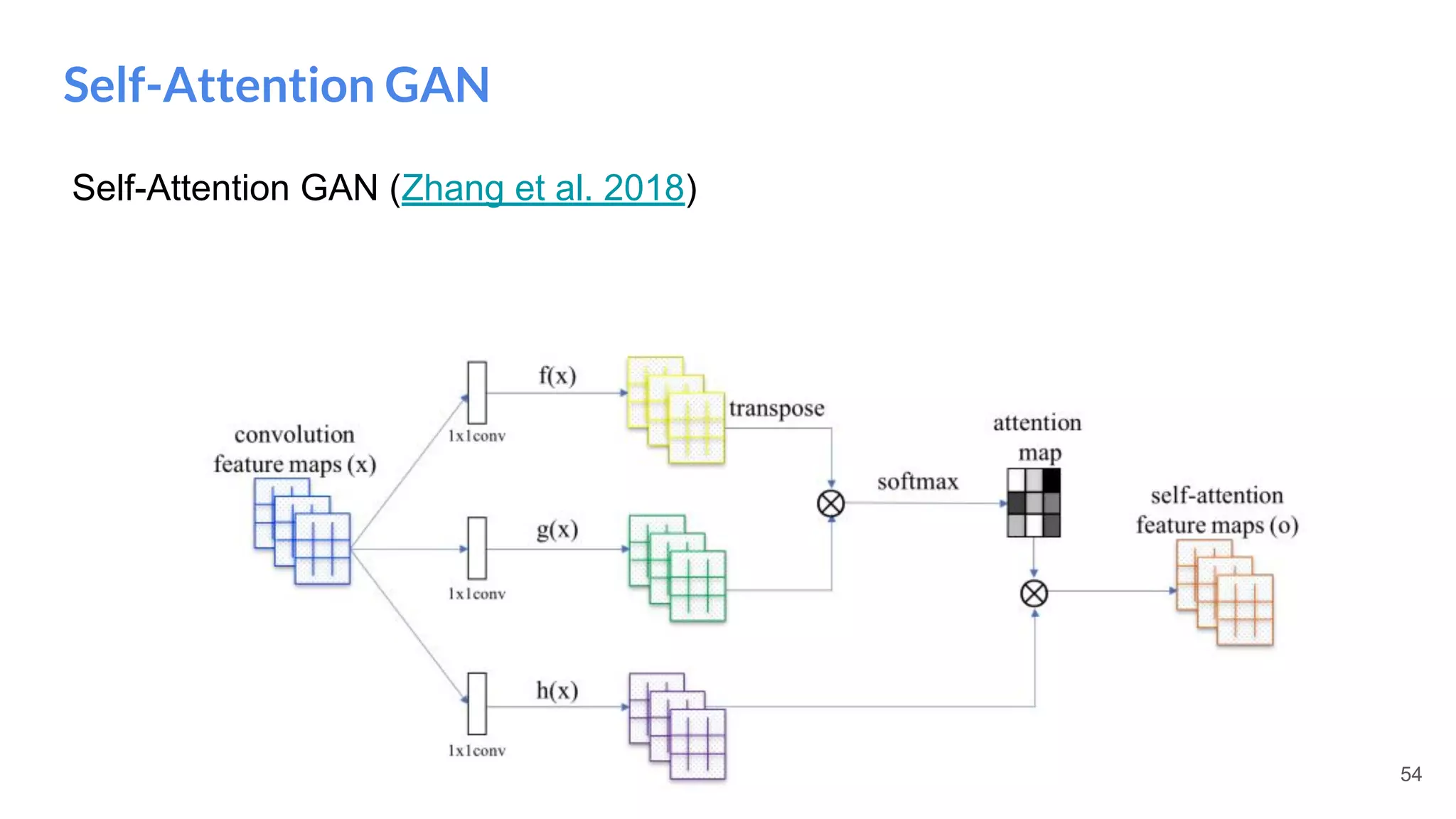


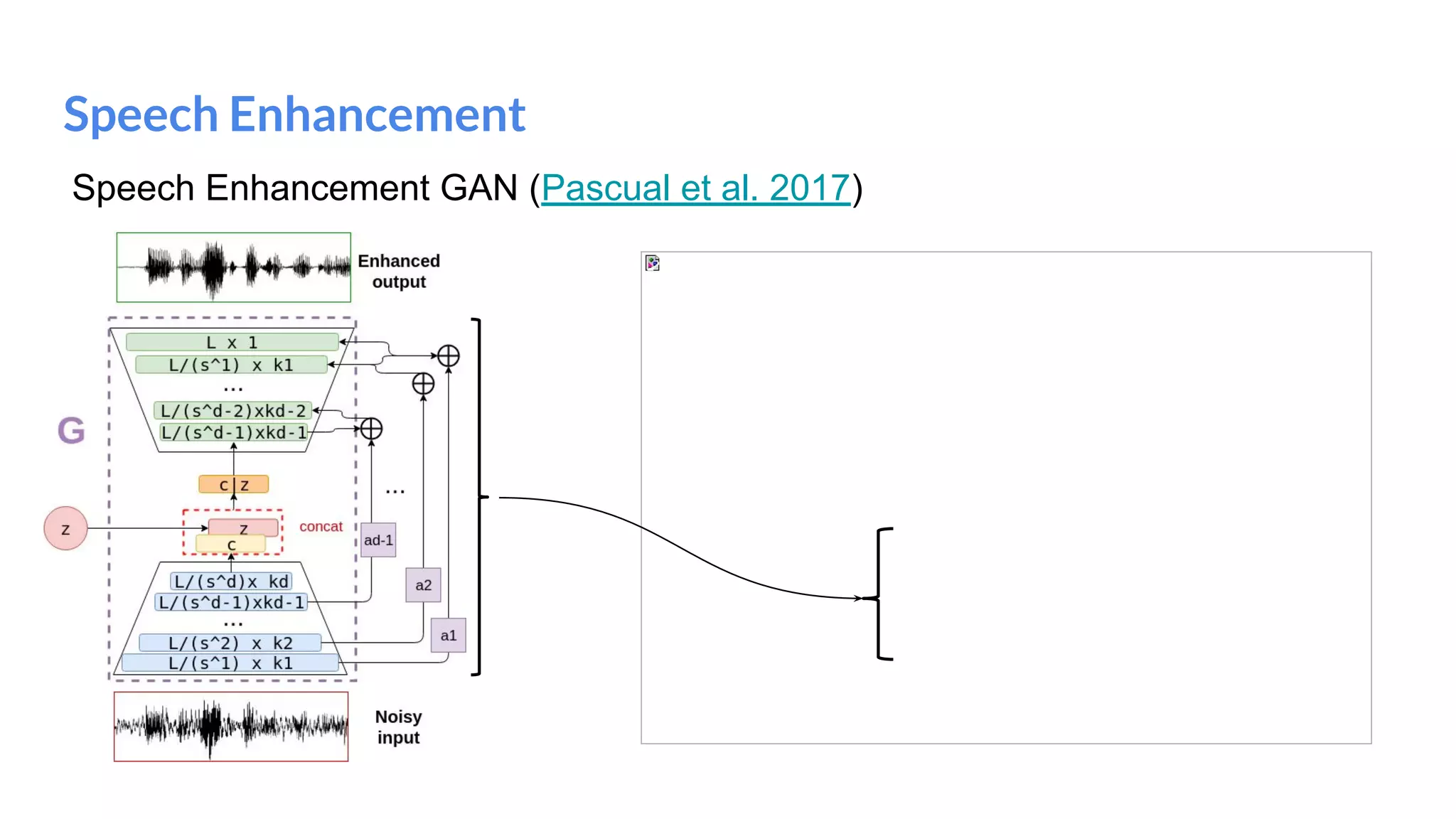
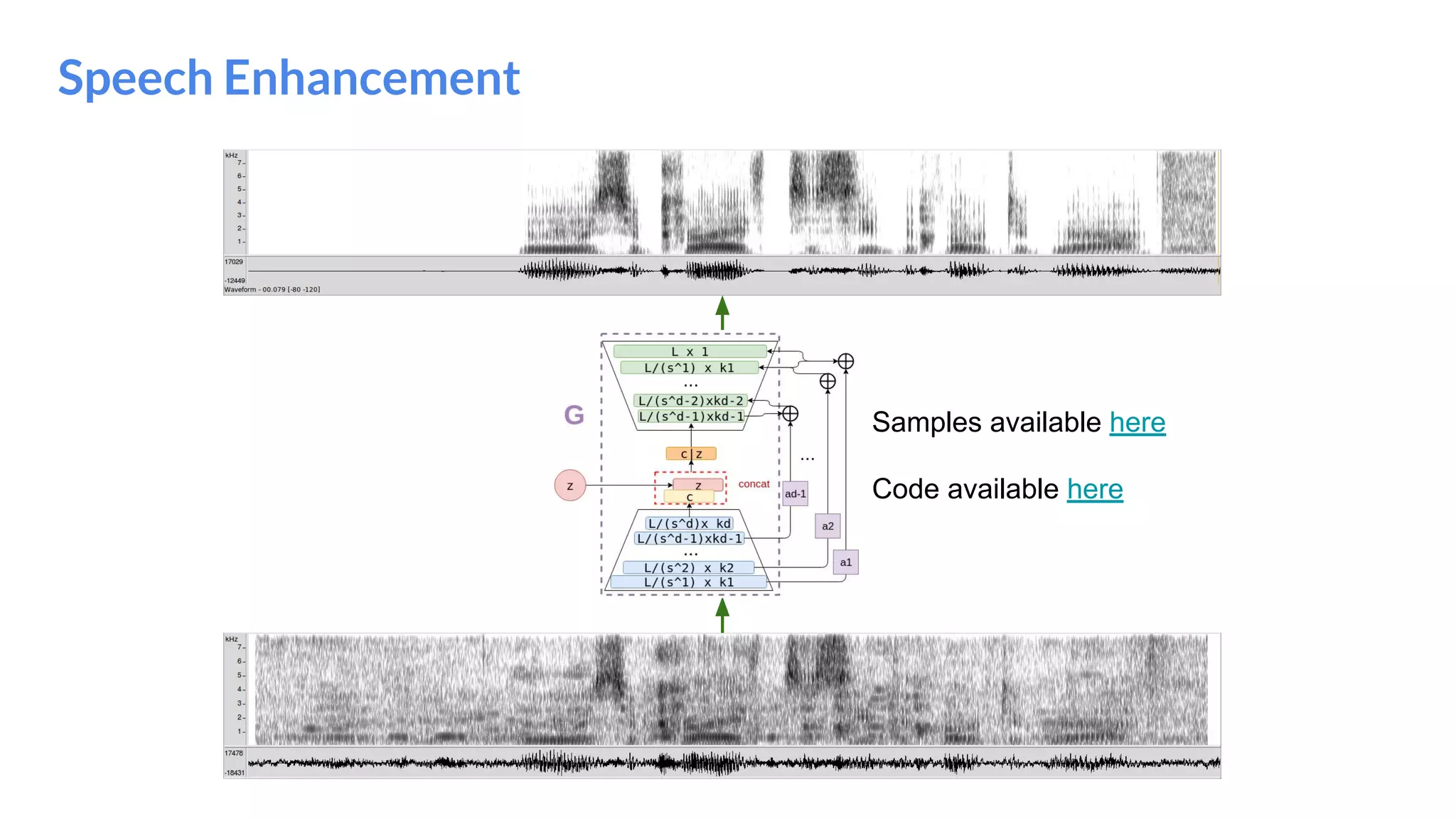



The document presents an overview of deep generative models, focusing on variational auto-encoders (VAEs) and generative adversarial networks (GANs) as key architectures. It provides a taxonomy of generative models, explaining how they learn data distributions and the dynamics of adversarial training between generator and discriminator networks. The document also discusses various implementations, challenges in training GANs, and advancements in generating high-quality images and other data types.


































































![[DSC Europe 25] Bassam Maharmeh - Artificial Intelligence: Opportunities and ...](https://cdn.slidesharecdn.com/ss_thumbnails/thhfmr2fqpawzj7hsjpg-5-251211083048-2c23204f-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DSC Europe 25] Danica Soc - The Science Behind Marketing: Experimentation me...](https://cdn.slidesharecdn.com/ss_thumbnails/c0nofsggs9gw5ucmallr-3-251216103155-56bd64d1-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DSC Europe 25] Debmalya Biswas - Agentification: the art of transforming man...](https://cdn.slidesharecdn.com/ss_thumbnails/r5azlggvtqiaiiusrqdr-4-251212103249-5a12c89b-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DSC Europe 25] Uros Pesic - The Reality of AI in Marketing.pdf](https://cdn.slidesharecdn.com/ss_thumbnails/rtkodnmtycovsllvzsyn-9-251215095918-b0c6bfe3-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DSC Europe 25] Branko Dzakula - From Defense to Attack: How AI Redefines Cyb...](https://cdn.slidesharecdn.com/ss_thumbnails/80bdzdxpr3ky2g0qvyk9-8-251211083048-ce5fc1ee-thumbnail.jpg?width=640&height=640&fit=bounds)




