Downloaded 41 times
![[course
site]
Verónica Vilaplana
veronica.vilaplana@upc.edu
Associate Professor
Universitat Politecnica de Catalunya
Technical University of Catalonia
Convolutional Neural
Networks
Day 5 Lecture 1
#DLUPC](https://image.slidesharecdn.com/dlailayerscnn-171101161900/85/Convolutional-Neural-Networks-DLAI-D5L1-2017-UPC-Deep-Learning-for-Artificial-Intelligence-1-320.jpg)
![[course
site]
Verónica Vilaplana
veronica.vilaplana@upc.edu
Associate Professor
Universitat Politecnica de Catalunya
Technical University of Catalonia
Convolutional Neural
Networks
Day 5 Lecture 1
#DLUPC](https://image.slidesharecdn.com/dlailayerscnn-171101161900/75/Convolutional-Neural-Networks-DLAI-D5L1-2017-UPC-Deep-Learning-for-Artificial-Intelligence-1-2048.jpg)



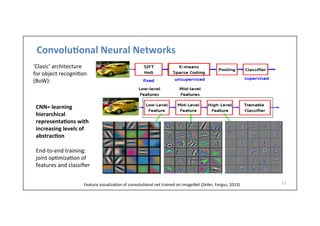
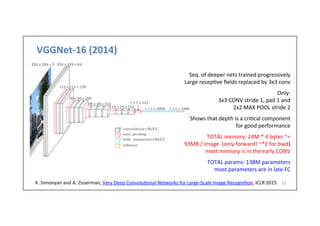
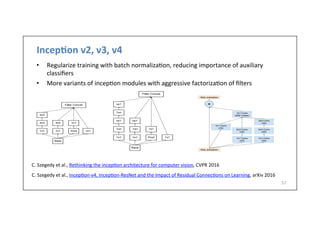
![Example:
LeNet-‐5
13
• LeCun
et
al.,
1998
MNIST
digit
classifica-on
problem
handwrilen
digits
60,000
training
examples
10,000
test
samples
10
classes
28x28
grayscale
images
Y.
LeCun,
L.
Bolou,
Y.
Bengio,
and
P.
Haffner,
Gradient-‐based
learning
applied
to
document
recogni-on,
Proc.
IEEE
86(11):
2278–2324,
1998.
Conv
filters
were
5x5,
applied
at
stride
1
Sigmoid
or
tanh
nonlinearity
Subsampling
(average
pooling)
layers
were
2x2
applied
at
stride
2
Fully
connected
layers
at
the
end
i.e.
architecture
is
[CONV-‐POOL-‐CONV-‐POOL-‐CONV-‐FC]](https://image.slidesharecdn.com/dlailayerscnn-171101161900/85/Convolutional-Neural-Networks-DLAI-D5L1-2017-UPC-Deep-Learning-for-Artificial-Intelligence-13-320.jpg)

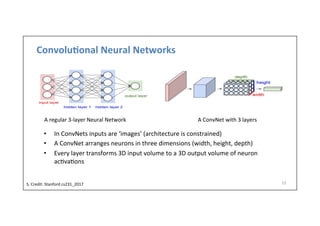










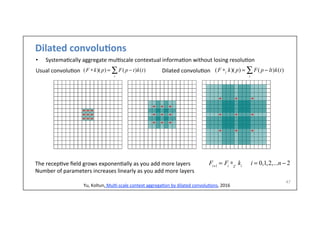



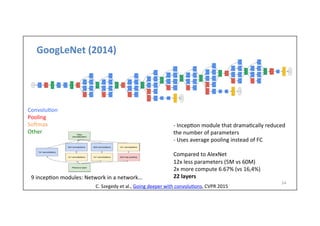
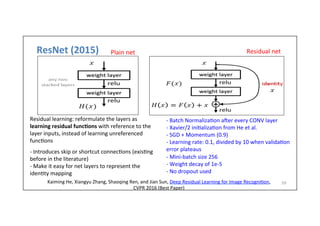
![AlexNet
(2012)
51
Full
AlexNet
architecture:
8
layers
[227x227x3]
INPUT
[55x55x96]
CONV1:
96
11x11
filters
at
stride
4,
pad
0
[27x27x96]
MAX
POOL1:
3x3
filters
at
stride
2
[27x27x96]
NORM1:
Normaliza-on
layer
[27x27x256]
CONV2:
256
5x5
filters
at
stride
1,
pad
2
[13x13x256]
MAX
POOL2:
3x3
filters
at
stride
2
[13x13x256]
NORM2:
Normaliza-on
layer
[13x13x384]
CONV3:
384
3x3
filters
at
stride
1,
pad
1
[13x13x384]
CONV4:
384
3x3
filters
at
stride
1,
pad
1
[13x13x256]
CONV5:
256
3x3
filters
at
stride
1,
pad
1
[6x6x256]
MAX
POOL3:
3x3
filters
at
stride
2
[4096]
FC6:
4096
neurons
[4096]
FC7:
4096
neurons
[1000]
FC8:
1000
neurons
(class
scores)
Details/Retrospec)ves:
-‐
first
use
of
ReLU
-‐
used
Norm
layers
(not
common)
-‐
heavy
data
augmenta-on
-‐
dropout
0.5
-‐
batch
size
128
-‐
SGD
Momentum
0.9
-‐
Learning
rate
1e-‐2,
reduced
by
10
manually
when
val
accuracy
plateaus
-‐
L2
weight
decay
5e-‐4
ILSVRC
2012
winner
7
CNN
ensemble:
18.2%
-‐>
15.4%](https://image.slidesharecdn.com/dlailayerscnn-171101161900/85/Convolutional-Neural-Networks-DLAI-D5L1-2017-UPC-Deep-Learning-for-Artificial-Intelligence-51-320.jpg)


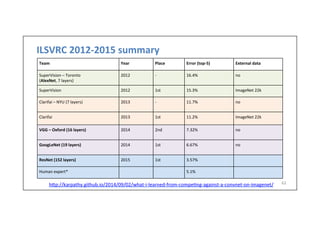


The document provides an in-depth overview of convolutional neural networks (CNNs), covering key concepts such as local connectivity, parameter sharing, and pooling. It outlines the architecture of CNNs, including the use of convolutional layers, pooling layers, and fully connected layers, along with various activation functions and techniques like batch normalization. The presentation also discusses the practical applications of CNNs for image recognition and segmentation, and the importance of hyperparameters in their design.