Download as PDF, PPTX
![Xavier Giro-i-Nieto
xavier.giro@upc.edu
Associate Professor
Universitat Politècnica de Catalunya
Technical University of Catalonia
Backpropagation
#DLUPC
[course site]](https://image.slidesharecdn.com/dlai2019d02l2backprop-191019170748/75/Backpropagation-for-Neural-Networks-1-2048.jpg)


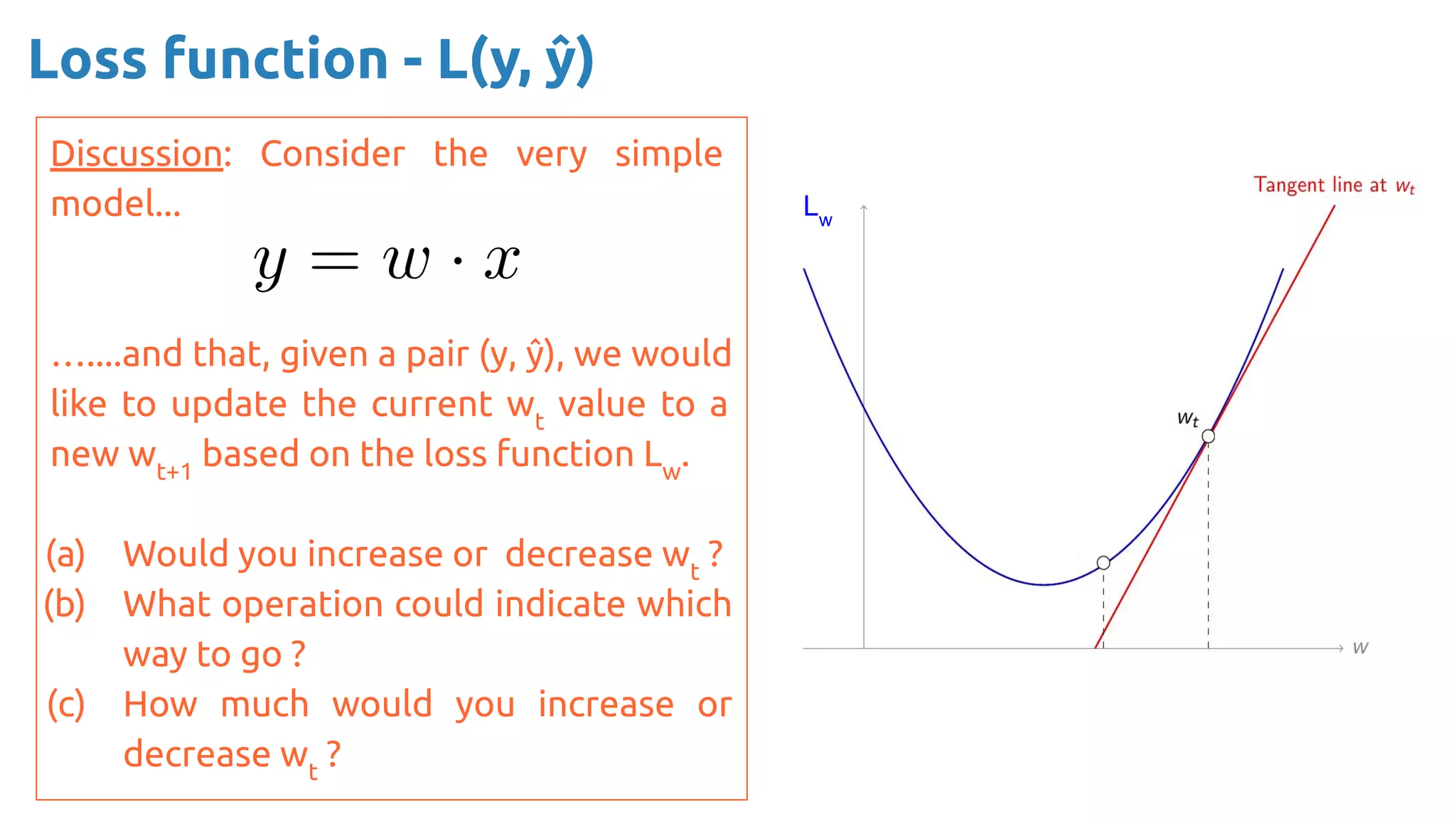
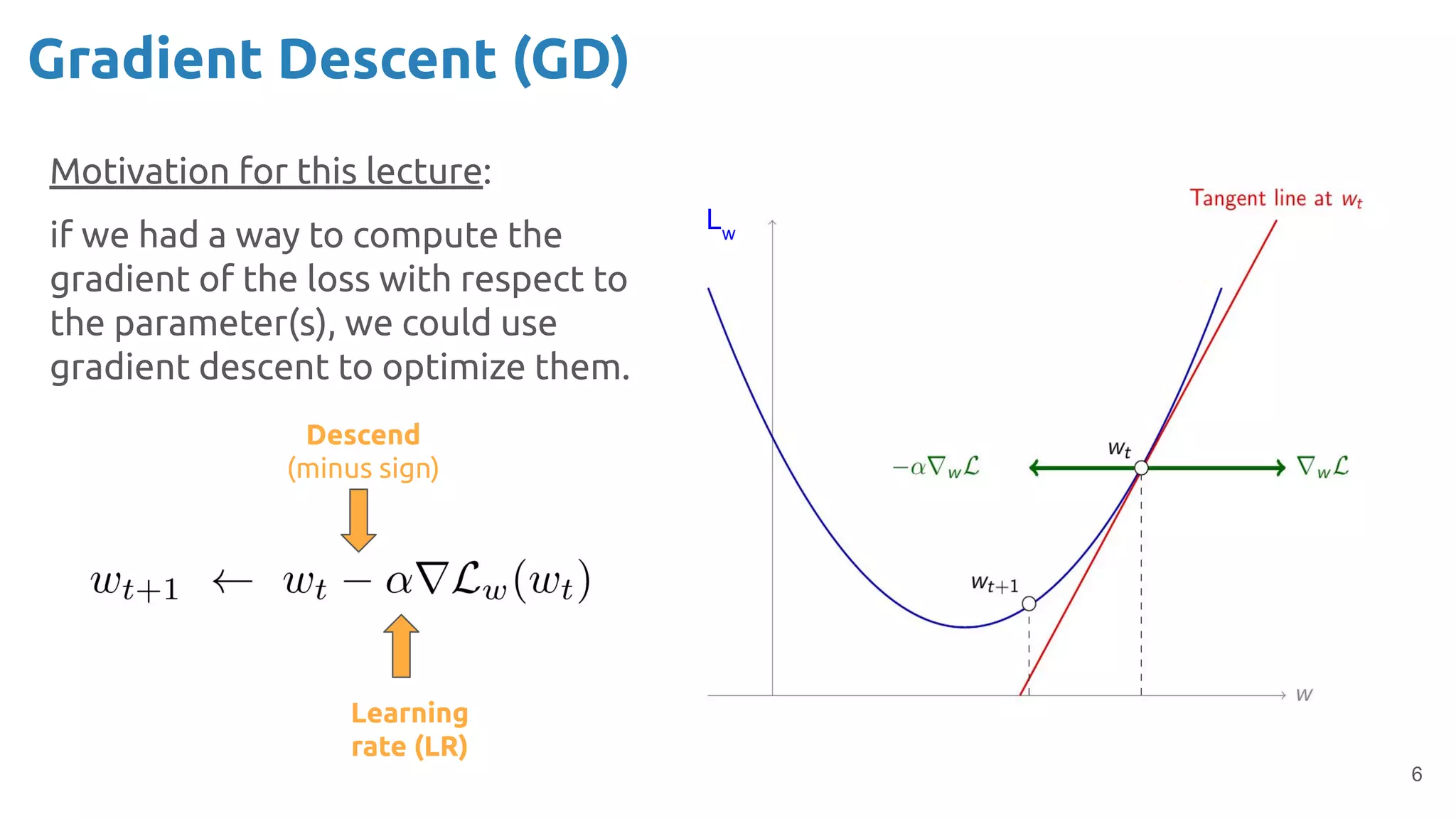


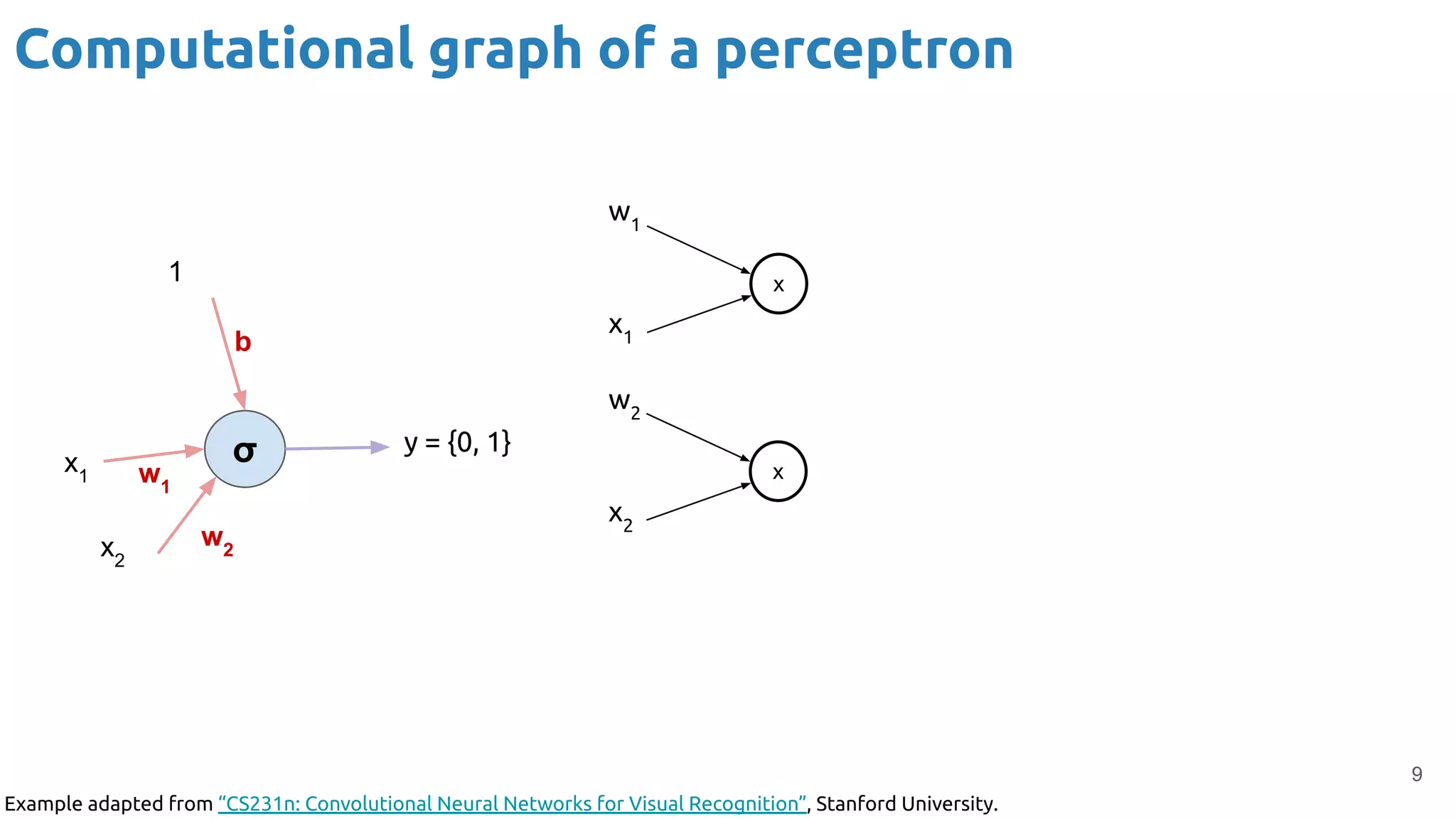
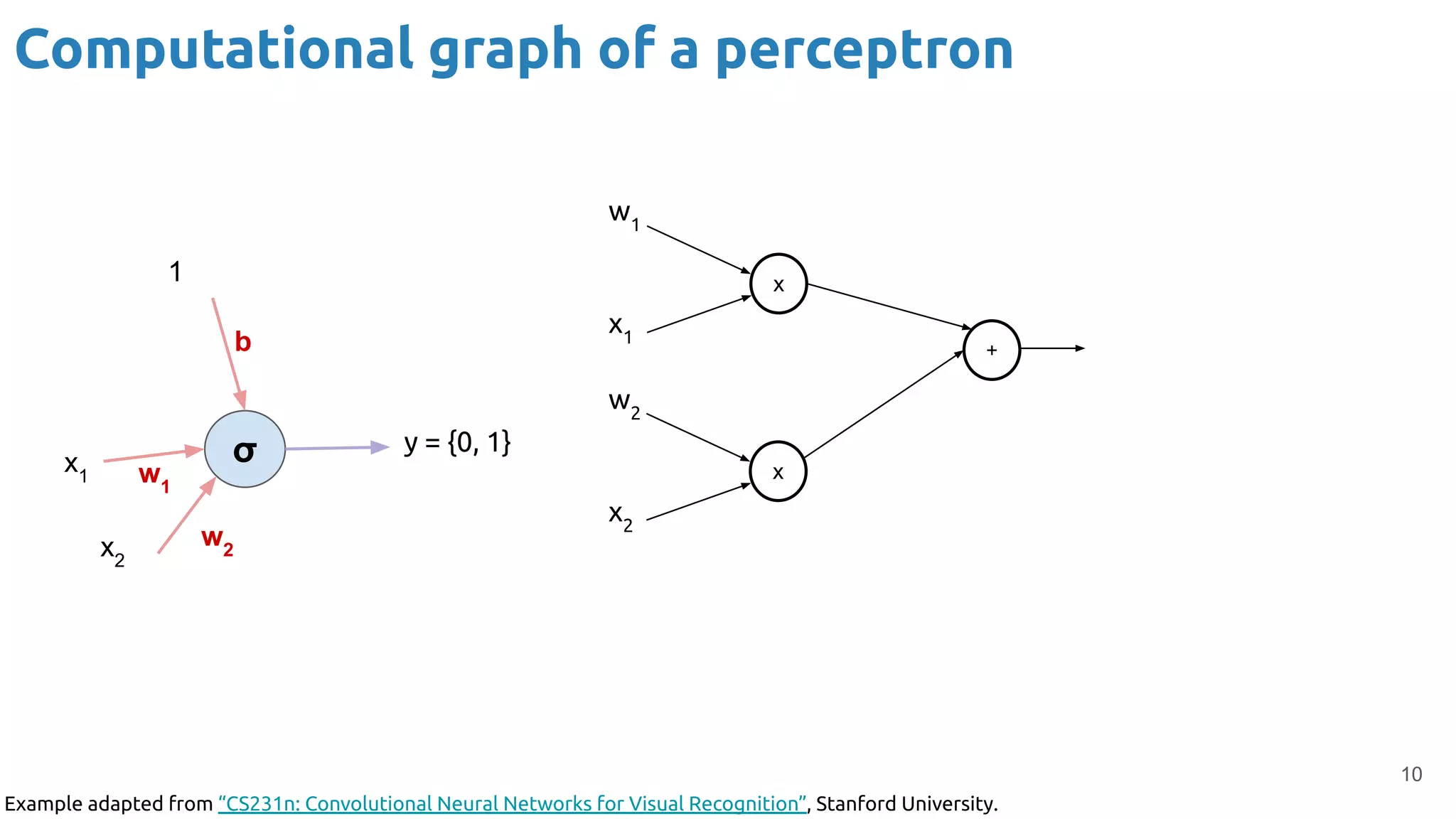
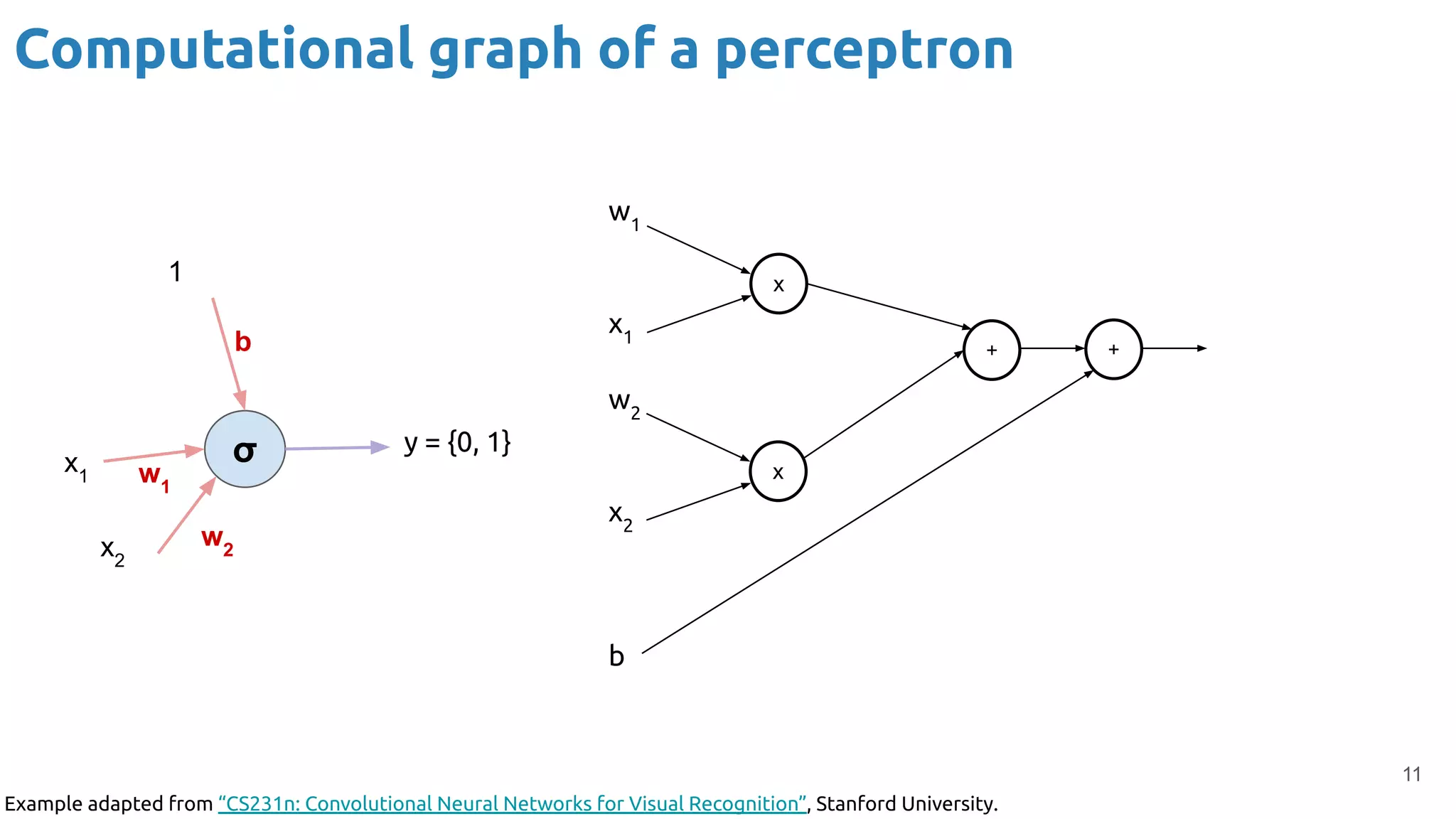
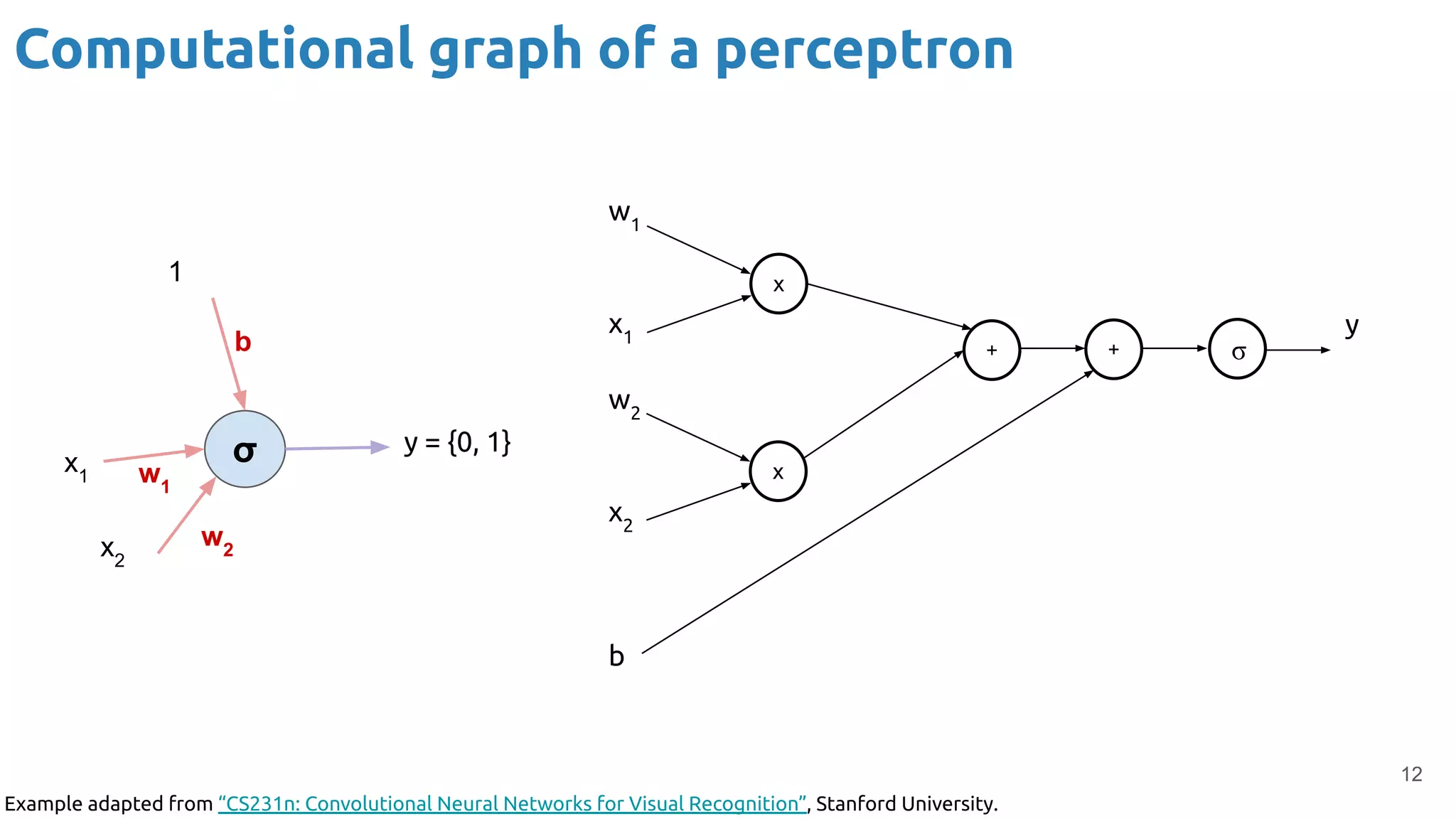
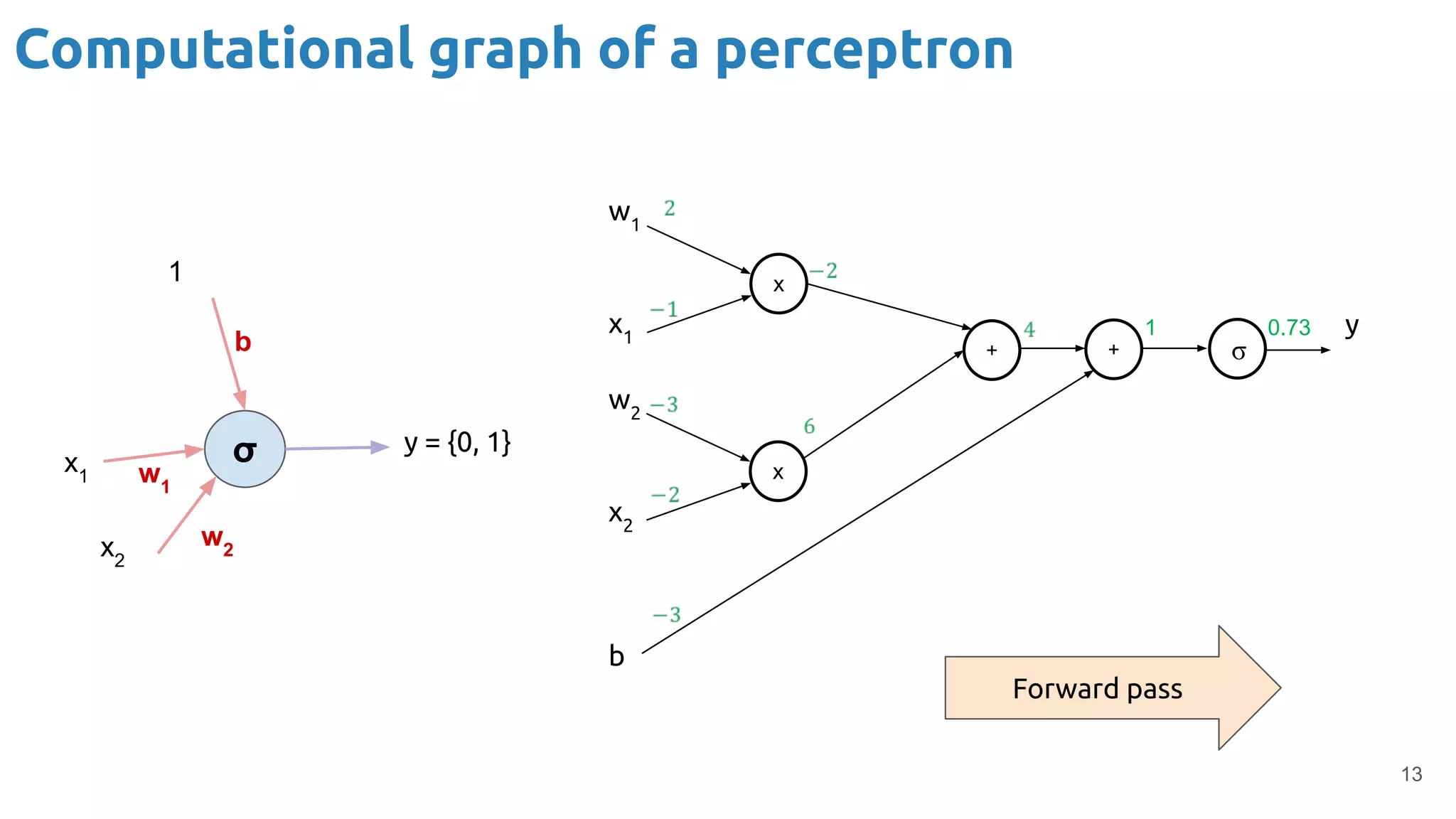
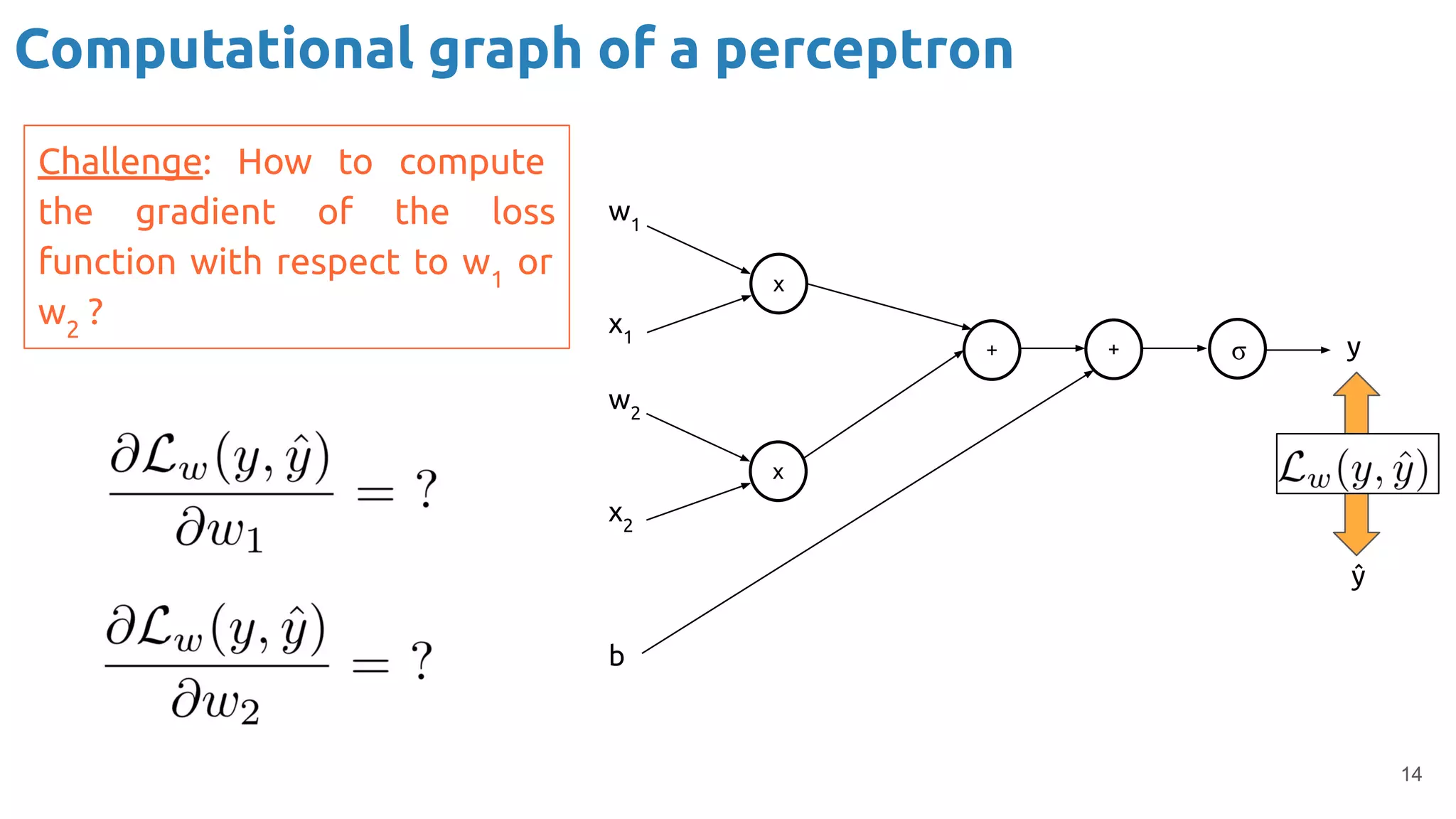

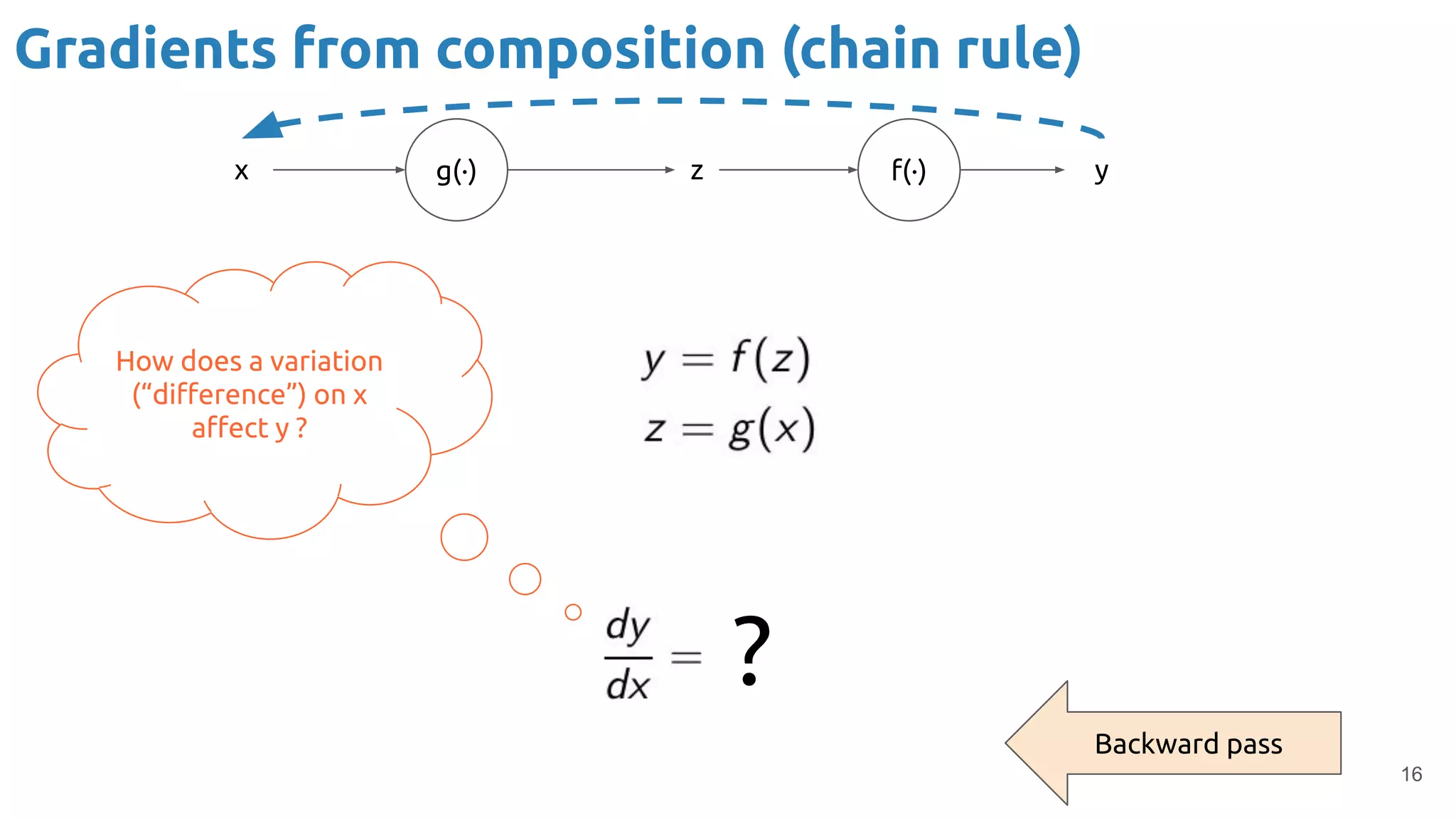
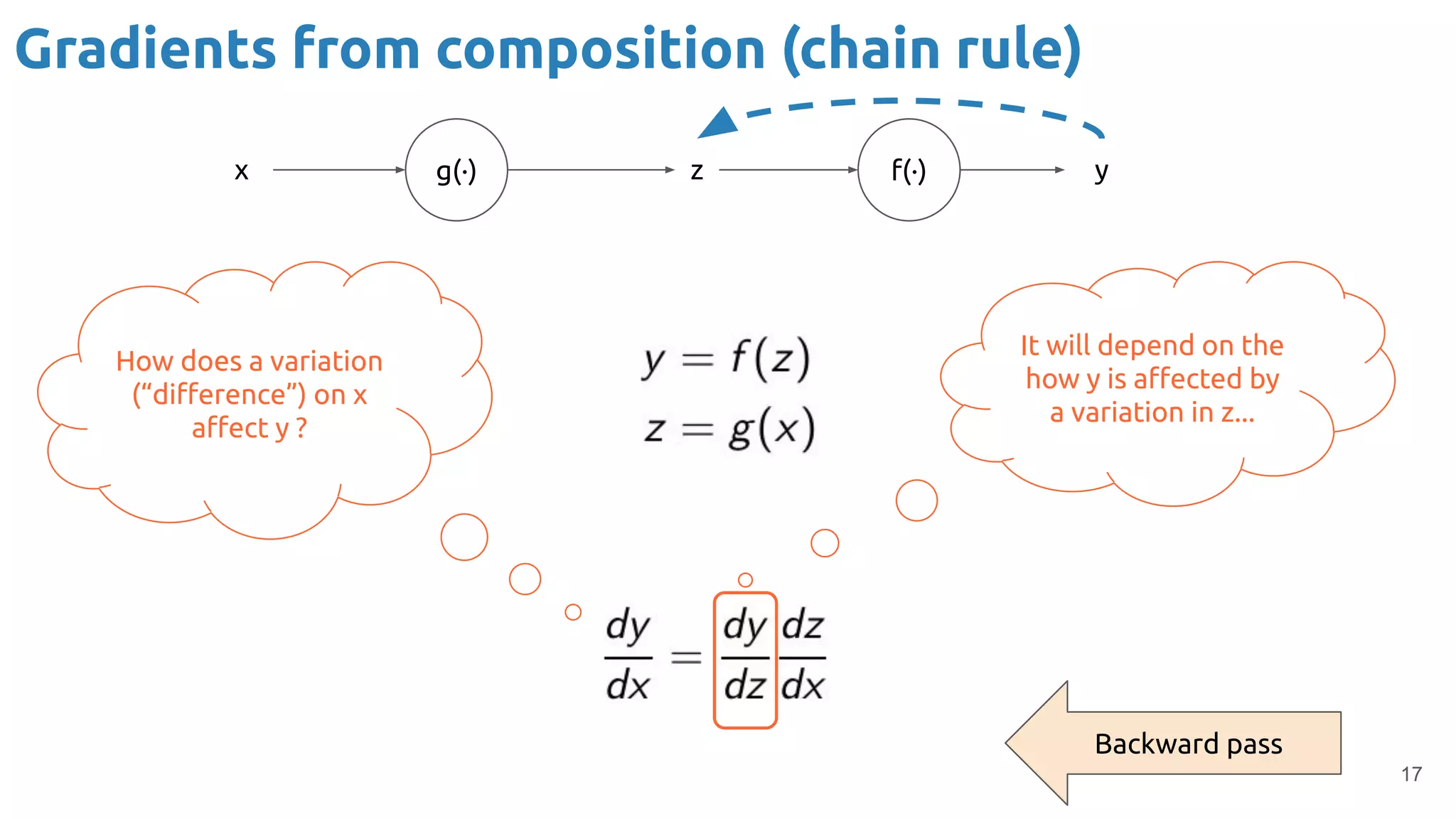
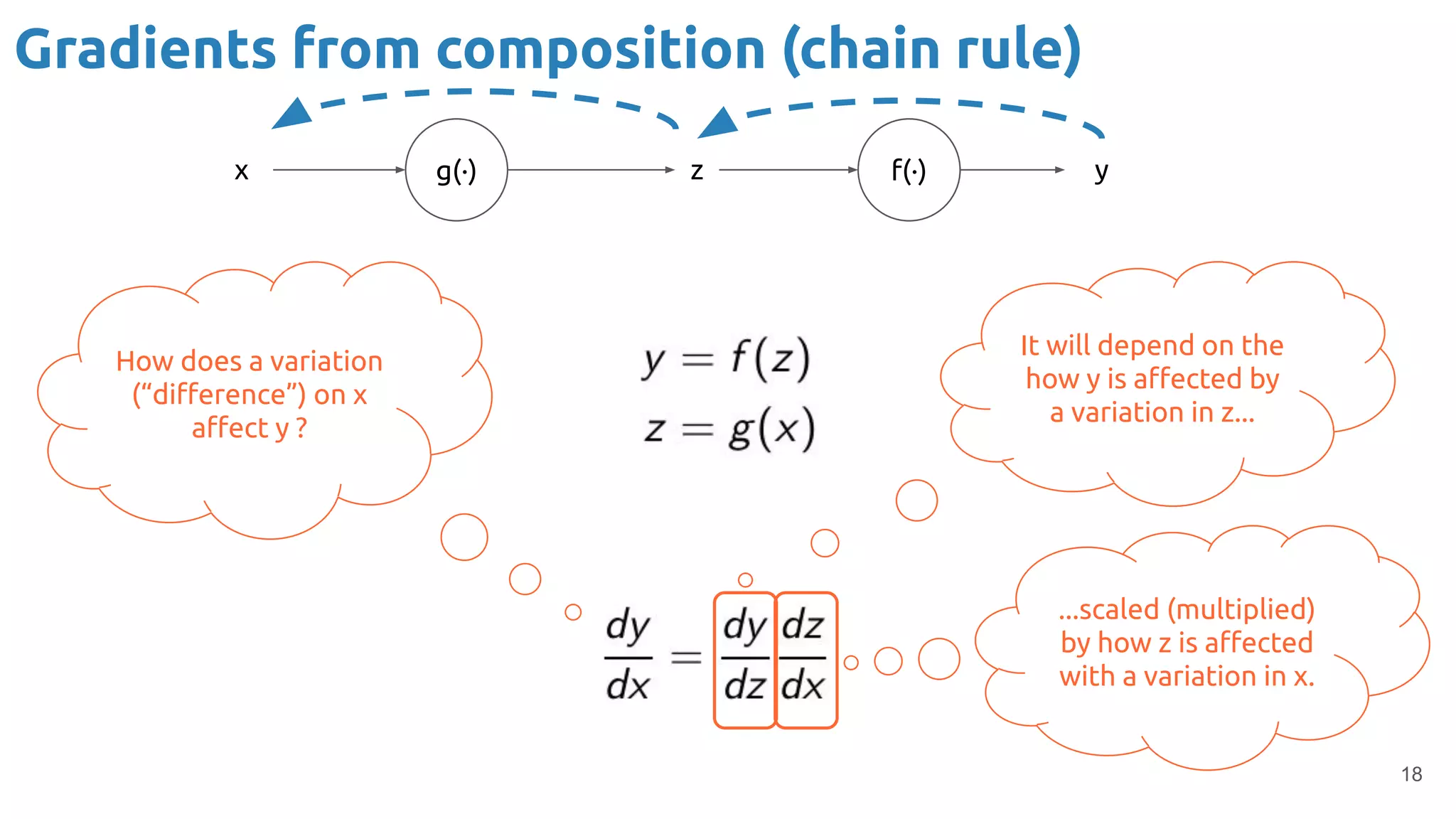

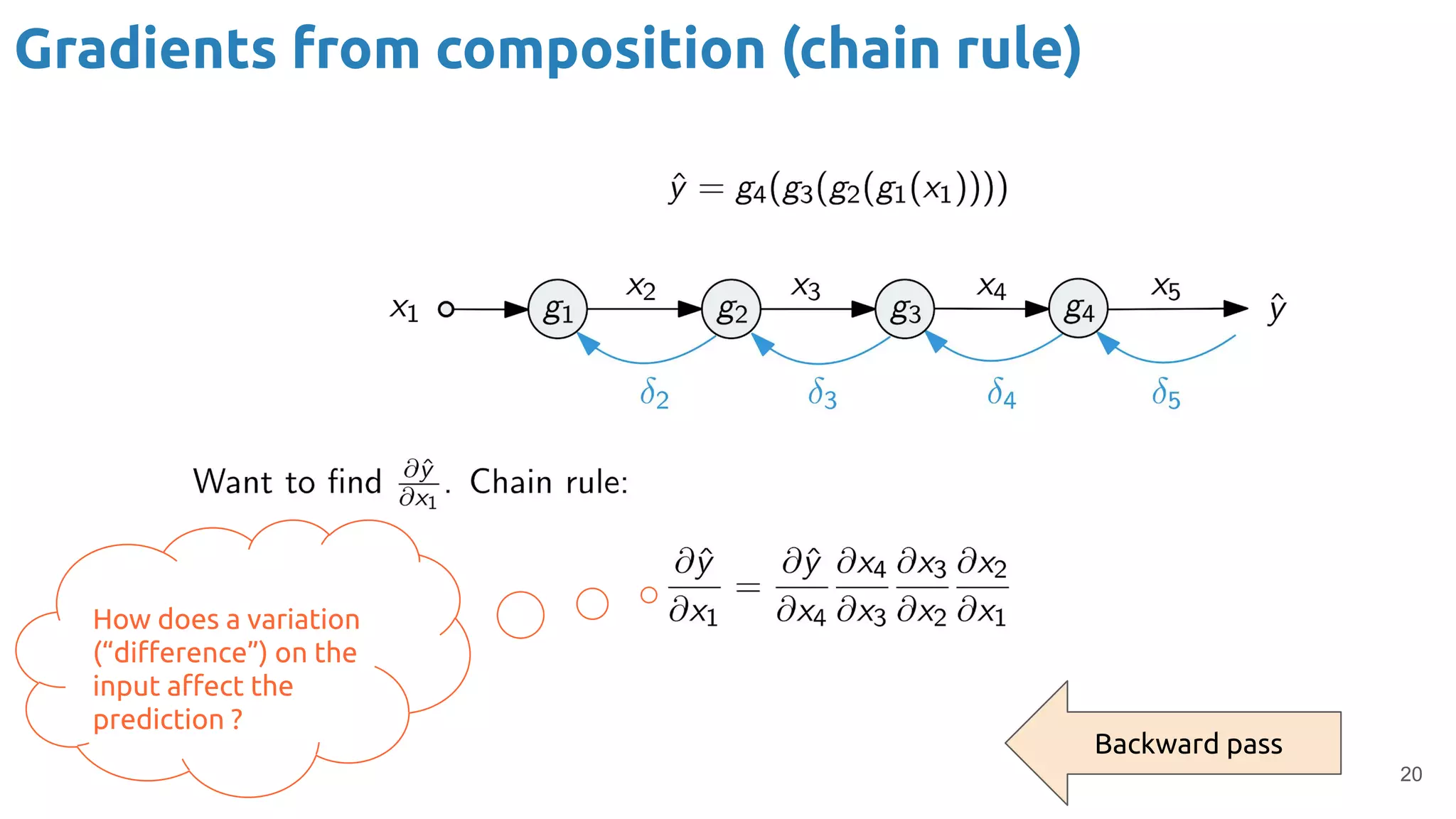
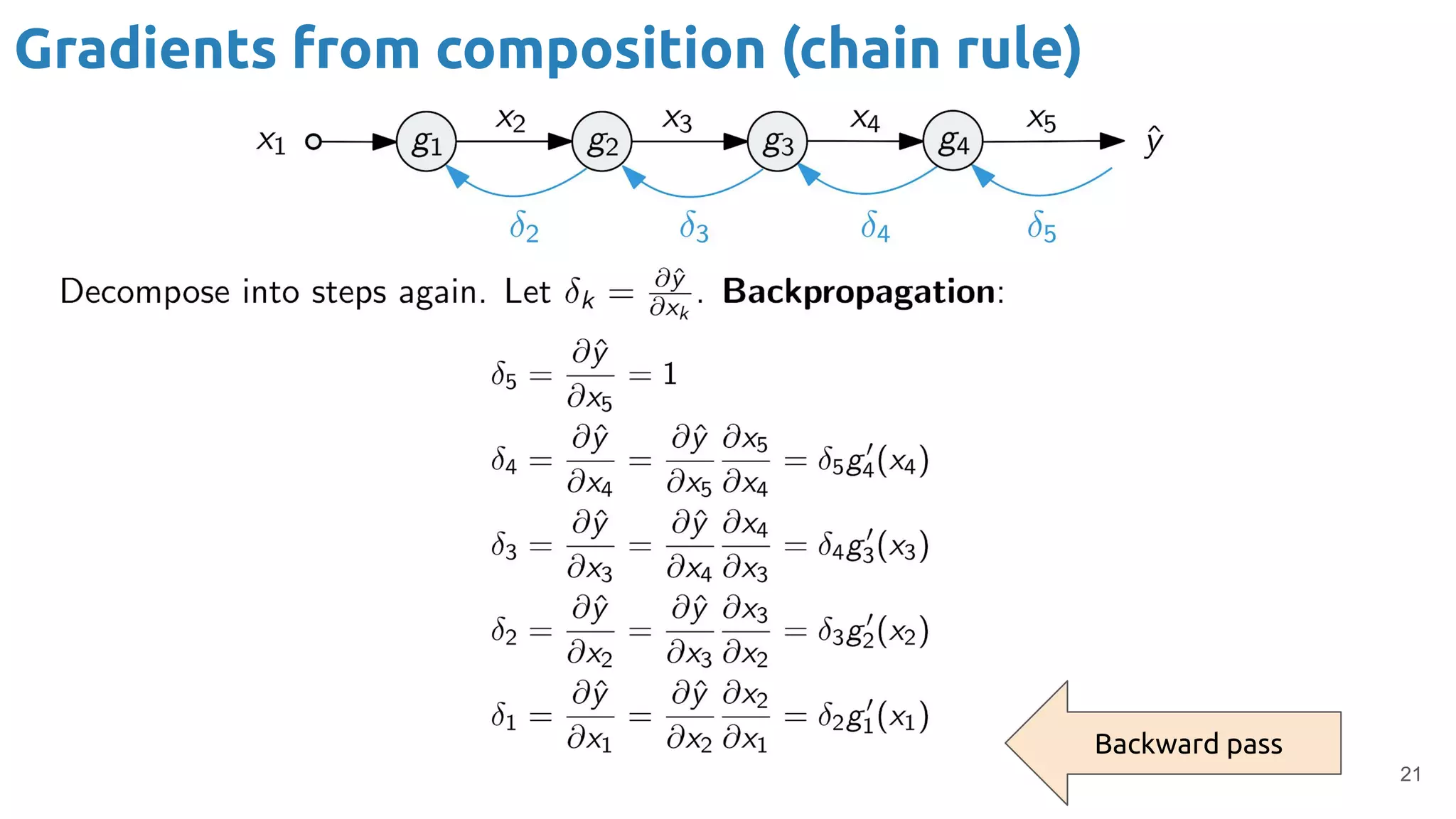
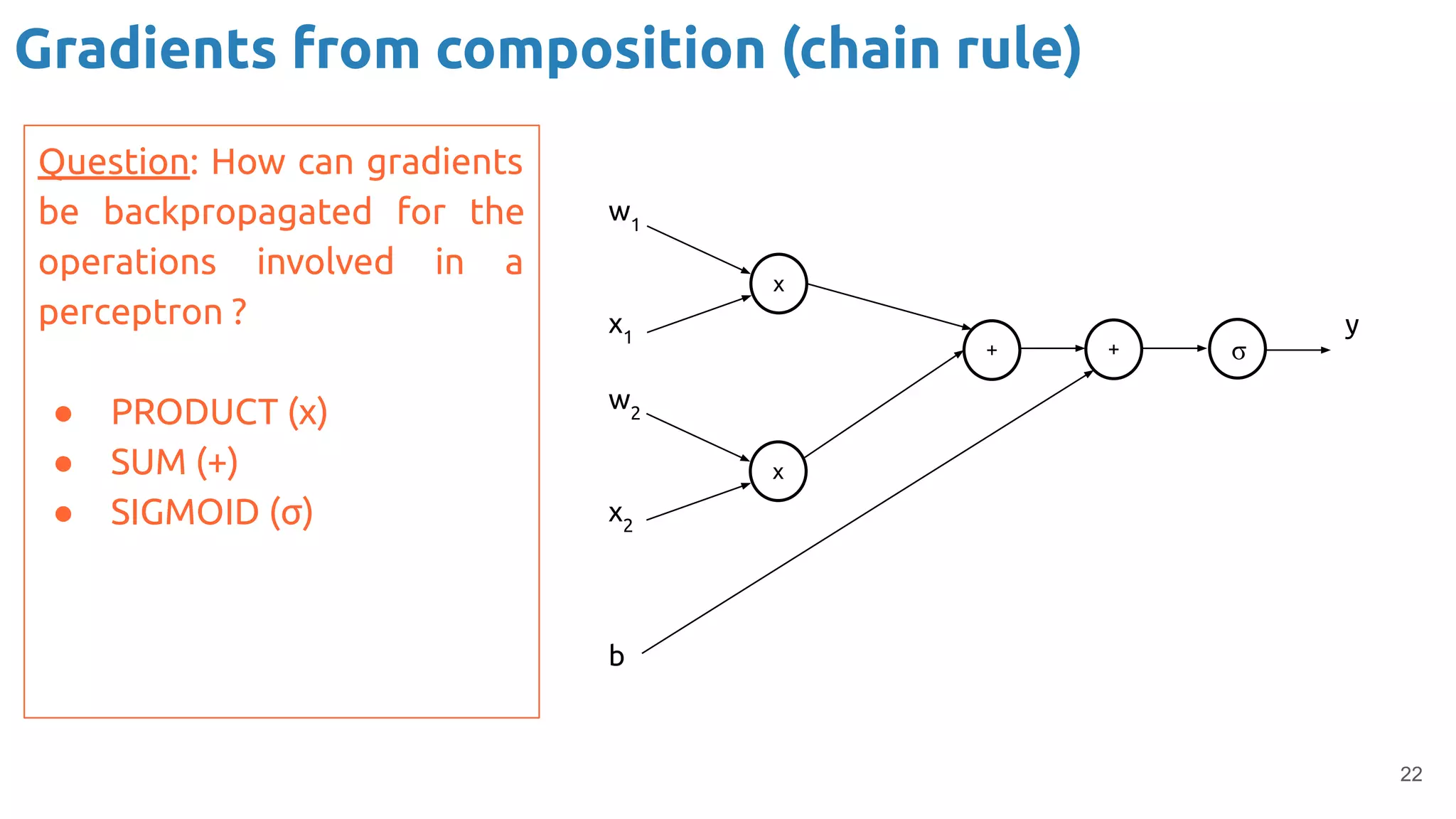
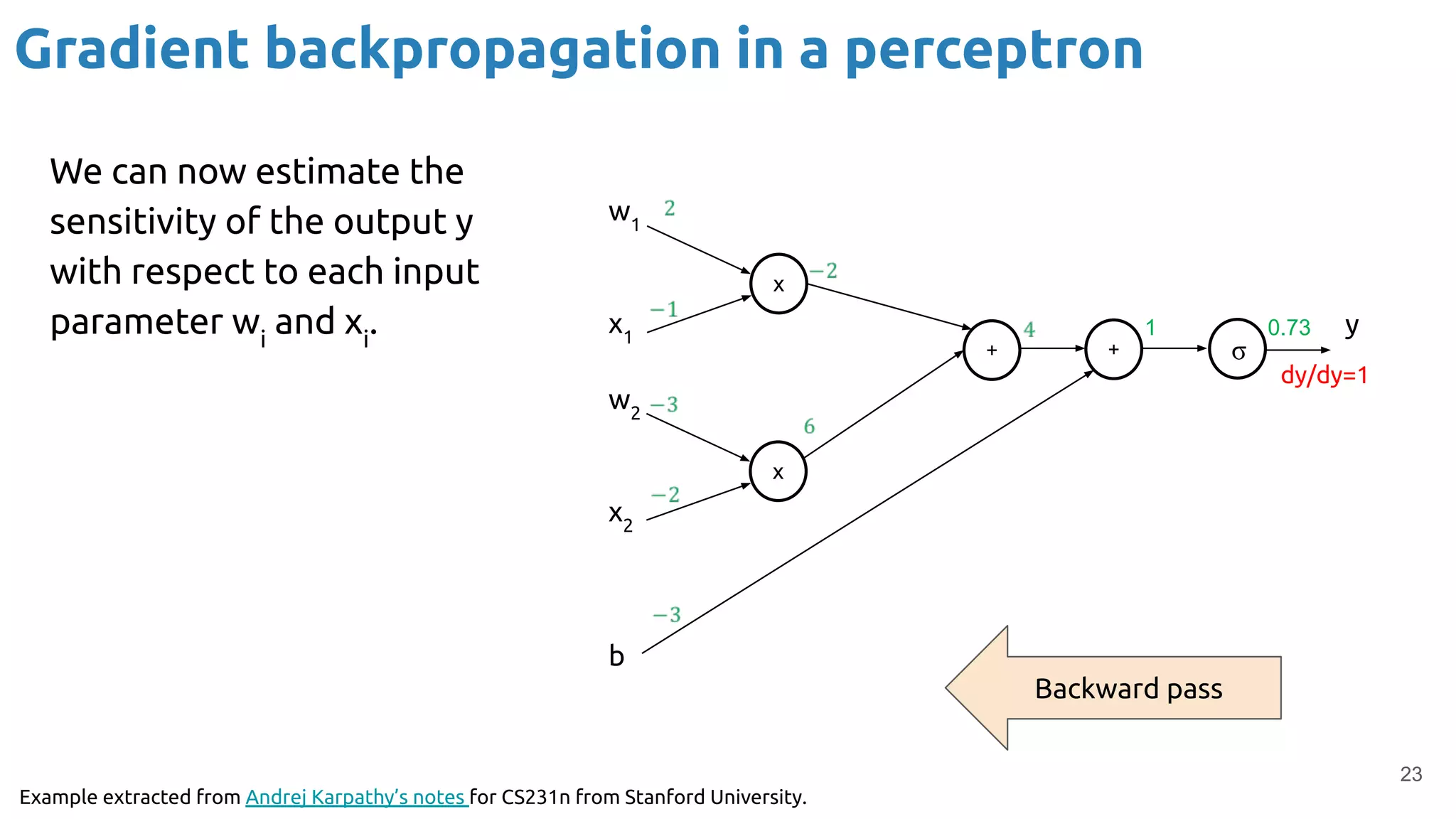

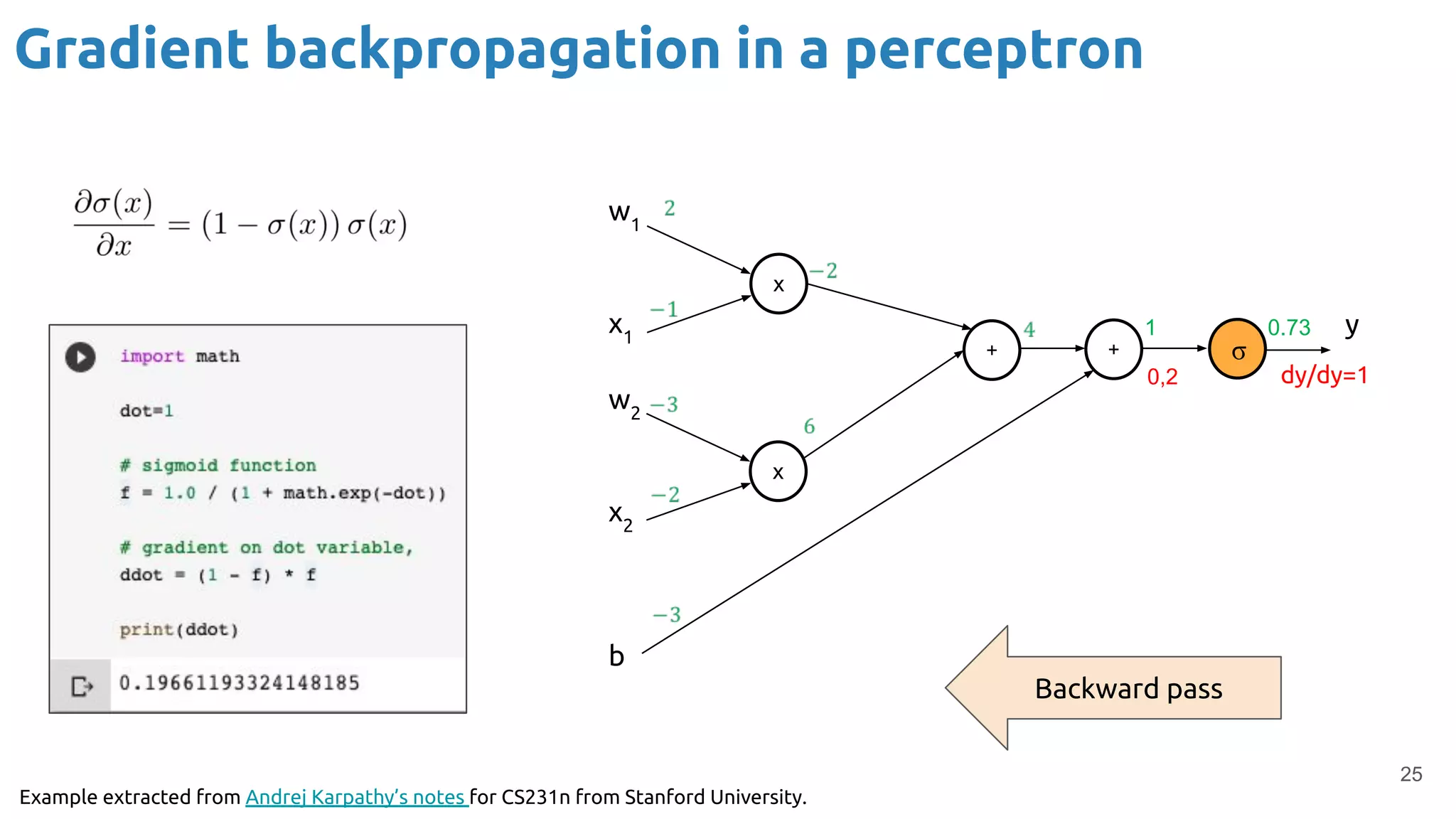
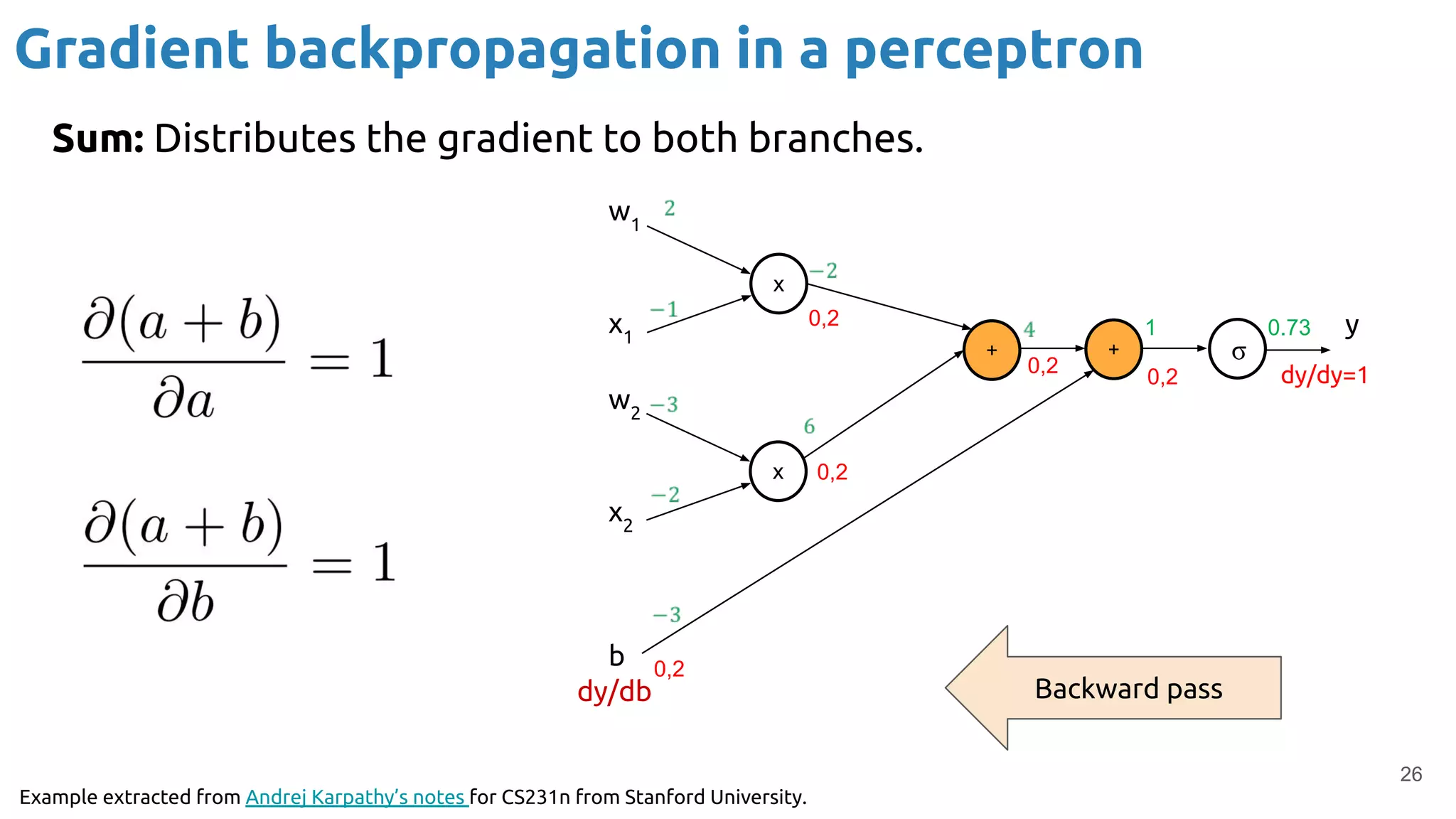
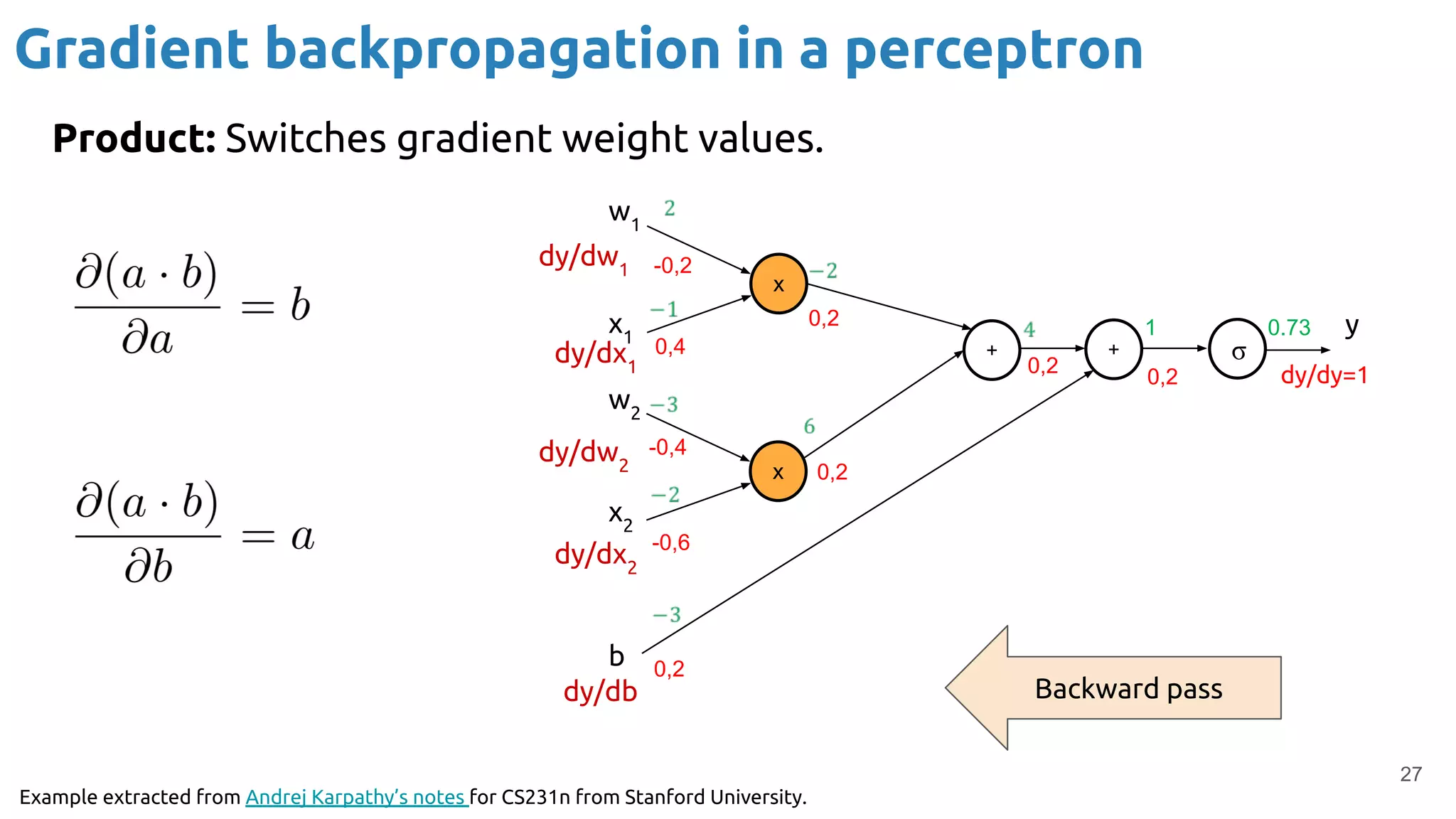
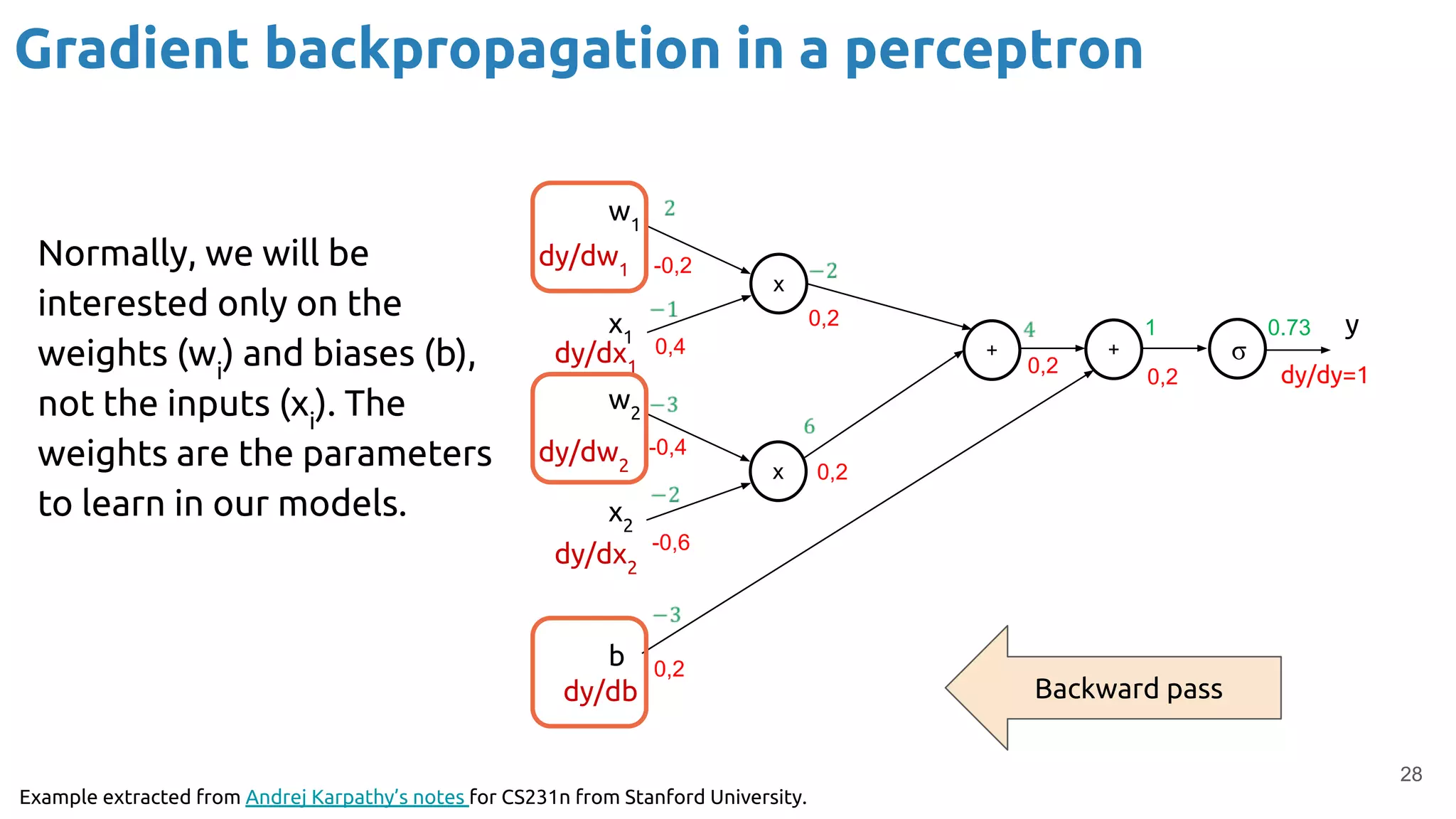
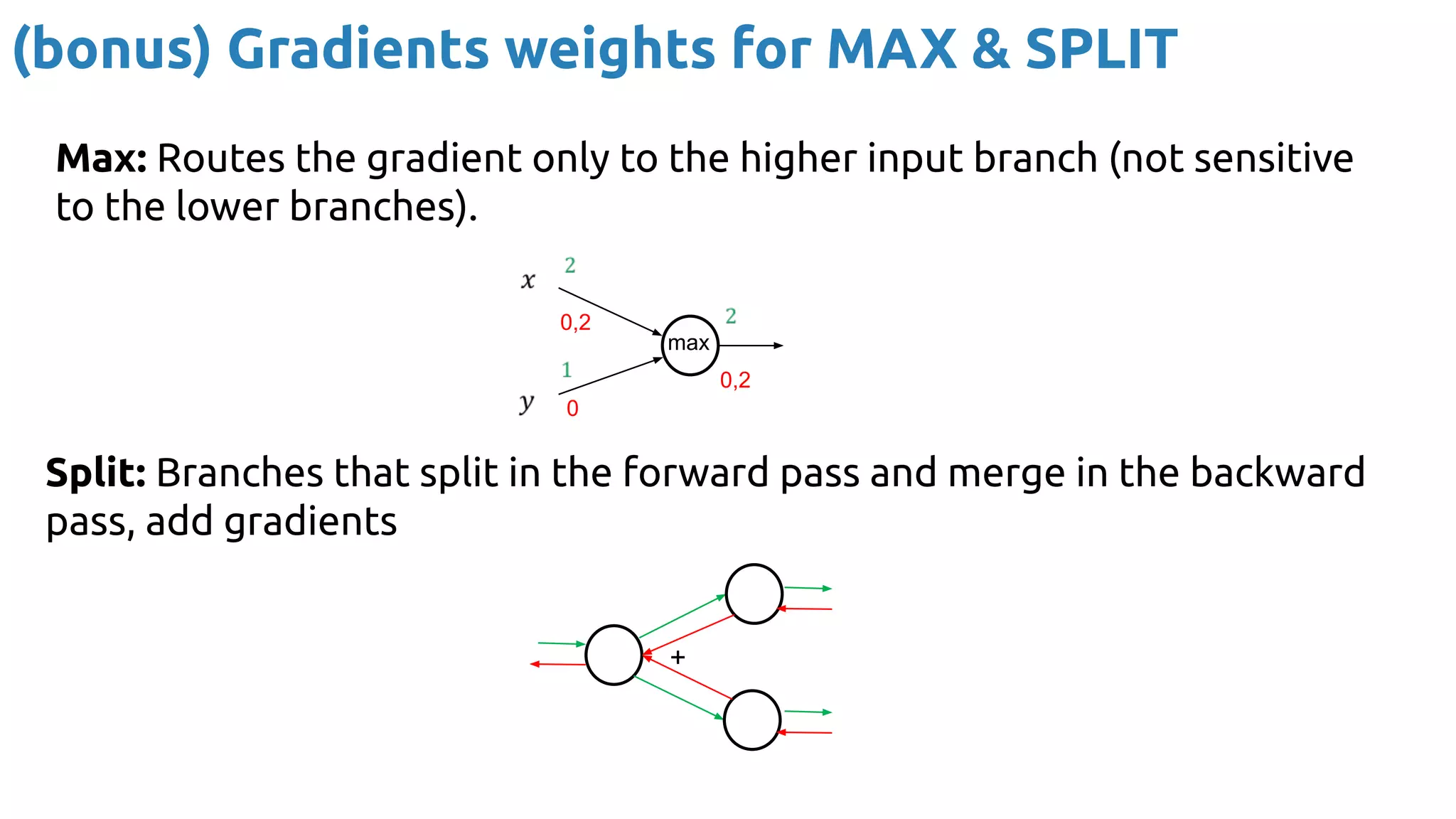
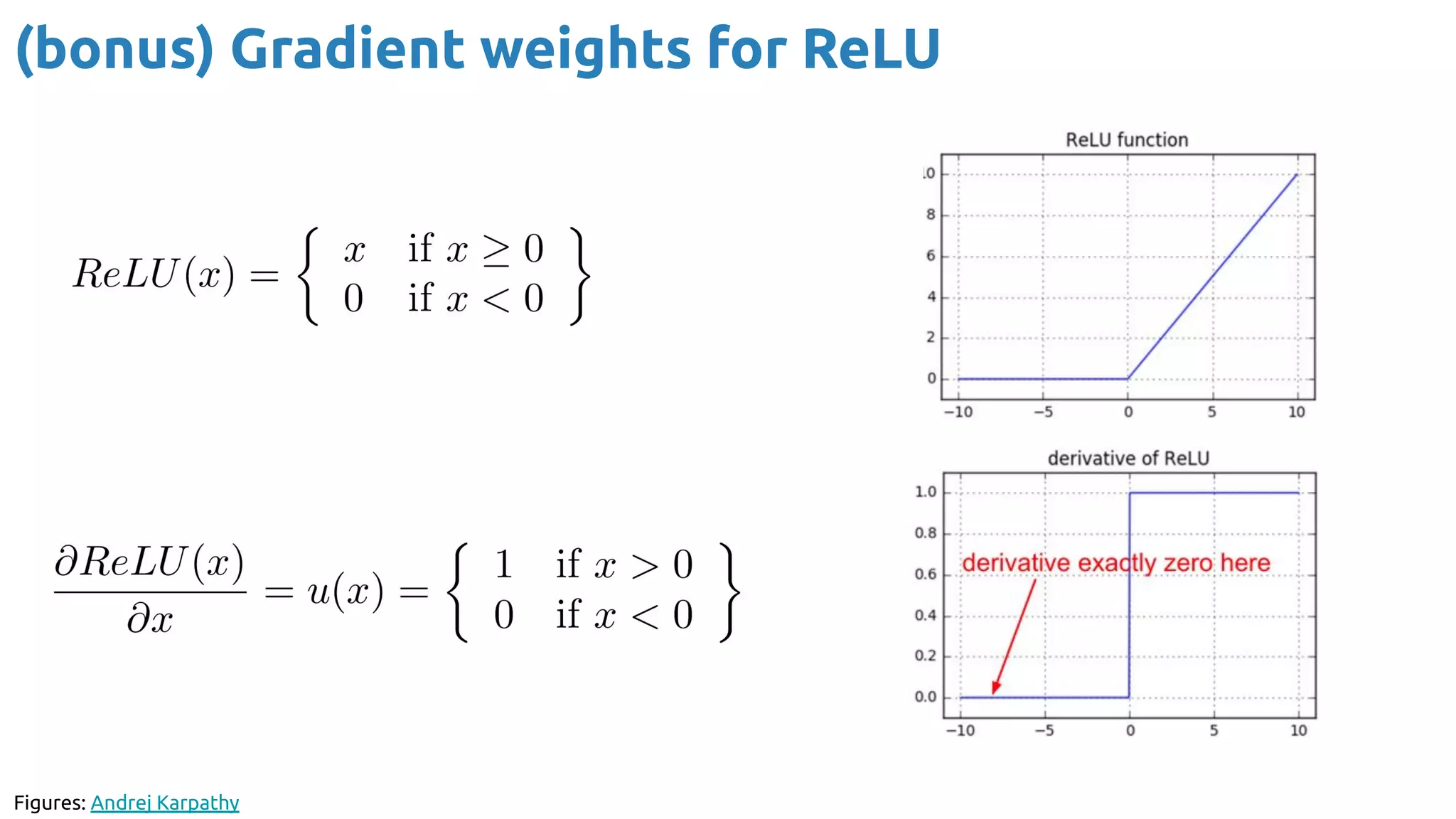


The document discusses the loss function and gradient descent in the context of neural networks, specifically focusing on backpropagation as a method to compute gradients that optimize model parameters. It includes explanations of computational graphs for perceptrons and the role of activation functions, along with derivations of how gradients are propagated through different operations. Additionally, it offers insights into learning rates and links to further resources for deeper understanding.






















































































