Download as PDF, PPTX





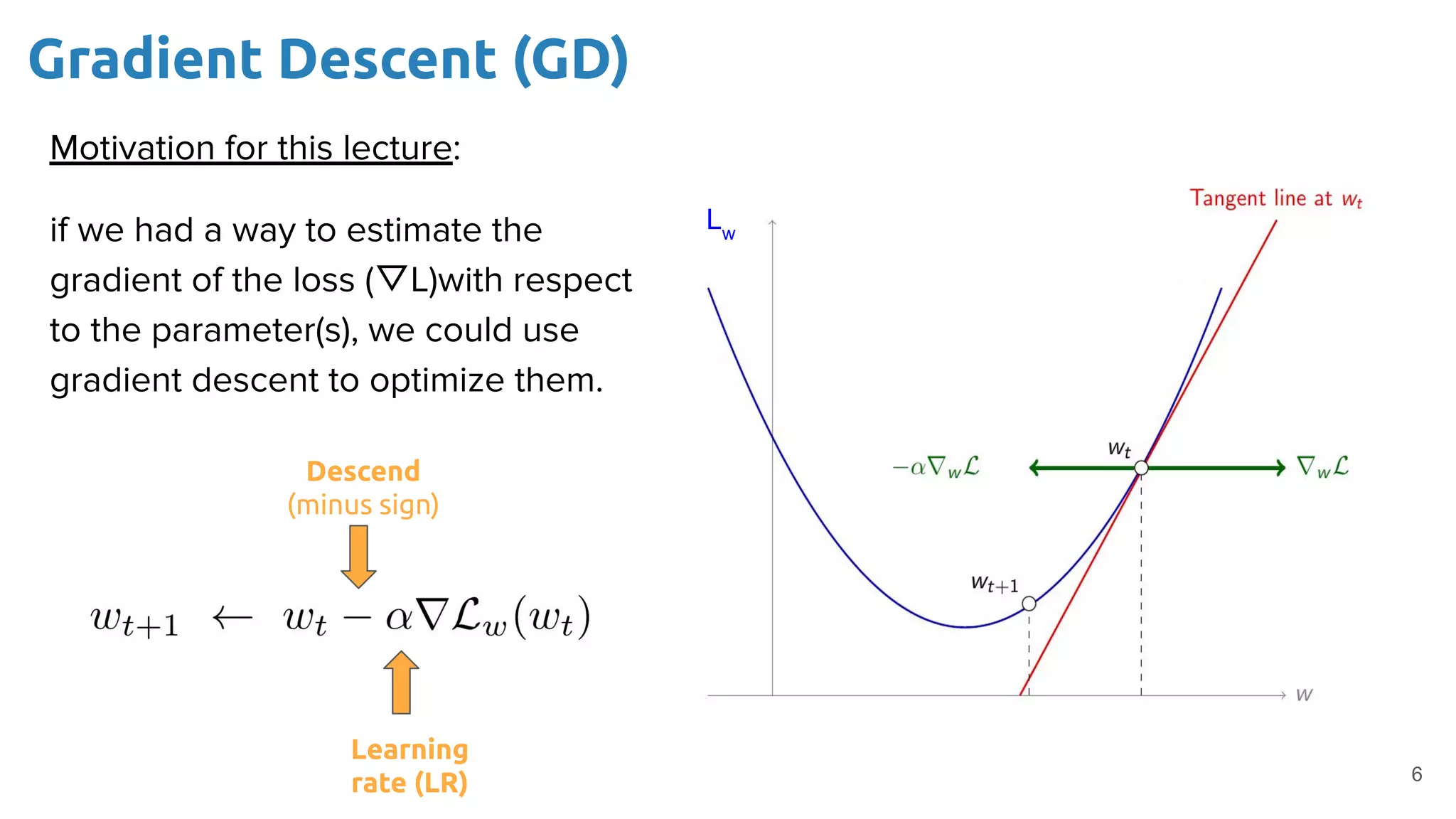


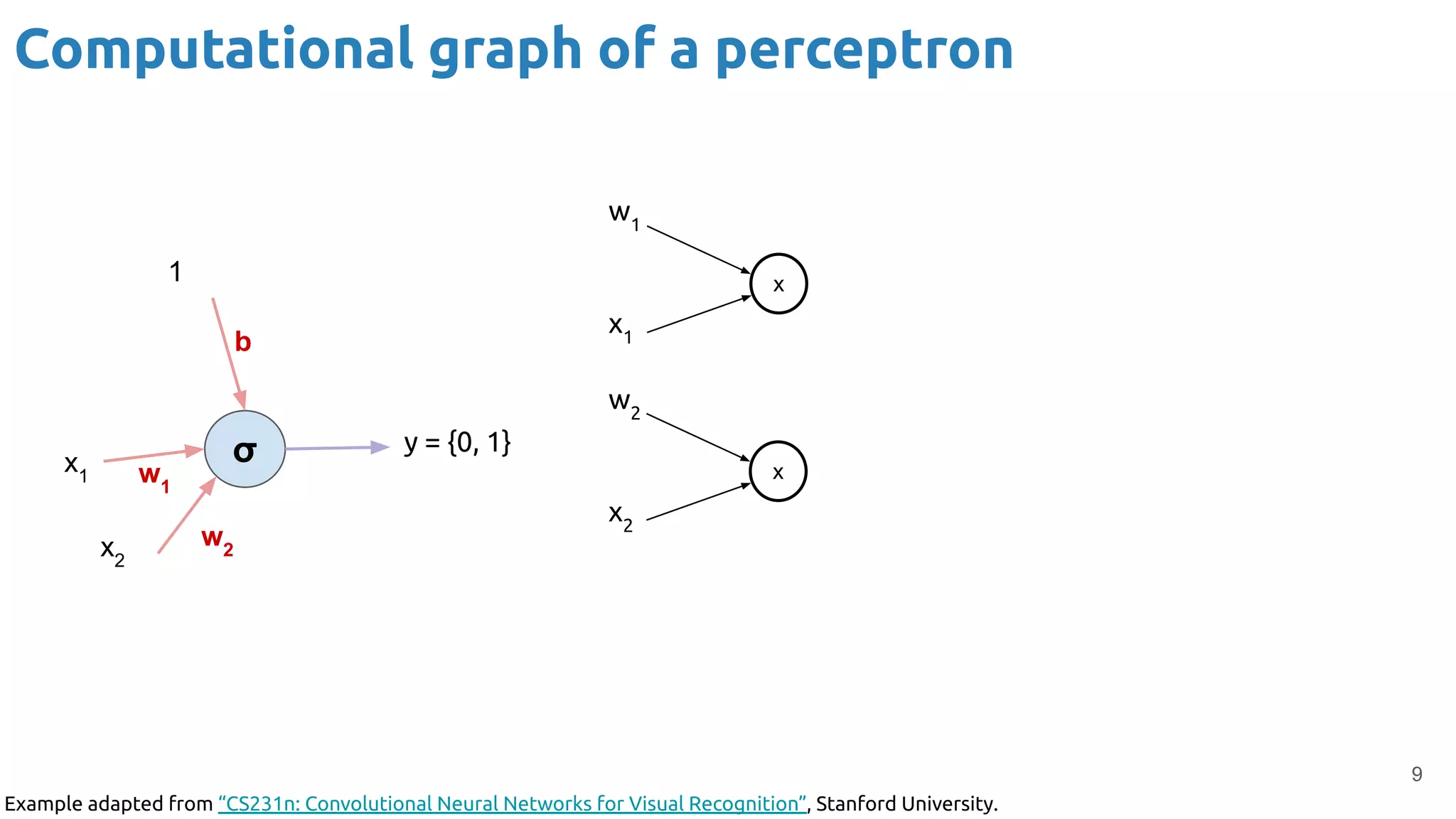

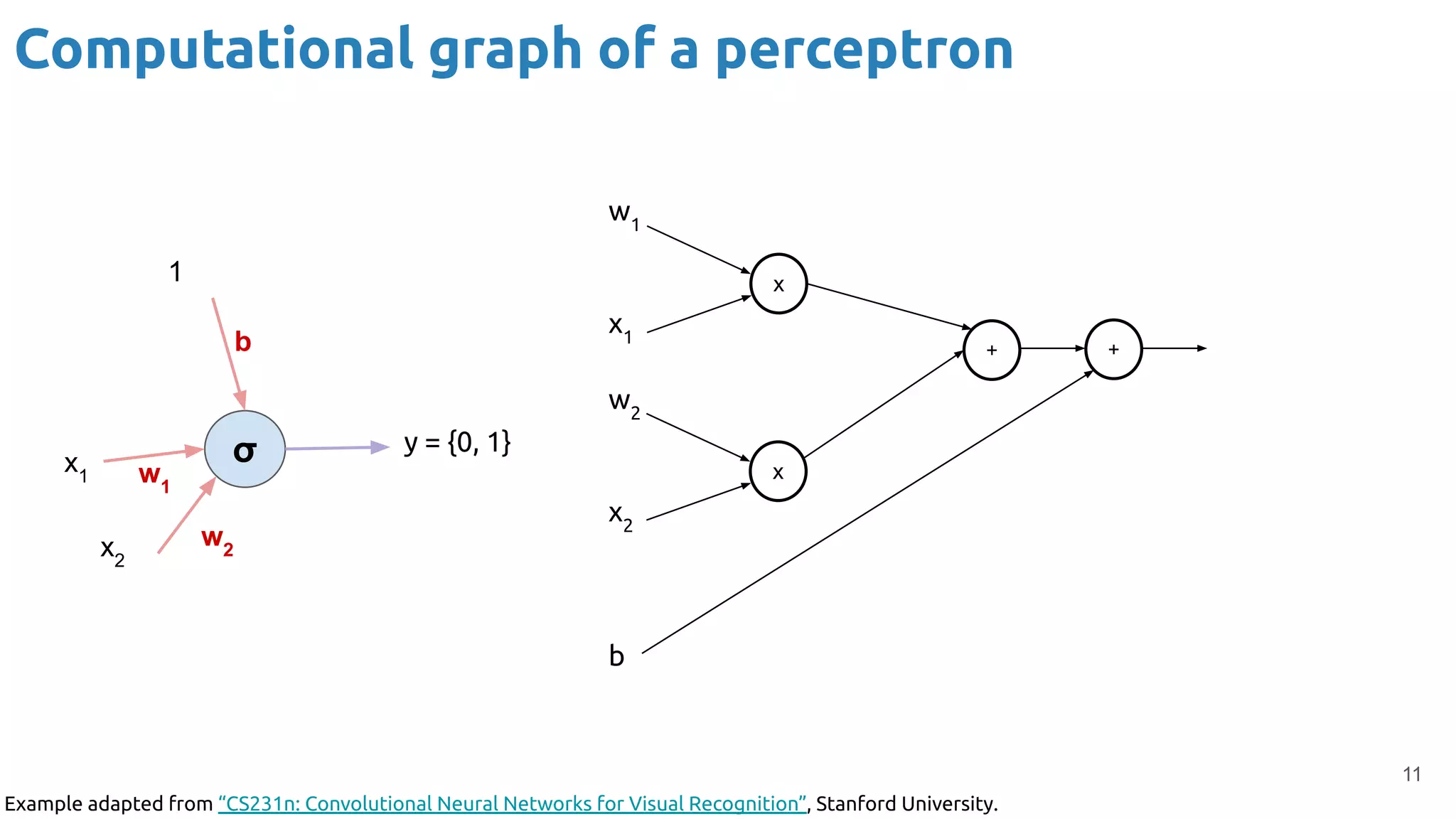
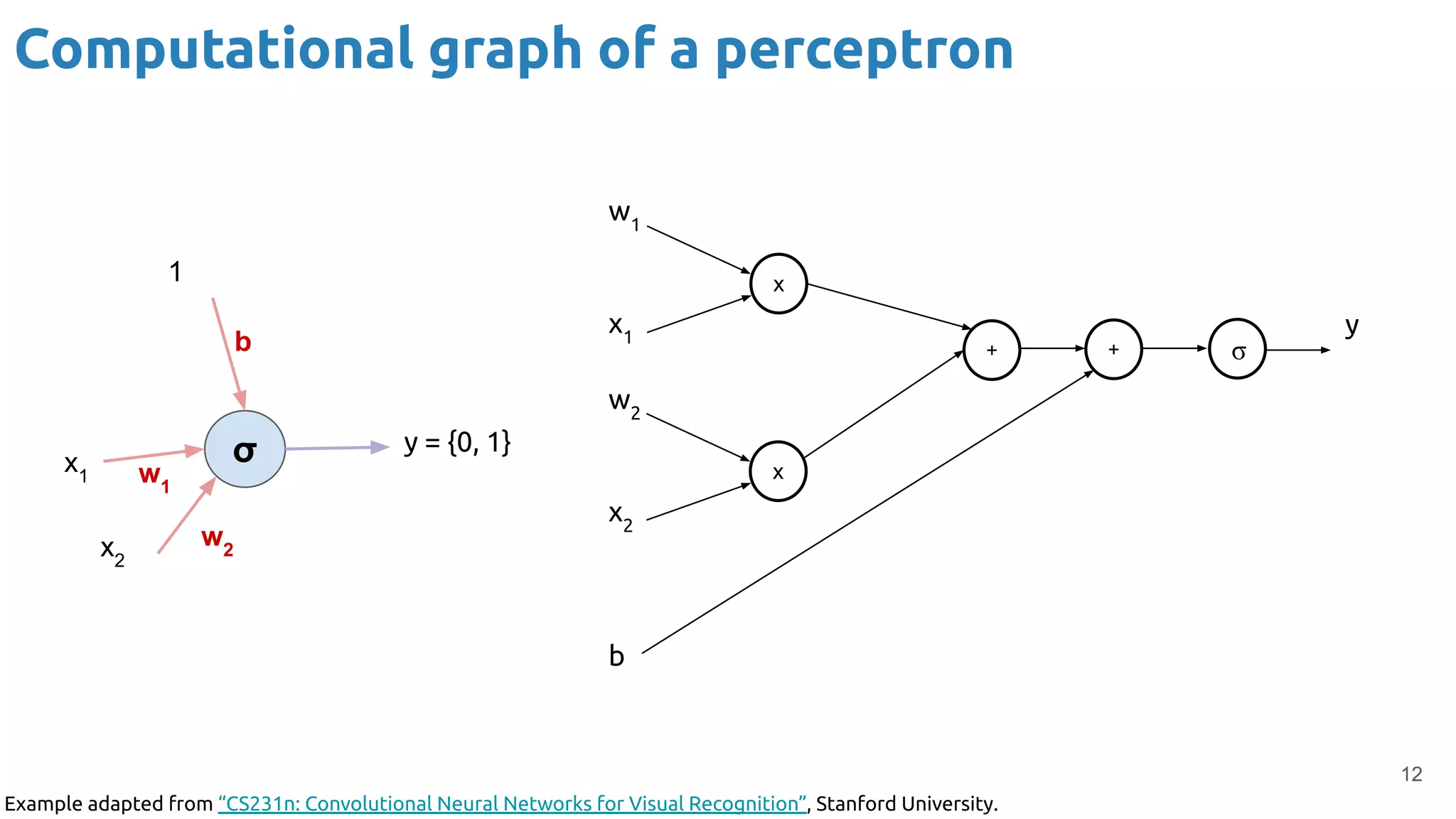
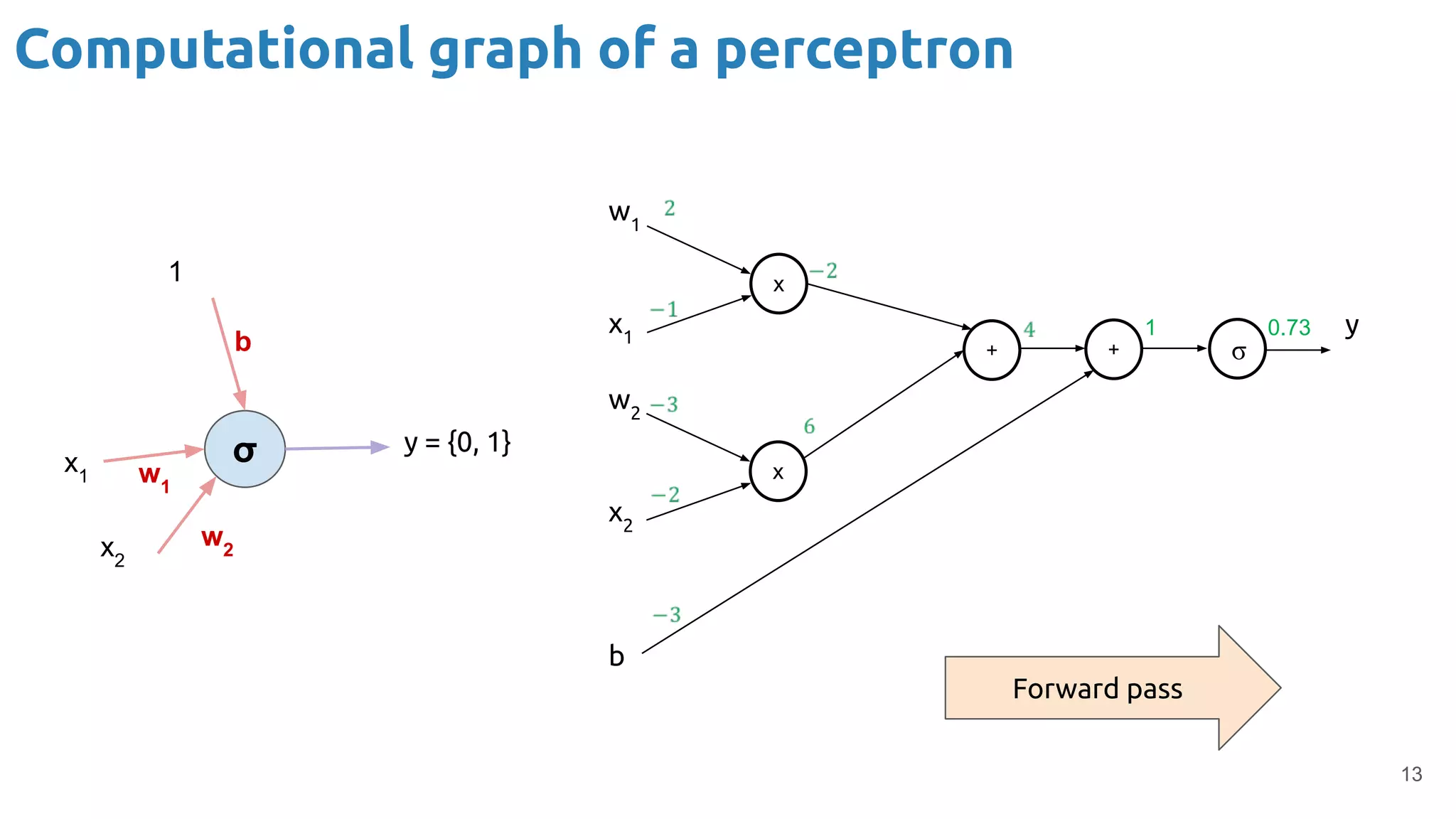
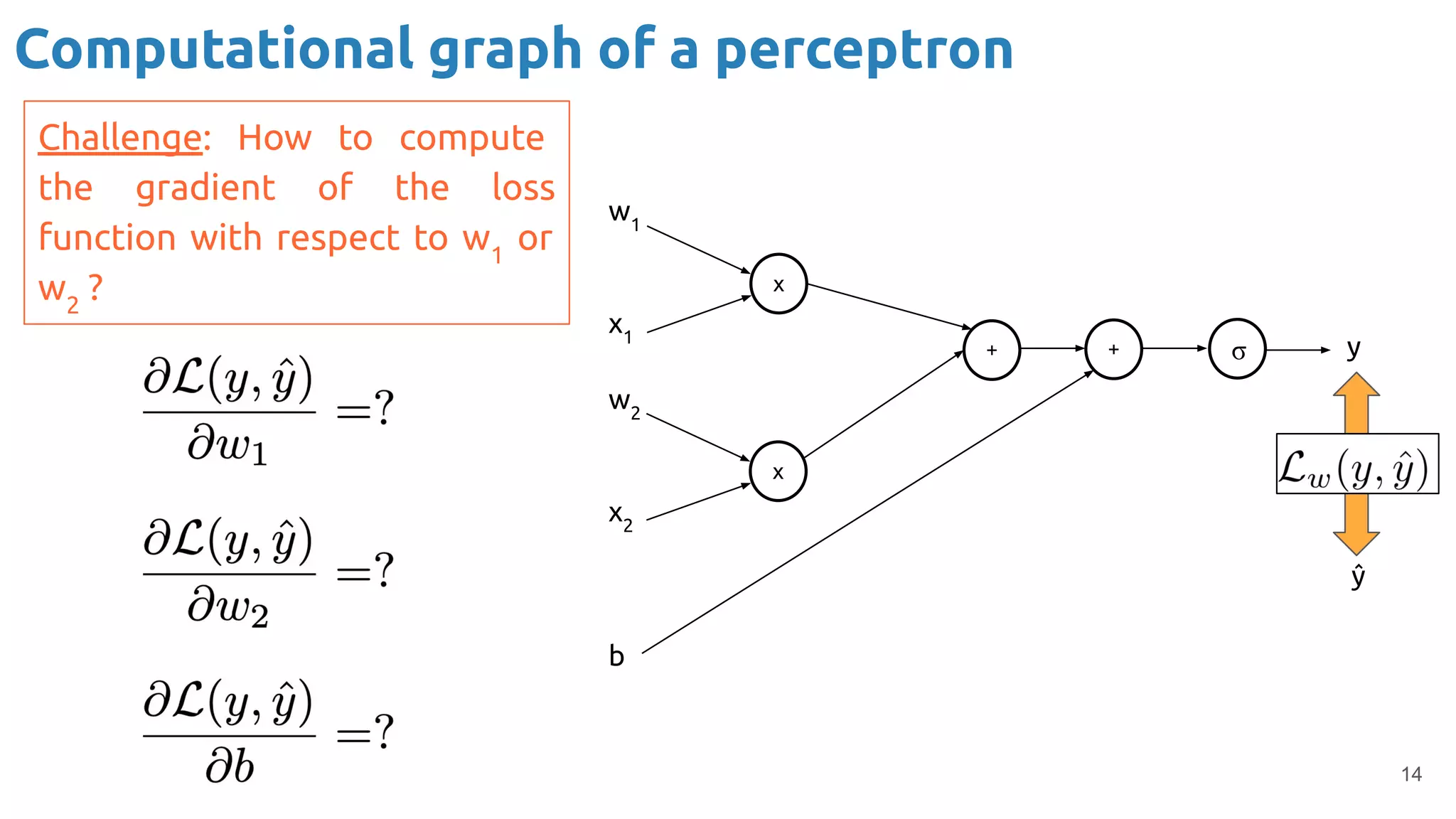

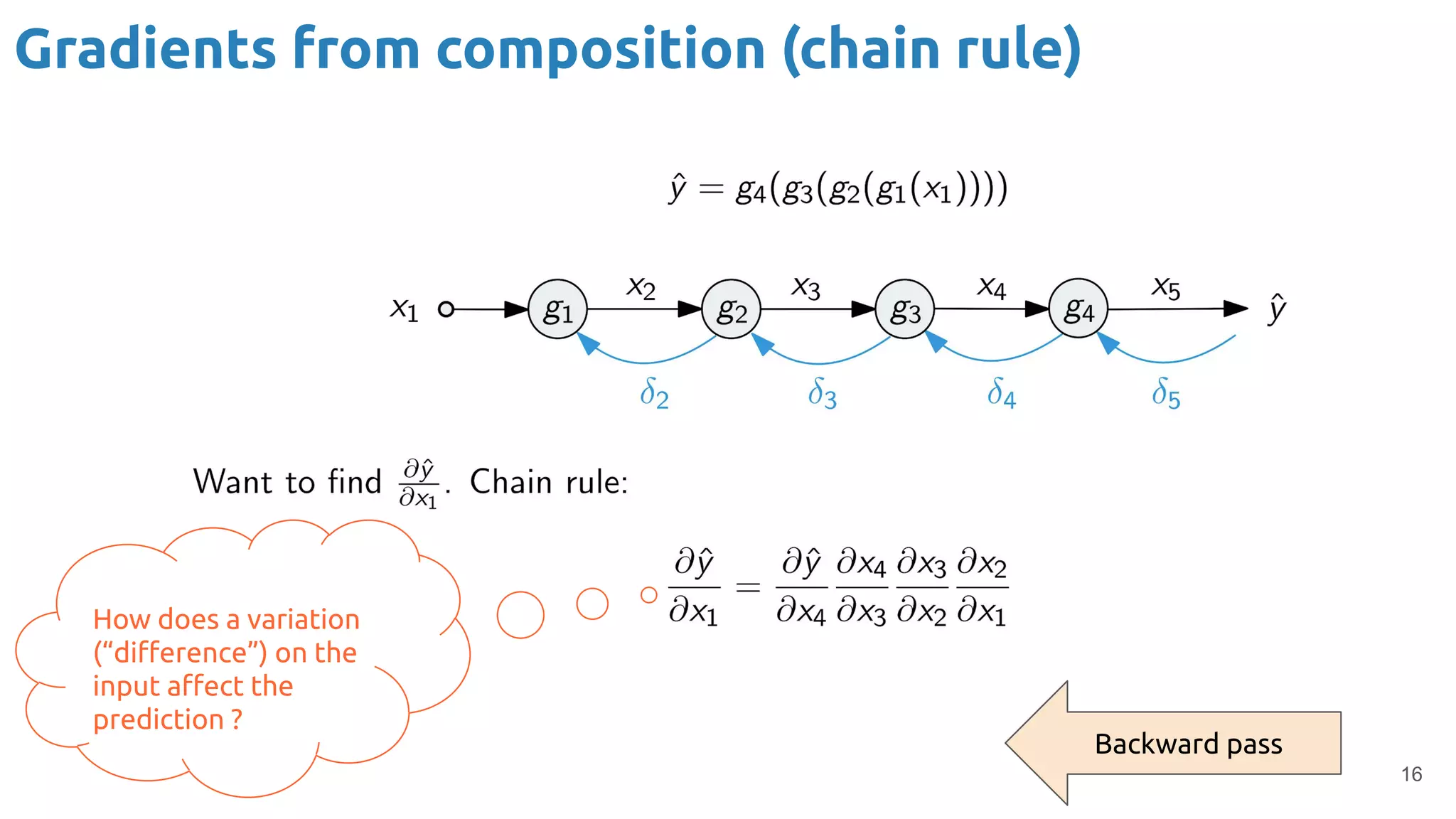
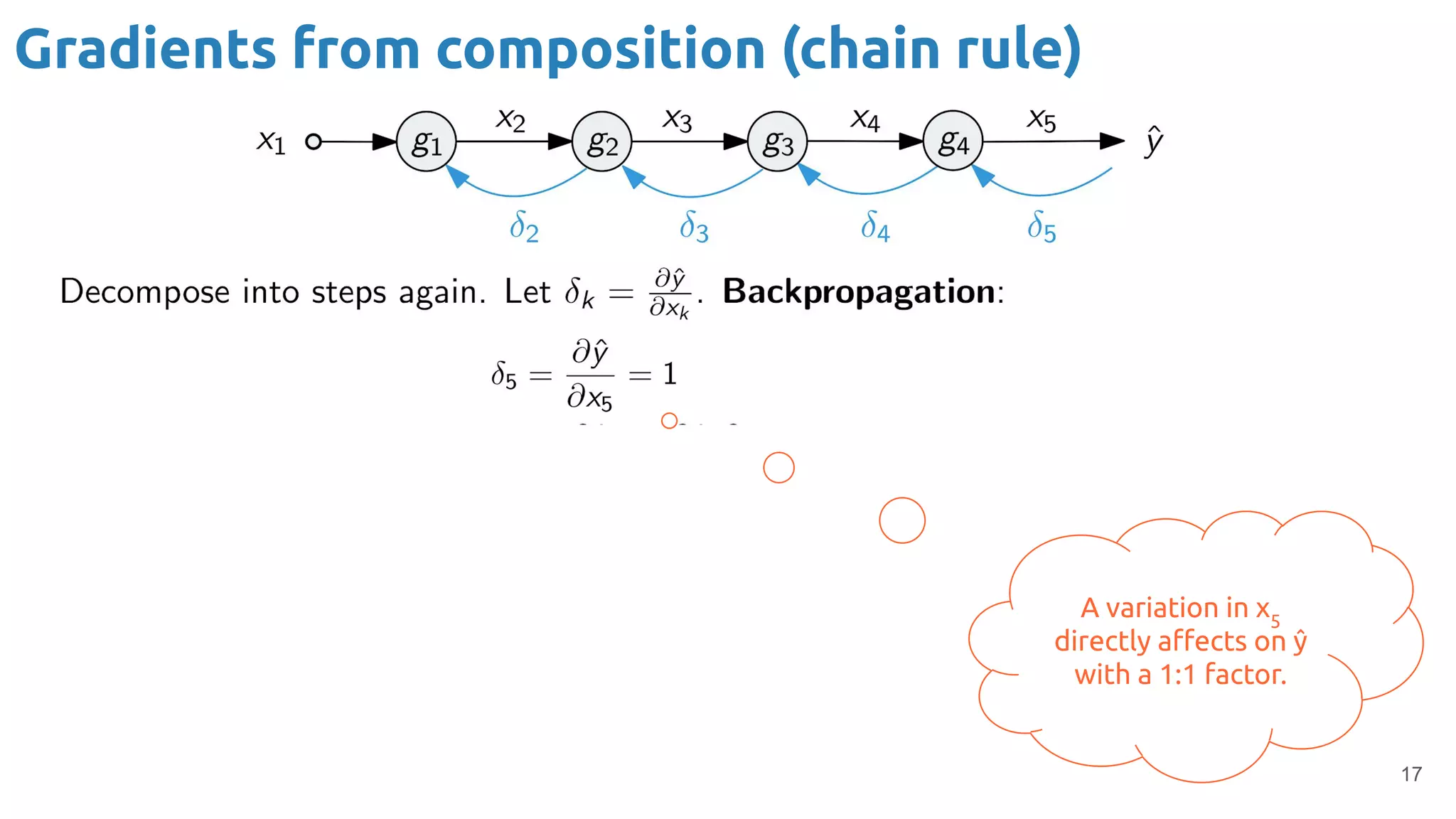
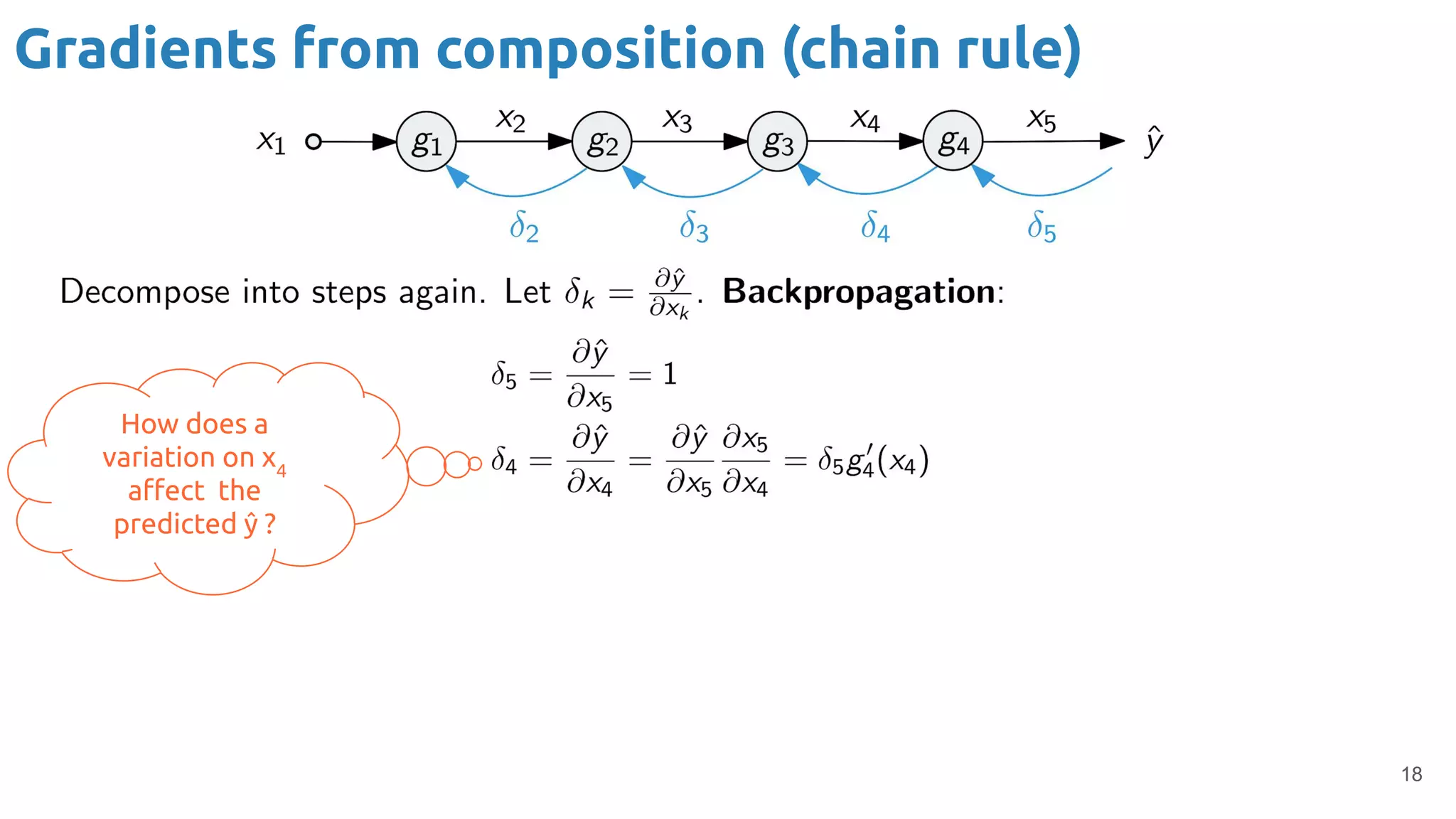
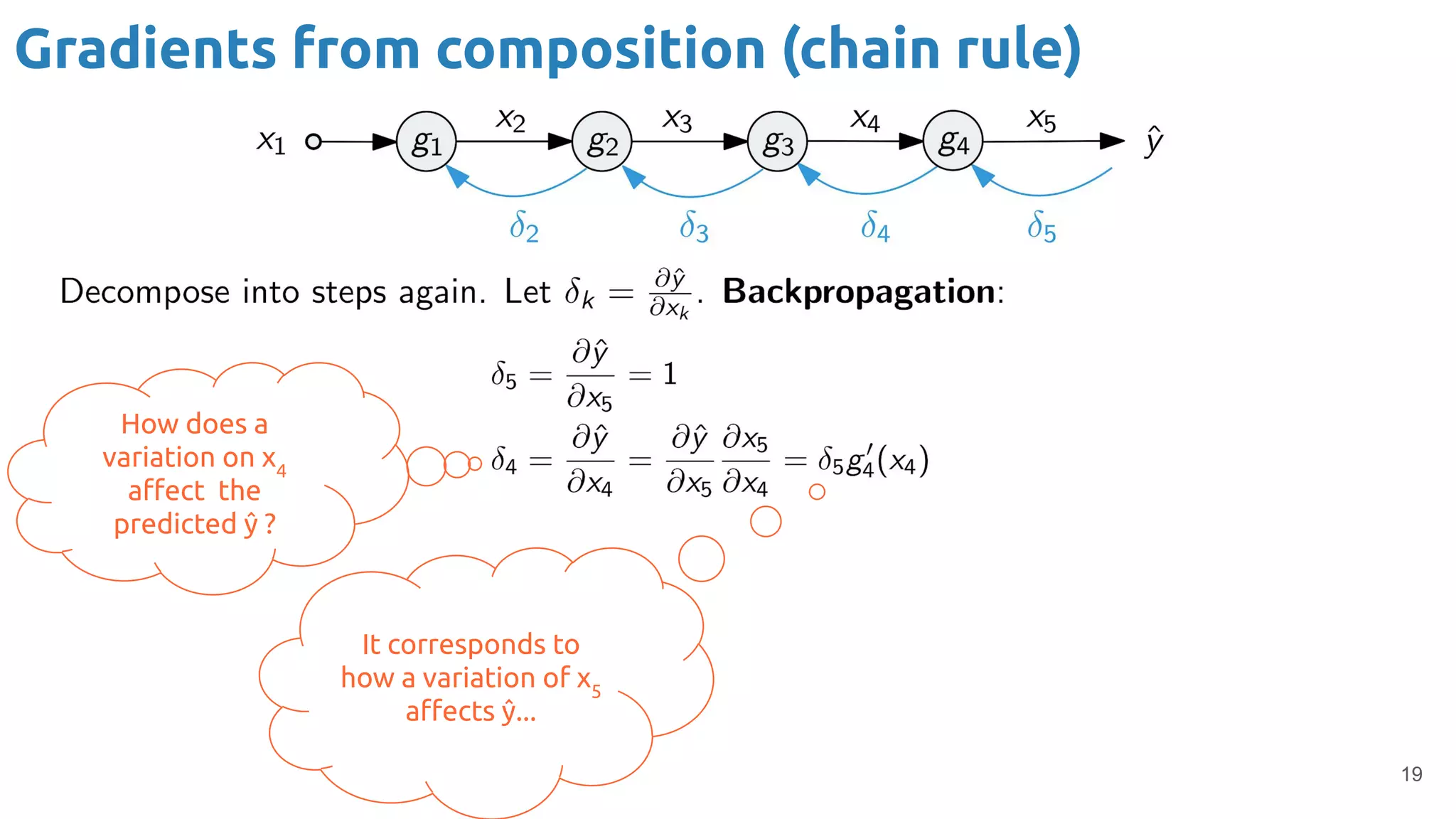
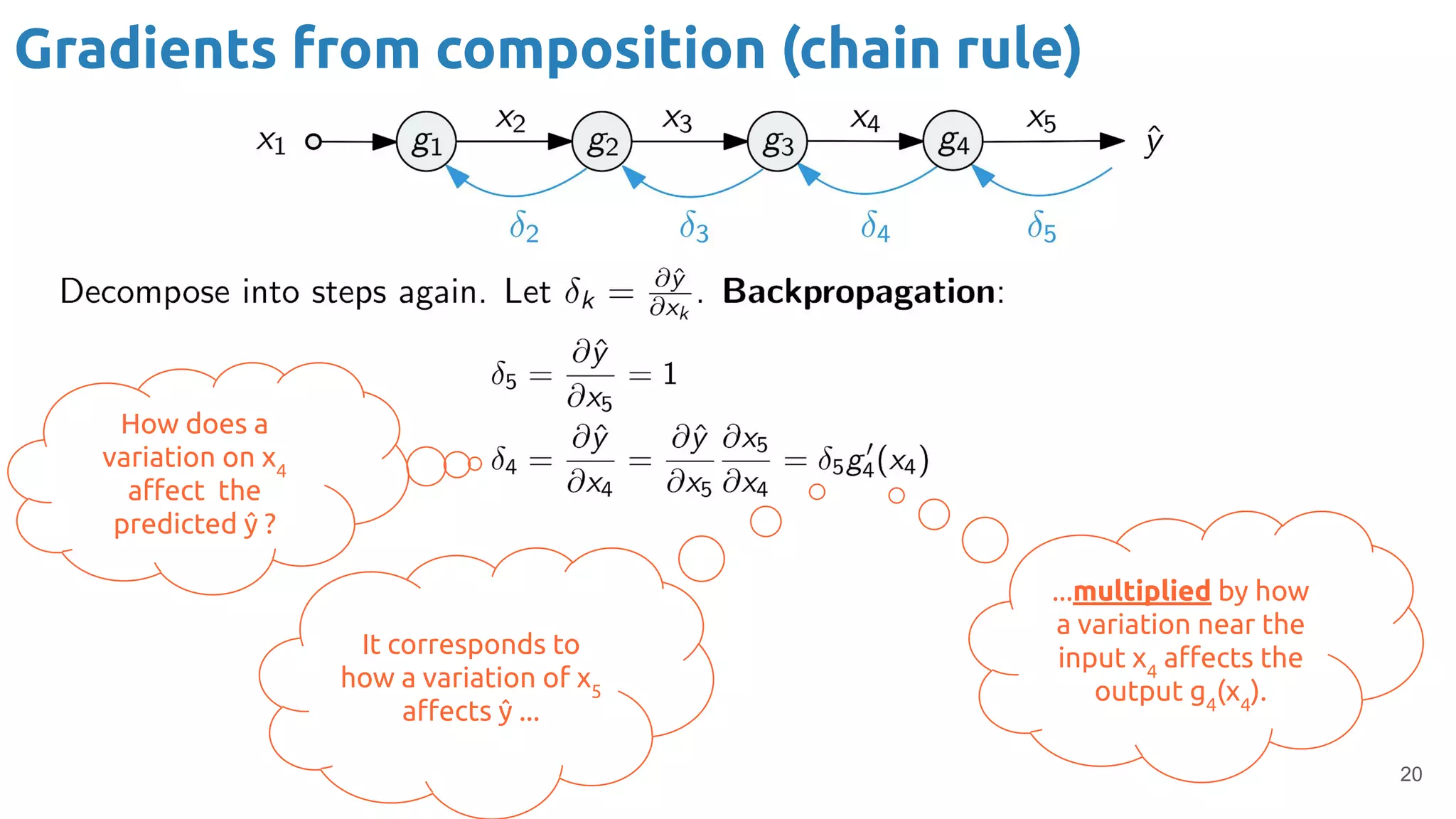
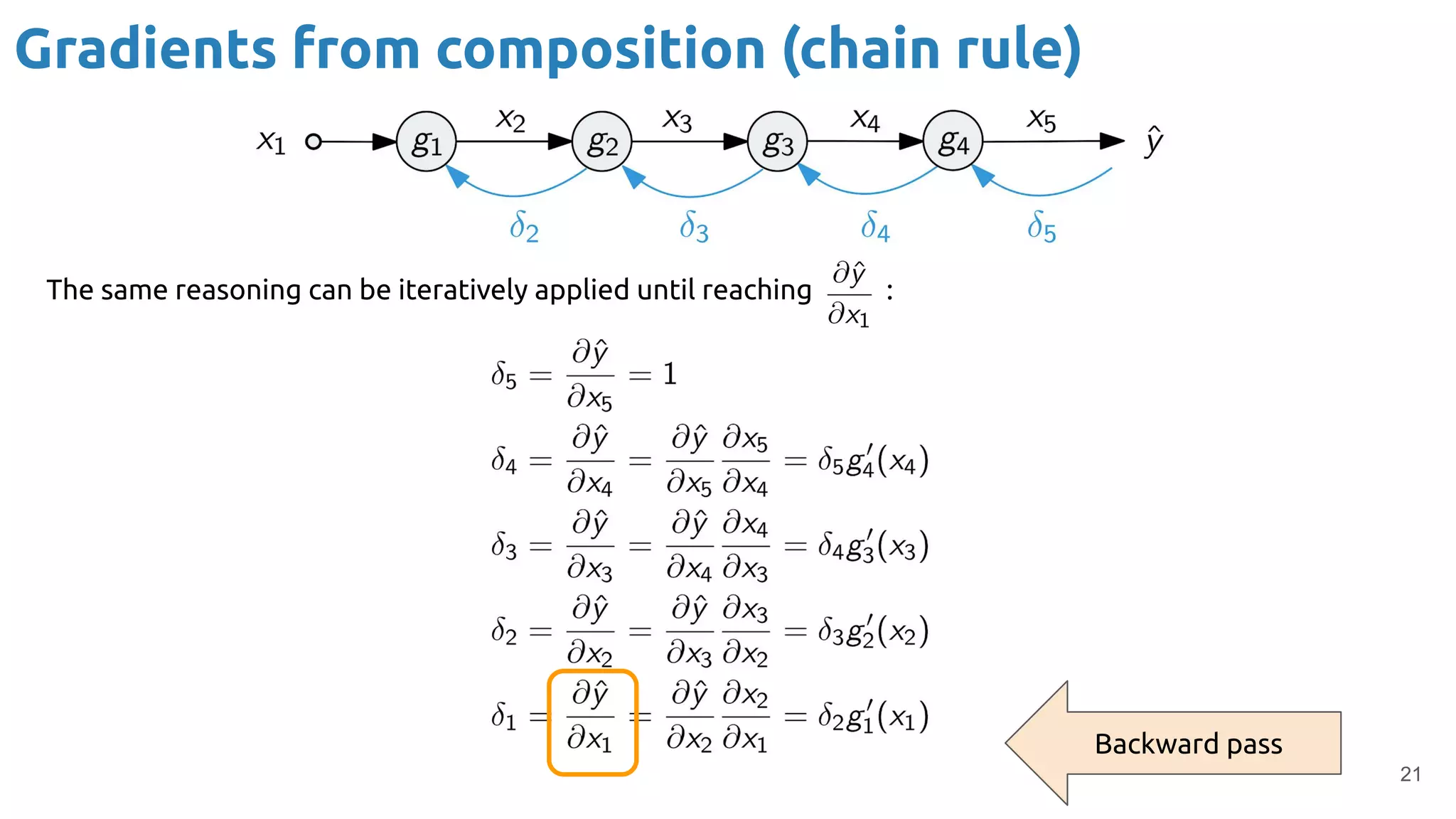
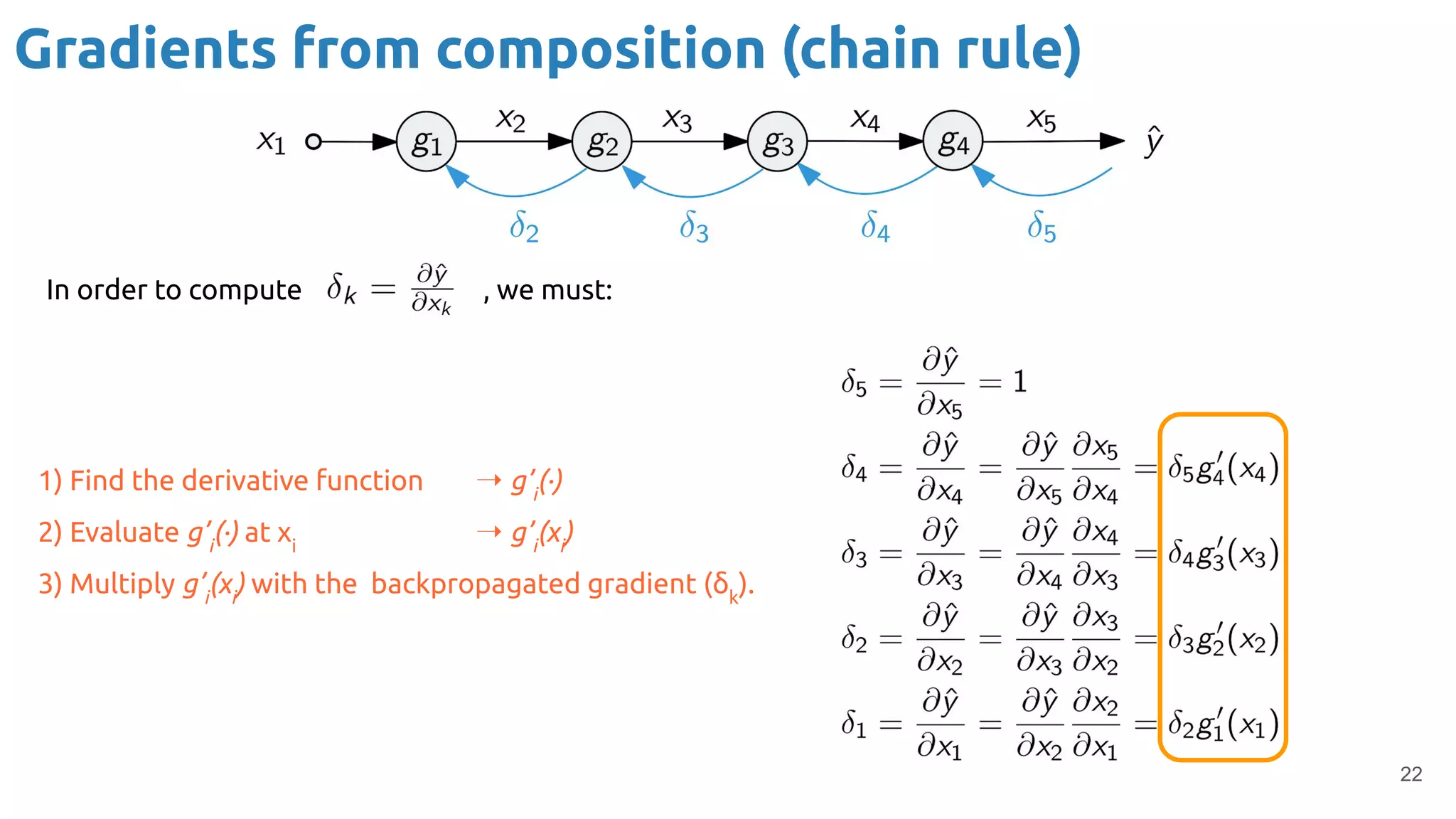

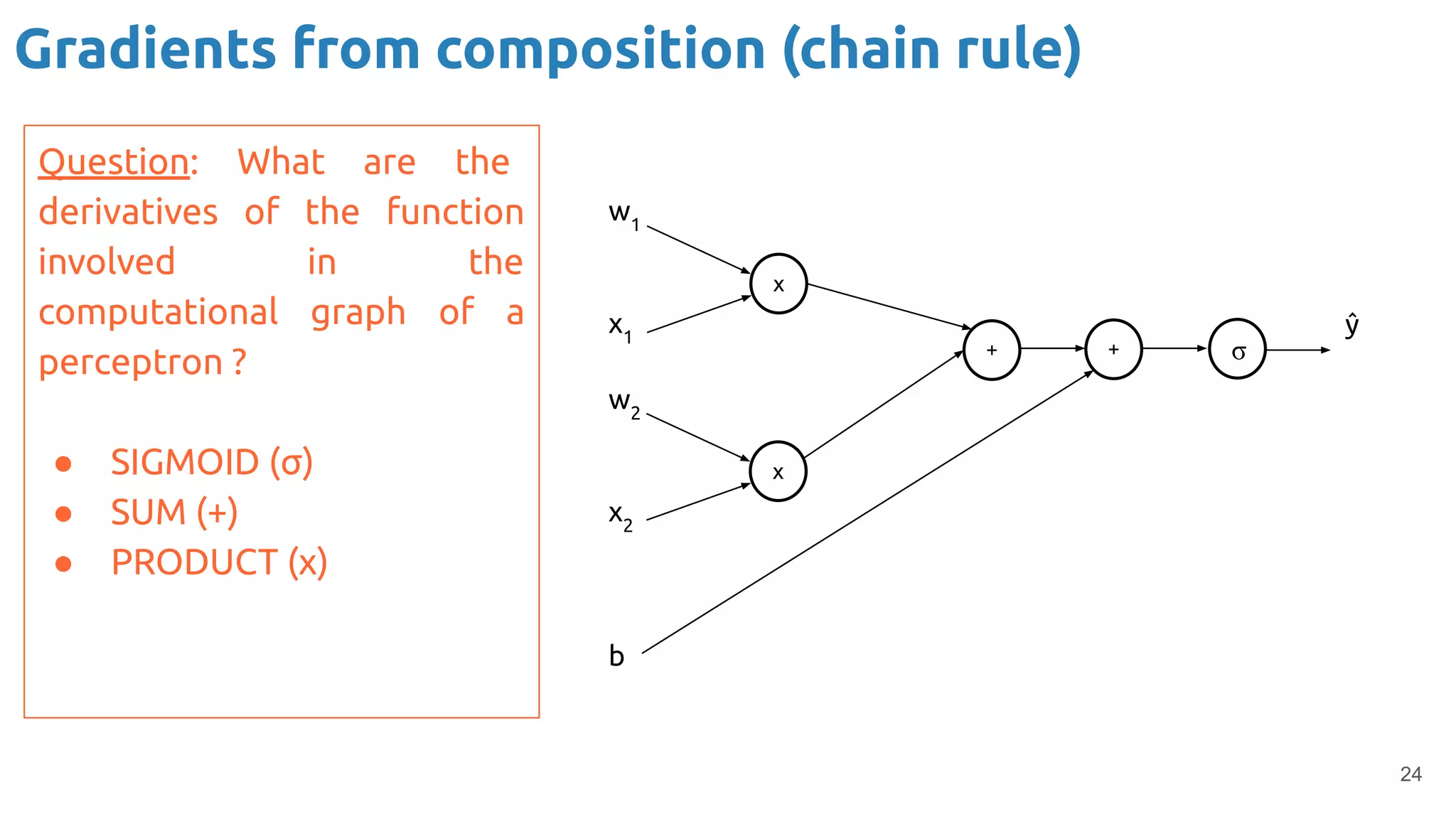
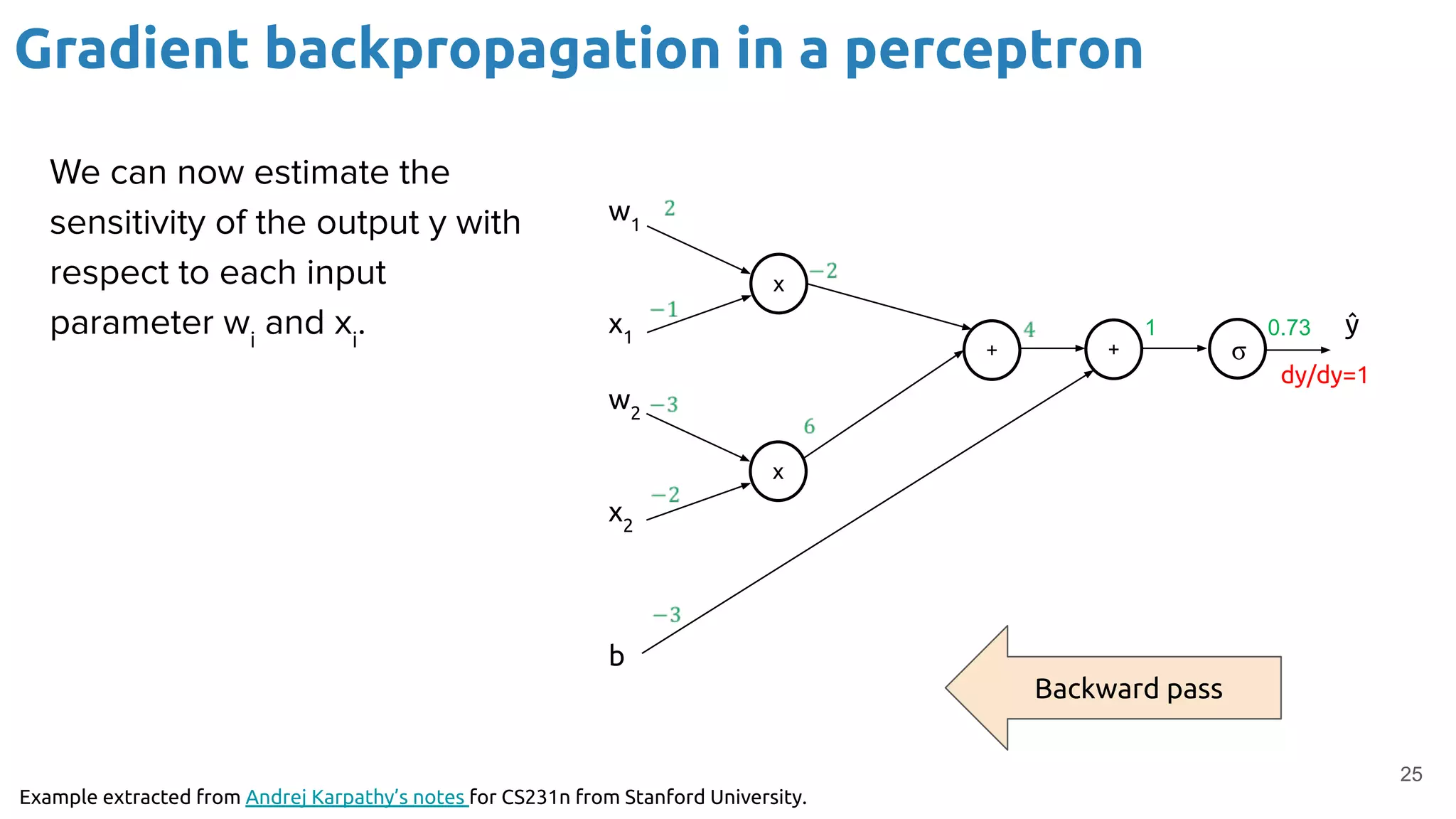

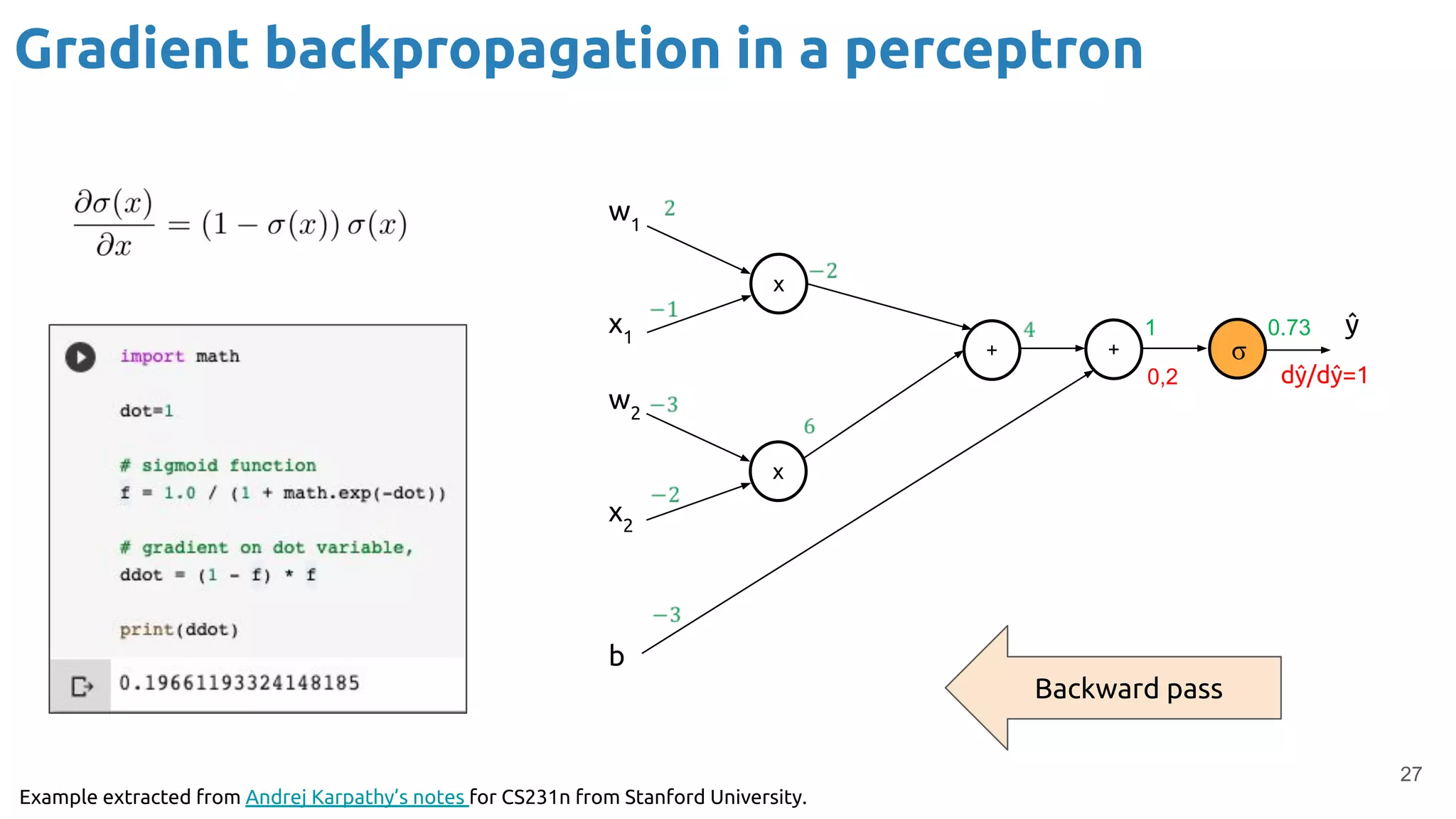
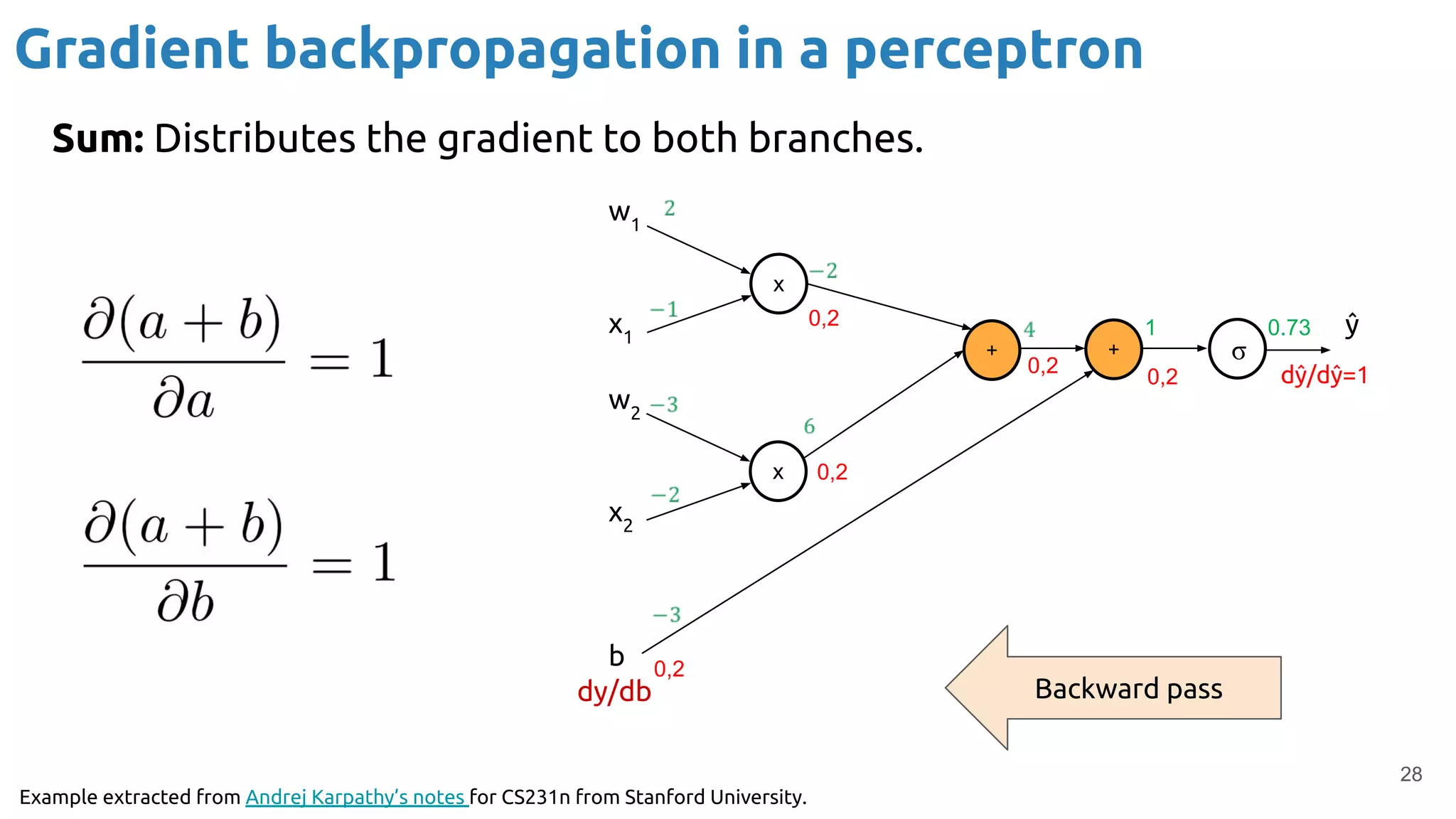
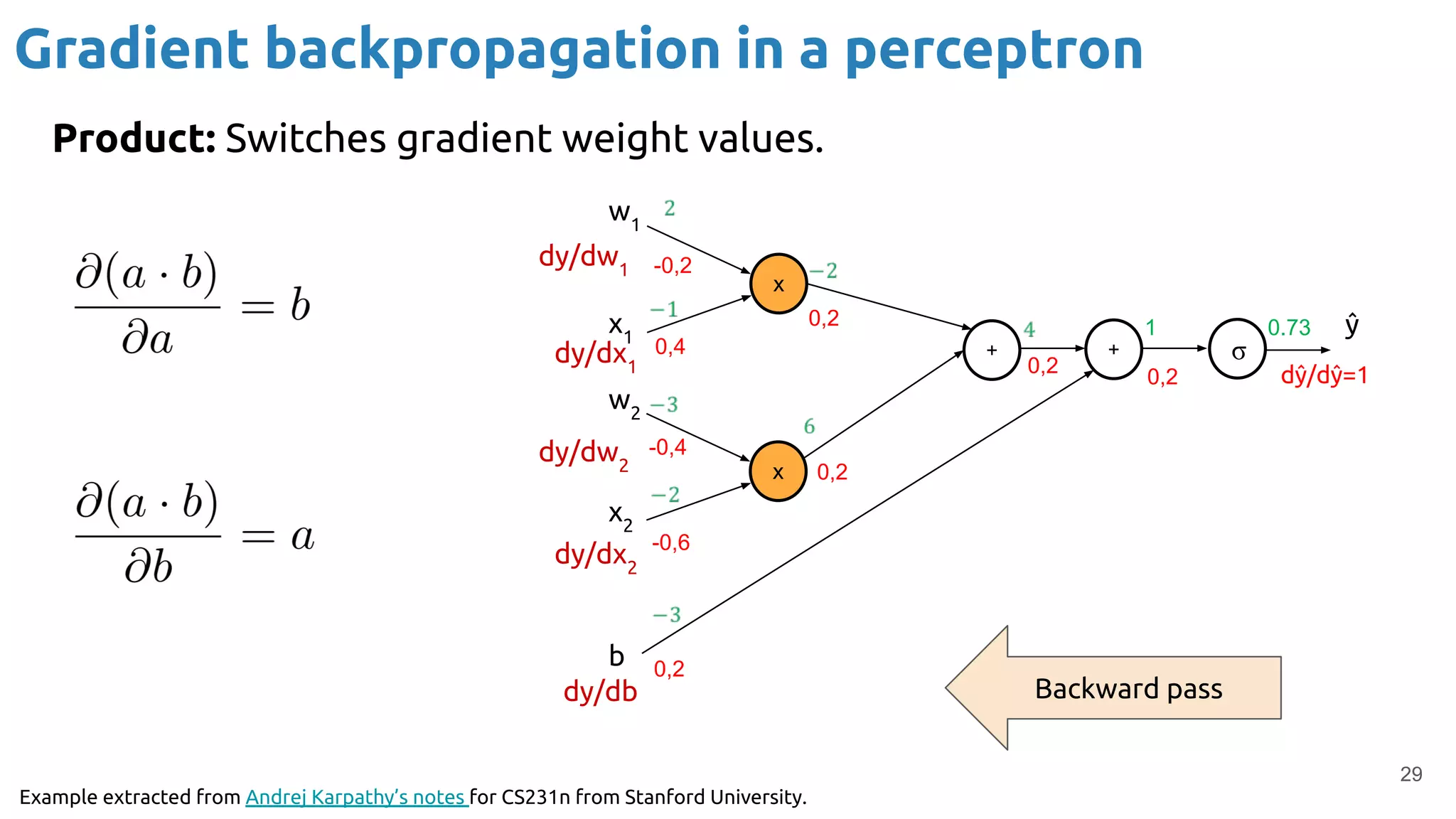
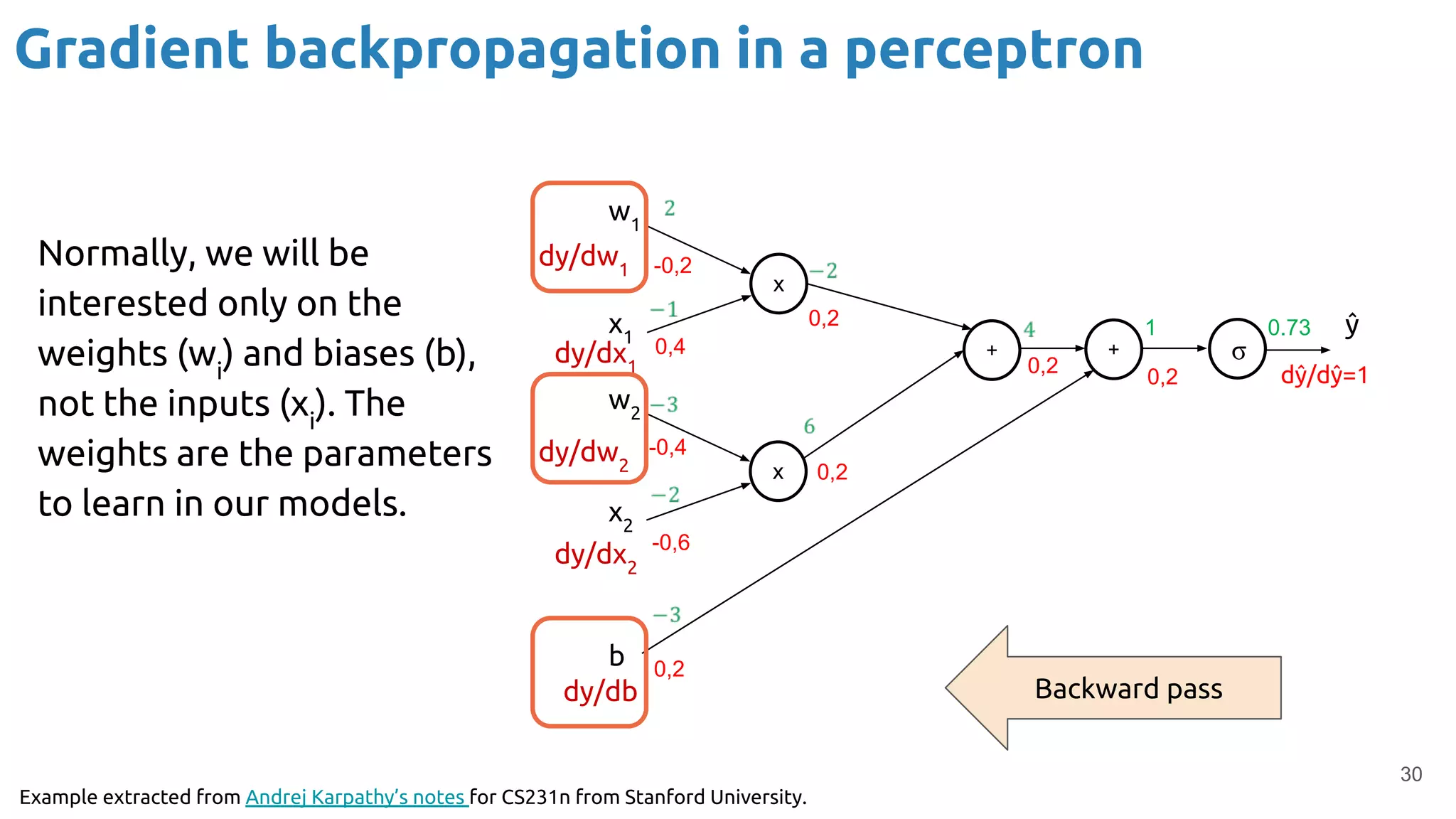
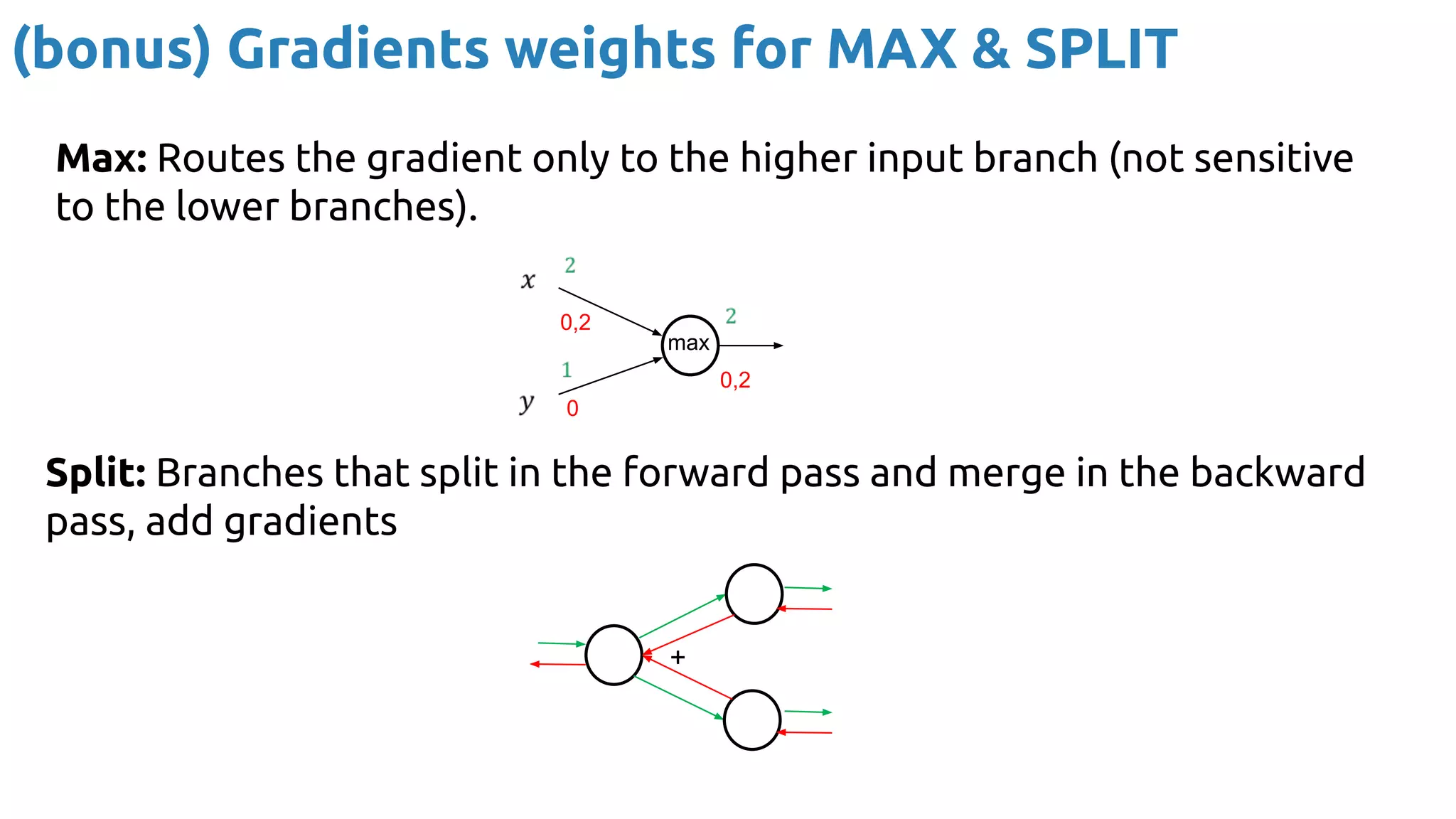
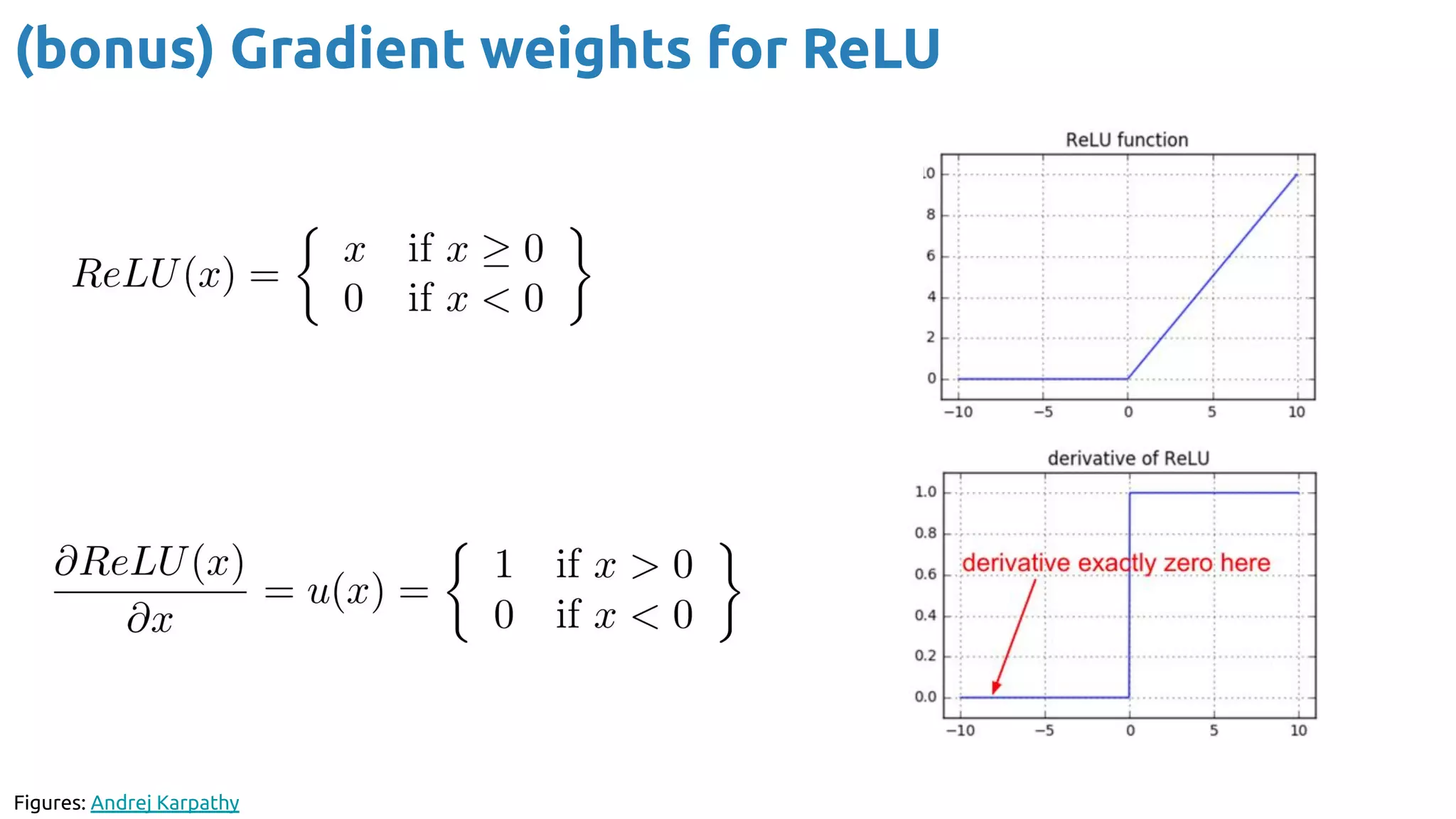
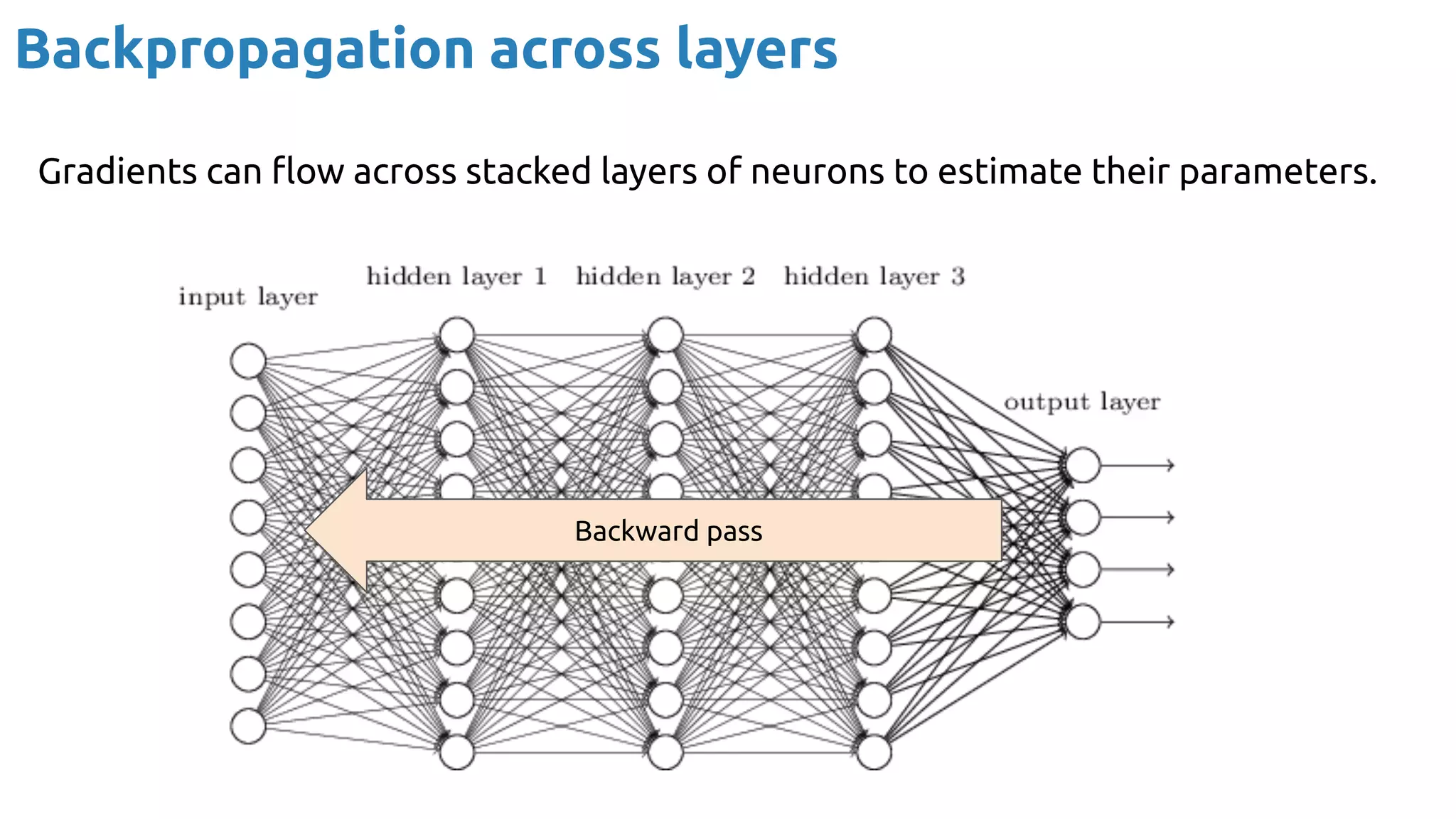


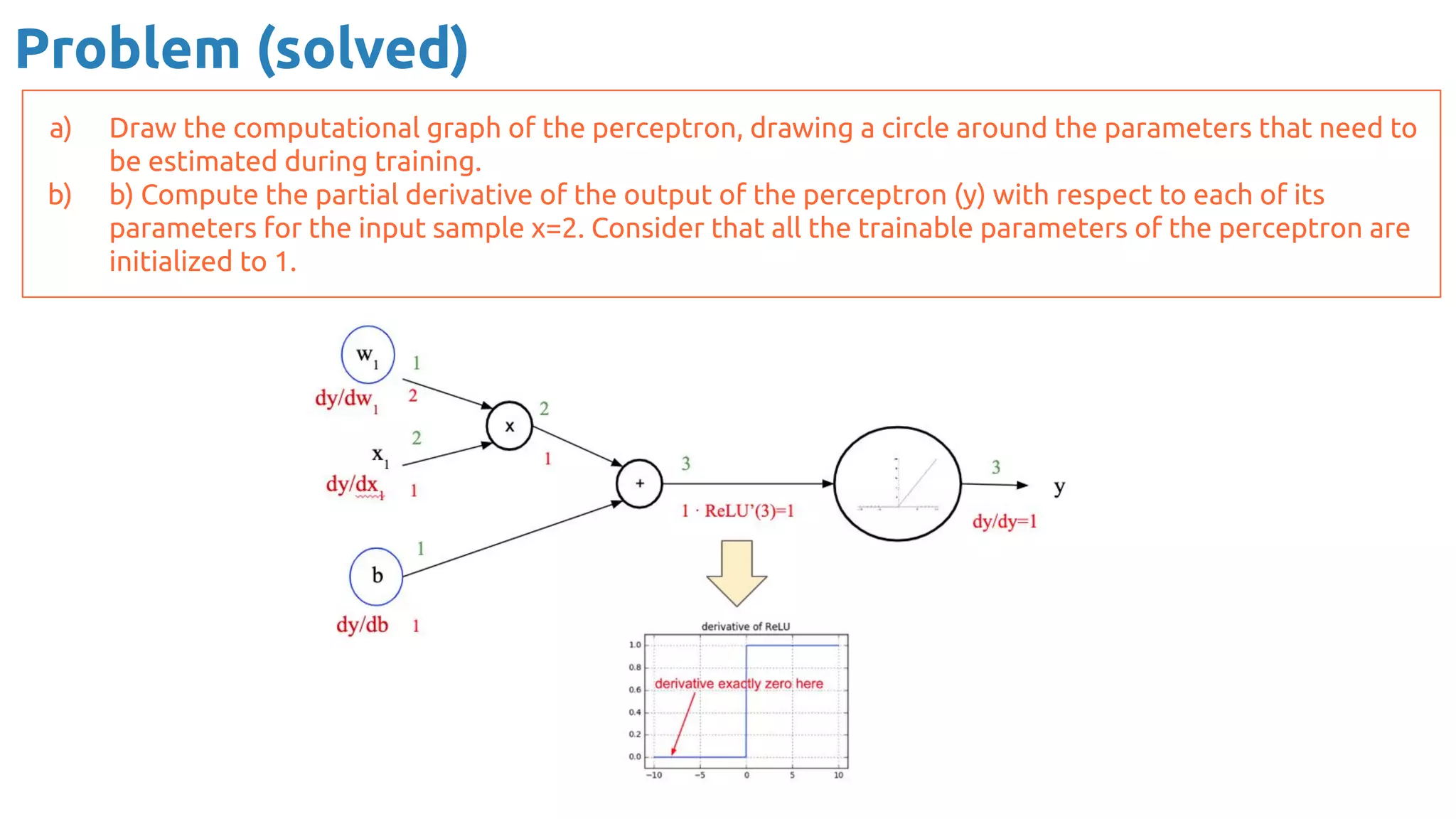
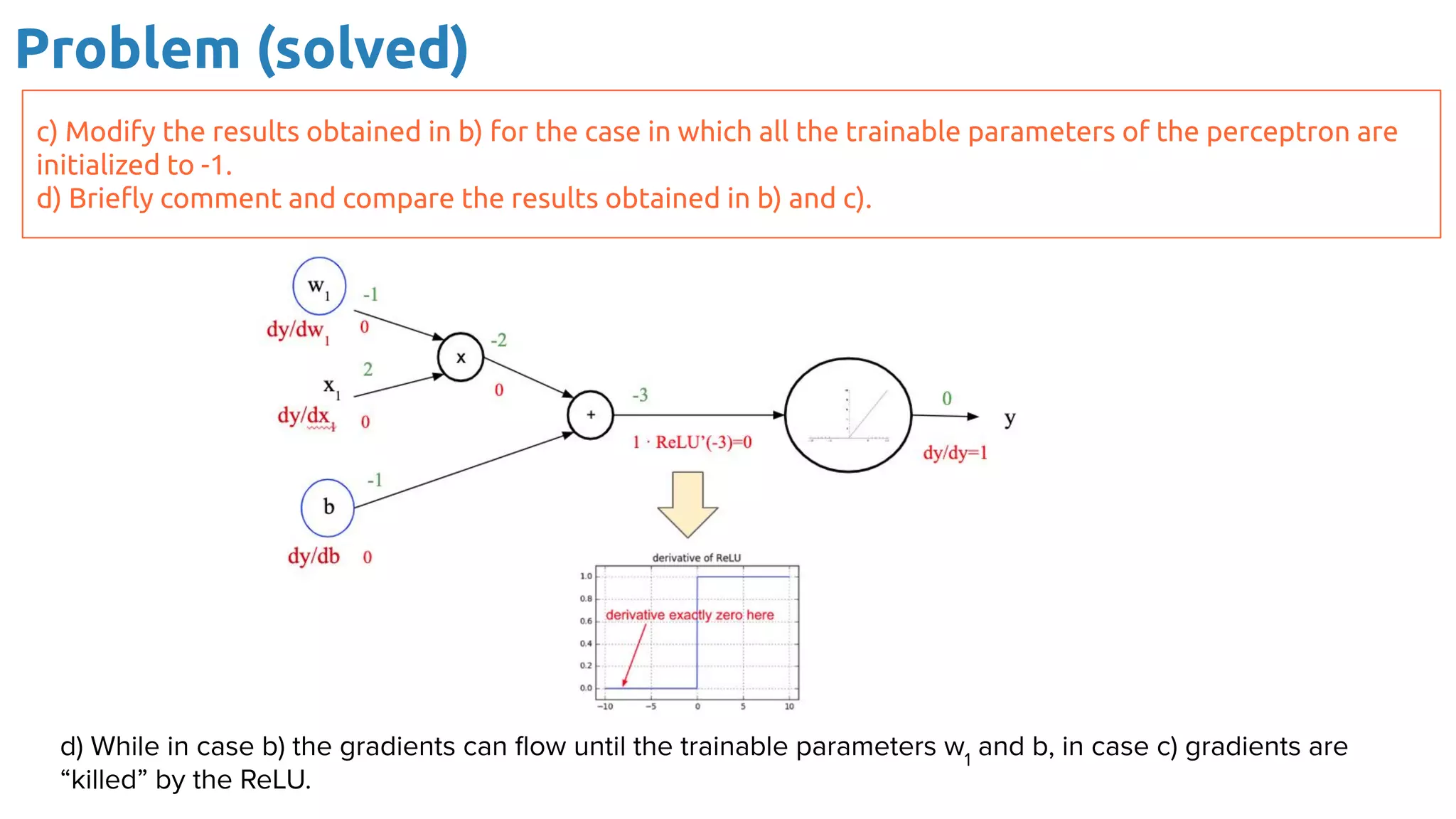

The document provides an overview of backpropagation for neural networks. It begins by defining the loss function and discussing gradient descent. It then walks through the computational graph of a simple perceptron and derives the gradients for each operation using the chain rule. This allows computing the gradient of the loss with respect to the weights and biases, which are then updated using gradient descent. It discusses computing gradients for different activation functions like sigmoid, ReLU, and max pooling. Finally, it notes that backpropagation allows estimating parameters across stacked neural network layers.





















































































