Download as PDF, PPTX















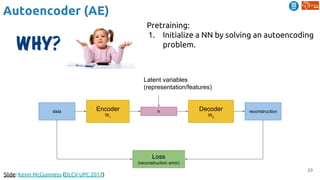
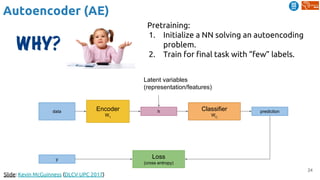












![51
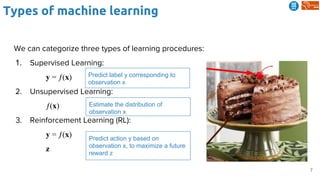
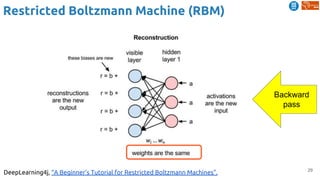
Predictive Learning
Srivastava, Nitish, Elman Mansimov, and Ruslan Salakhutdinov. "Unsupervised Learning of Video
Representations using LSTMs." In ICML 2015. [Github]
Learning video representations (features) by...](https://image.slidesharecdn.com/dlai2018d4l2learningwithoutannotations-181016102255/85/Deep-Learning-without-Annotations-Xavier-Giro-UPC-Barcelona-2018-51-320.jpg)
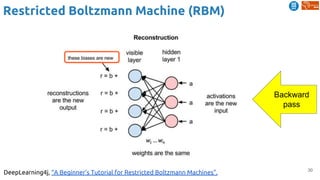
![52
Predictive Learning
Srivastava, Nitish, Elman Mansimov, and Ruslan Salakhutdinov. "Unsupervised Learning of Video
Representations using LSTMs." In ICML 2015. [Github]
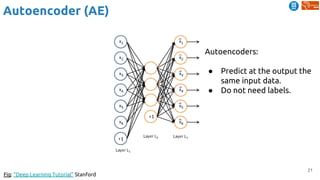
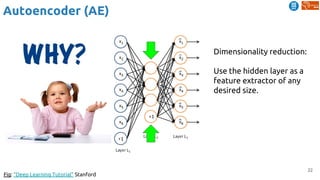
(1) frame reconstruction (AE):
Learning video representations (features) by...](https://image.slidesharecdn.com/dlai2018d4l2learningwithoutannotations-181016102255/85/Deep-Learning-without-Annotations-Xavier-Giro-UPC-Barcelona-2018-52-320.jpg)
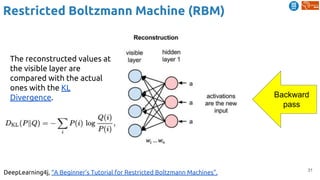
![53
Predictive Learning
Srivastava, Nitish, Elman Mansimov, and Ruslan Salakhutdinov. "Unsupervised Learning of Video
Representations using LSTMs." In ICML 2015. [Github]
Learning video representations (features) by...
(2) frame prediction](https://image.slidesharecdn.com/dlai2018d4l2learningwithoutannotations-181016102255/85/Deep-Learning-without-Annotations-Xavier-Giro-UPC-Barcelona-2018-53-320.jpg)
![54
Predictive Learning
Srivastava, Nitish, Elman Mansimov, and Ruslan Salakhutdinov. "Unsupervised Learning of Video
Representations using LSTMs." In ICML 2015. [Github]
Unsupervised learned features (lots of data) are
fine-tuned for activity recognition (small data).](https://image.slidesharecdn.com/dlai2018d4l2learningwithoutannotations-181016102255/85/Deep-Learning-without-Annotations-Xavier-Giro-UPC-Barcelona-2018-54-320.jpg)
![55
Predictive Learning
Mathieu, Michael, Camille Couprie, and Yann LeCun. "Deep multi-scale video prediction beyond mean square error."
ICLR 2016 [project] [code]
Video frame prediction with a ConvNet.](https://image.slidesharecdn.com/dlai2018d4l2learningwithoutannotations-181016102255/85/Deep-Learning-without-Annotations-Xavier-Giro-UPC-Barcelona-2018-55-320.jpg)
![56
Predictive Learning
Mathieu, Michael, Camille Couprie, and Yann LeCun. "Deep multi-scale video prediction beyond mean square error."
ICLR 2016 [project] [code]
The blurry predictions from MSE are improved with multi-scale architecture,
adversarial learning and an image gradient difference loss function.](https://image.slidesharecdn.com/dlai2018d4l2learningwithoutannotations-181016102255/85/Deep-Learning-without-Annotations-Xavier-Giro-UPC-Barcelona-2018-56-320.jpg)
![57
Predictive Learning
Mathieu, Michael, Camille Couprie, and Yann LeCun. "Deep multi-scale video prediction beyond mean square error."
ICLR 2016 [project] [code]
The blurry predictions from MSE (l1) are improved with multi-scale architecture,
adversarial training and an image gradient difference loss (GDL) function.](https://image.slidesharecdn.com/dlai2018d4l2learningwithoutannotations-181016102255/85/Deep-Learning-without-Annotations-Xavier-Giro-UPC-Barcelona-2018-57-320.jpg)
![58
Predictive Learning
Mathieu, Michael, Camille Couprie, and Yann LeCun. "Deep multi-scale video prediction beyond mean square error."
ICLR 2016 [project] [code]](https://image.slidesharecdn.com/dlai2018d4l2learningwithoutannotations-181016102255/85/Deep-Learning-without-Annotations-Xavier-Giro-UPC-Barcelona-2018-58-320.jpg)


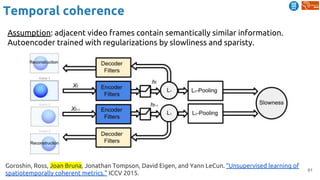
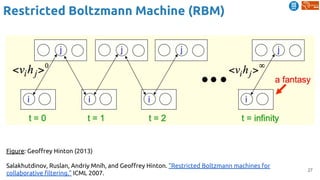
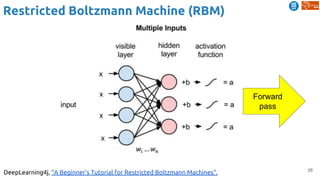
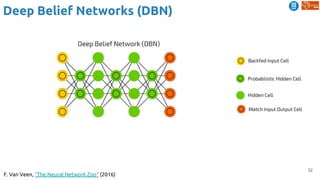
![62
Temporal coherence
Jayaraman, Dinesh, and Kristen Grauman. "Slow and steady feature analysis: higher order temporal
coherence in video." CVPR 2016. [video]
Slow feature analysis
● Temporal coherence assumption: features
should change slowly over time in video
Steady feature analysis
● Second order changes also small: changes in
the past should resemble changes in the future
Train on triplets of frames from video
Loss encourages nearby frames to have slow
and steady features, and far frames to have
different features](https://image.slidesharecdn.com/dlai2018d4l2learningwithoutannotations-181016102255/85/Deep-Learning-without-Annotations-Xavier-Giro-UPC-Barcelona-2018-62-320.jpg)
![63
Temporal coherence
(Slides by Xunyu Lin): Misra, Ishan, C. Lawrence Zitnick, and Martial Hebert. "Shuffle and learn: unsupervised learning using
temporal order verification." ECCV 2016. [code]
Temporal order of frames is
exploited as the supervisory
signal for learning.](https://image.slidesharecdn.com/dlai2018d4l2learningwithoutannotations-181016102255/85/Deep-Learning-without-Annotations-Xavier-Giro-UPC-Barcelona-2018-63-320.jpg)
![64
Temporal coherence
(Slides by Xunyu Lin): Misra, Ishan, C. Lawrence Zitnick, and Martial Hebert. "Shuffle and learn: unsupervised learning using
temporal order verification." ECCV 2016. [code]
Take temporal order as the supervisory signals for learning
Shuffled
sequences
Binary classification
In order
Not in order](https://image.slidesharecdn.com/dlai2018d4l2learningwithoutannotations-181016102255/85/Deep-Learning-without-Annotations-Xavier-Giro-UPC-Barcelona-2018-64-320.jpg)
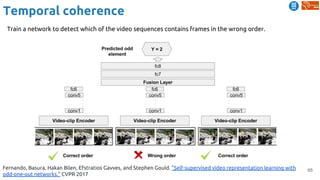

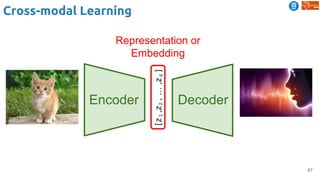


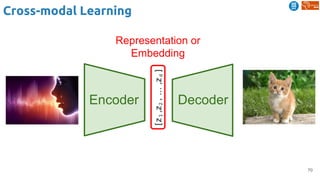
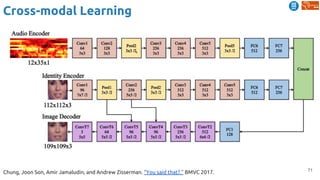

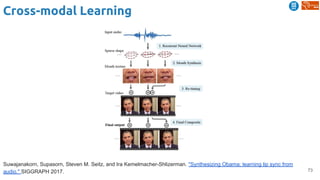

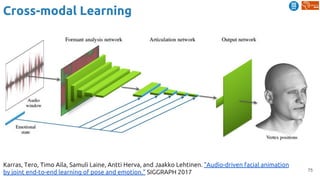

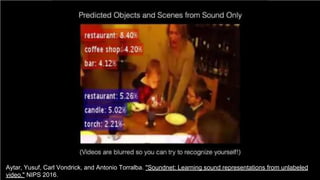
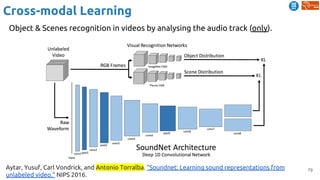
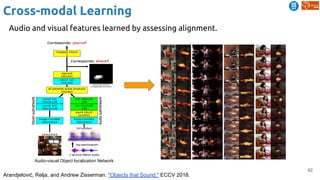
![83
Cross-modal Learning
Harwath, David, Antonio Torralba, and James Glass. "Unsupervised learning of spoken language with visual
context." NIPS 2016. [talk]
Train a visual & speech networks with pairs of (non-)corresponding images & speech.](https://image.slidesharecdn.com/dlai2018d4l2learningwithoutannotations-181016102255/85/Deep-Learning-without-Annotations-Xavier-Giro-UPC-Barcelona-2018-83-320.jpg)
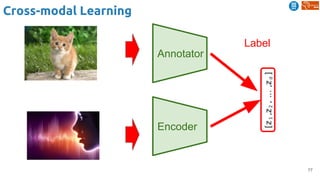
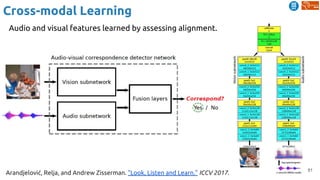
![84
Cross-modal Learning
Harwath, David, Antonio Torralba, and James Glass. "Unsupervised learning of spoken language with visual
context." NIPS 2016. [talk]
Similarity curve show which regions of the spectrogram are relevant for the image.
Important: no text transcriptions used during the training !!](https://image.slidesharecdn.com/dlai2018d4l2learningwithoutannotations-181016102255/85/Deep-Learning-without-Annotations-Xavier-Giro-UPC-Barcelona-2018-84-320.jpg)



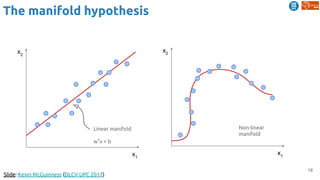
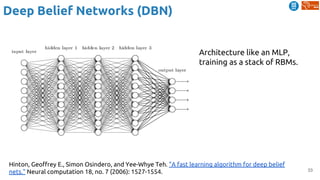
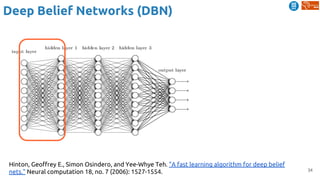
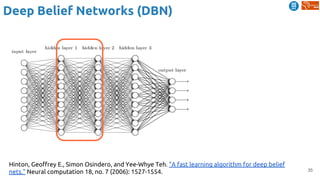
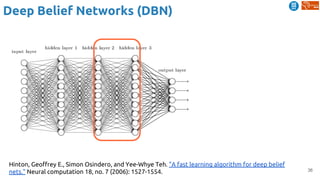
The document outlines various learning procedures in machine learning, including unsupervised, semi-supervised, and self-supervised learning, emphasizing the importance of these methods in leveraging unlabelled data. Key topics include the assumptions required for unsupervised learning, such as the manifold hypothesis and various frameworks like autoencoders and deep belief networks. It also discusses advanced concepts such as predictive learning and cross-modal learning for video representation and action recognition.















































































