Download to read offline










![12
01
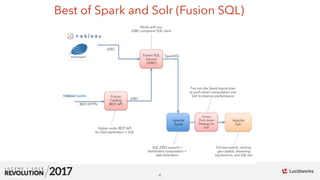
Fusion SQL
sort(
select(
rollup(
facet(
time_on_site_logs,
q="dashboard_id:[* TO *]",
buckets="dashboard_id,user_id",
bucketSizeLimit=10000,
bucketSorts="dashboard_id asc",
count(*)
),
over="dashboard_id",
count(*)
),
dashboard_id, count(*) as ct
),
by="ct desc"
)
select distinct_logs.dashboard_id,
count(1) as ct
from (
select distinct dashboard_id, user_id
from time_on_site_logs
) as distinct_logs
group by distinct_logs.dashboard_id](https://image.slidesharecdn.com/dataanalyticssparksolrkiranchitturirevolution2017-170918171341/85/Faster-Data-Analytics-with-Apache-Spark-using-Apache-Solr-12-320.jpg)

![14
01
Fusion SQL (timestamp pushdown)
q=*:*&rows=5000&qt=/export&fl=host_s,port_s&fq=timestamp_tdt:
{2017-08-31T00:00:00.00Z+TO+*]&sort=id+asc&collection=logs
SELECT host_s, port_s from logs WHERE timestamp_tdt > '2017-08-31';](https://image.slidesharecdn.com/dataanalyticssparksolrkiranchitturirevolution2017-170918171341/85/Faster-Data-Analytics-with-Apache-Spark-using-Apache-Solr-14-320.jpg)

![17
01
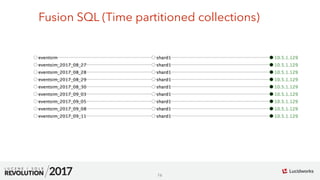
Fusion SQL (Time partitioned collections)
q=*:*&rows=5000&qt=/export&fl=song_s,gender_s&sort=id+asc
&fq=ts_dt{2017-09-10T00:00:00.00Z+TO+*]&collection=eventsim_2017_09_11
SELECT song_s, gender_s FROM eventsim WHERE ts_dt > '2017-09-10';](https://image.slidesharecdn.com/dataanalyticssparksolrkiranchitturirevolution2017-170918171341/85/Faster-Data-Analytics-with-Apache-Spark-using-Apache-Solr-17-320.jpg)

![19
01
Plugging in Custom strategies
sqlContext.experimental.extraStrategies ++= Seq(new
SpecialPushdownStrategy)
class SpecialPushdownStrategy extends Strategy {
def apply(plan: LogicalPlan): Seq[SparkPlan] = plan match {
case Aggregate(Nil,
Seq(Alias(AggregateExpression(Count(Seq(IntegerLiteral(n))),
_, _, _), name)), child) => {
// Form a Solr query, get numFound and return a
SparkPlan object
}
}
}](https://image.slidesharecdn.com/dataanalyticssparksolrkiranchitturirevolution2017-170918171341/85/Faster-Data-Analytics-with-Apache-Spark-using-Apache-Solr-19-320.jpg)


The document discusses the integration of Apache Spark and Apache Solr for enhanced data analytics, highlighting the performance of Fusion SQL in comparison to traditional databases through various experiments. It emphasizes the capabilities and limitations of Solr SQL, such as the lack of support for complex joins and analytical tool compatibility. Additionally, it explores Spark SQL's features, including a robust query optimizer and the ability to handle diverse data sources.



































































