Downloaded 32 times






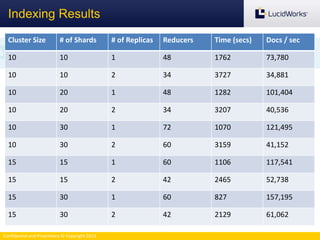
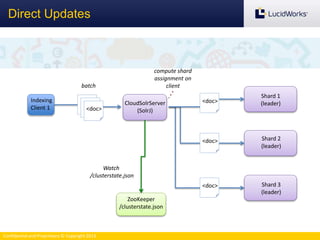
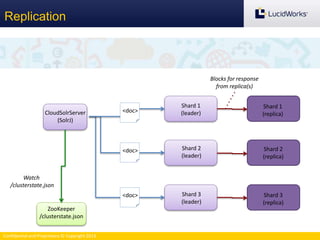
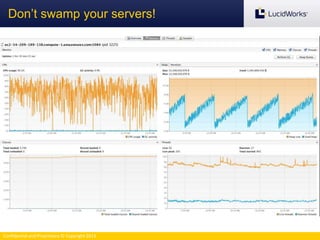













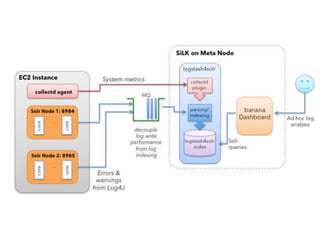


The document discusses benchmarking the performance of SolrCloud clusters. It describes Timothy Potter's experience operating a large SolrCloud cluster at Dachis Group. It outlines an methodology for benchmarking indexing performance by varying the number of servers, shards, and replicas. Results show near-linear scalability as nodes are added. The document also introduces the Solr Scale Toolkit for deploying and managing SolrCloud clusters using Python and AWS. It demonstrates integrating Solr with tools like Logstash and Kibana for log aggregation and dashboards.





















































![[Hic2011] using hadoop lucene-solr-for-large-scale-search by systex](https://cdn.slidesharecdn.com/ss_thumbnails/hic2011usinghadoop-lucene-solr-for-large-scale-searchbysystex-111205021544-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)





















































