Downloaded 71 times






![9
©
Cloudera,
Inc.
All
rights
reserved.
Simple
JSON
Facet
request
and
response
curl
http://localhost:8983/solr/query
-‐d
'
q=widgets&
json.facet=
{
x
:
"avg(price)"
,
y
:
"unique(brand)"
}
'
[…]
"facets"
:
{
"count"
:
314,
"x"
:
102.5,
"y"
:
28
}
root
domain
defined
by
docs
matching
the
query
count
of
docs
in
the
bucket](https://image.slidesharecdn.com/yonikeseeleyparallelsqlanalyticslucenesolrrev2016-161031200627/85/Parallel-SQL-and-Analytics-with-Solr-Presented-by-Yonik-Seeley-Cloudera-9-320.jpg)

![11
©
Cloudera,
Inc.
All
rights
reserved.
Sub-‐facet
example
json.facet={
shoes:{
type
:
terms,
field
:
shoe_style,
sort
:
{x
:
desc},
facet
:
{
x
:
"avg(price)",
y
:
"unique(brand)",
colors
:
{
type
:
terms,
field
:
color
}
}
}
}
"facets":
{
"count"
:
472,
"shoes":
{
"buckets"
:
[
{
"val"
:
"Hiking",
"count"
:
34,
"x"
:
135.25,
"y"
:
17,
"colors"
:
{
"buckets"
:
[
{
"val"
:
"brown",
"count"
:
12
},
{
"val"
:
"black",
"count"
:
10
},
[…]
]
}
//
end
of
colors
sub-‐facet
},
//
end
of
Hiking
bucket
{
"val"
:
"Running",
"count"
:
45,
"x"
:
110.75,
"y"
:
24,
"colors"
:
{
"buckets"
:
[…]](https://image.slidesharecdn.com/yonikeseeleyparallelsqlanalyticslucenesolrrev2016-161031200627/85/Parallel-SQL-and-Analytics-with-Solr-Presented-by-Yonik-Seeley-Cloudera-11-320.jpg)



![15
©
Cloudera,
Inc.
All
rights
reserved.
search()
expression
$
curl
hFp://localhost:8983/solr/techproducts/stream
-‐d
'expr=search(techproducts,
q="*:*",
fl="id,price,score",
sort="id
asc")'
{"result-‐set":{"docs":[
{"score":1.0,"id":"0579B002","price":179.99},
{"score":1.0,"id":"100-‐435805","price":649.99},
{"score":1.0,"id":"3007WFP","price":2199.0},
{"score":1.0,"id":"VDBDB1A16"},
{"score":1.0,"id":"VS1GB400C3","price":74.99},
{"EOF":true,"RESPONSE_TIME":6}]}}
resulLng
tuple
stream](https://image.slidesharecdn.com/yonikeseeleyparallelsqlanalyticslucenesolrrev2016-161031200627/85/Parallel-SQL-and-Analytics-with-Solr-Presented-by-Yonik-Seeley-Cloudera-15-320.jpg)

![18
©
Cloudera,
Inc.
All
rights
reserved.
rollup()
expression
• Groups
tuples
by
common
field
values
• Emits
rollup
value
along
with
metrics
• Closest
equivalent
to
face.ng
rollup(
search(collecLon1,
qt="/export"
q="*:*",
fl="id,manu,price",
sort="manu
asc"),
over="manu"),
count(*),
max(price)
)
metrics
{"result-‐set":{"docs":[
{"manu":"apple","count(*)":1.0},
{"manu":"asus","count(*)":1.0},
{"manu":"aL","count(*)":1.0},
{"manu":"belkin","count(*)":2.0},
{"manu":"canon","count(*)":2.0},
{"manu":"corsair","count(*)":3.0},
[...]](https://image.slidesharecdn.com/yonikeseeleyparallelsqlanalyticslucenesolrrev2016-161031200627/85/Parallel-SQL-and-Analytics-with-Solr-Presented-by-Yonik-Seeley-Cloudera-18-320.jpg)



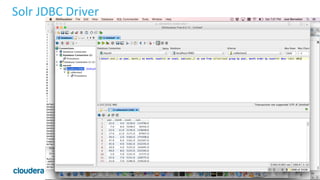
![23
©
Cloudera,
Inc.
All
rights
reserved.
jdbc()
expression
stream
join
with
other
data
sources!
innerJoin(
select(
search(collecLon1,
[...]),
personId_i
as
personId,
raLng_f
as
raLng
),
select(
jdbc(connecLon="jdbc:hsqldb:mem:.",
sql="select
PEOPLE.ID
as
PERSONID,
PEOPLE.NAME,
COUNTRIES.COUNTRY_NAME
from
PEOPLE
inner
join
COUNTRIES
on
PEOPLE.COUNTRY_CODE
=
COUNTRIES.CODE
order
by
PEOPLE.ID",
sort="ID
asc",
get_column_name=true),
ID
as
personId,
NAME
as
personName,
COUNTRY_NAME
as
country
),
on="personId"
)](https://image.slidesharecdn.com/yonikeseeleyparallelsqlanalyticslucenesolrrev2016-161031200627/85/Parallel-SQL-and-Analytics-with-Solr-Presented-by-Yonik-Seeley-Cloudera-23-320.jpg)


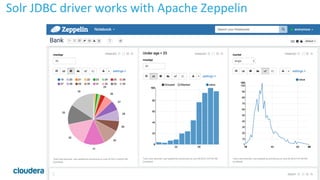
![27
©
Cloudera,
Inc.
All
rights
reserved.
Simplest
SQL
Example
$
curl
hFp://localhost:8983/solr/techproducts/sql
-‐d
"stmt=select
id
from
techproducts"
{"result-‐set":{"docs":[
{"id":"EN7800GTX/2DHTV/256M"},
{"id":"100-‐435805"},
{"id":"UTF8TEST"},
{"id":"SOLR1000"},
{"id":"9885A004"},
[...]
tables
map
to
collecLons](https://image.slidesharecdn.com/yonikeseeleyparallelsqlanalyticslucenesolrrev2016-161031200627/85/Parallel-SQL-and-Analytics-with-Solr-Presented-by-Yonik-Seeley-Cloudera-27-320.jpg)

![29
©
Cloudera,
Inc.
All
rights
reserved.
The
WHERE
clause
• WHERE
clauses
are
all
pushed
down
to
the
search
layer
select
id
where
popularity=10
//
simple
match
on
numeric
field
"popularity"
where
popularity='[5
TO
10]'
//
solr
range
query
(note
the
quotes)
where
name='hard
drive'
//
phrase
query
on
the
"name"
field
where
name='((memory
retail)
AND
popularity:[5
TO
10])'
//
arbitrary
solr
query
where
name='(memory
retail)'
AND
popularity='[5
TO
10]'
//
boolean
logic](https://image.slidesharecdn.com/yonikeseeleyparallelsqlanalyticslucenesolrrev2016-161031200627/85/Parallel-SQL-and-Analytics-with-Solr-Presented-by-Yonik-Seeley-Cloudera-29-320.jpg)



![35
©
Cloudera,
Inc.
All
rights
reserved.
Graph
Filter
• Follows
ad
hoc
edges
• Not
distributed!
• still
useable
on
partitioned
data
• Can
filter
on
each
hop
• Can
specify
max
depth
• Cycle
detection
fq={!graph
from=parents
to=id}
id:"Philip
J.
Fry"
id
:
"Philip
J.
Fry"
parents:["Yancy
Fry,
Sr.","Mrs.
Fry"]
id
:
"Yancy
Fry"
parents:["Yancy
Fry,
Sr.","Mrs.
Fry"]
id
:
"Yancy
Fry,
Sr."
parents:["Mildred,
"Philip
J.
Fry"]
id
:
"Mrs.
Fry"
parents:["Mr.
Gleisner",
"Mrs.
Gleisner"]
id
:
"Mildred"
id
:
"Hubert
J.
Farnsworth"
id
:
"Philip
J.
Fry"
parents:["Yancy
Fry,
Sr.","Mrs.
Fry"]
Cycle!](https://image.slidesharecdn.com/yonikeseeleyparallelsqlanalyticslucenesolrrev2016-161031200627/85/Parallel-SQL-and-Analytics-with-Solr-Presented-by-Yonik-Seeley-Cloudera-35-320.jpg)



![39
©
Cloudera,
Inc.
All
rights
reserved.
1.
Search
expression
to
find
my
high
raLngs
URL="http://localhost:8983/solr/reviews/stream"
#
Use
search
expression
to
find
reviews
that
I
have
the
book
a
"5"
curl
$URL
-‐d
'expr=search(reviews,
q="user_s:Yonik
AND
rating_i:5",
fl="id,book_s,user_s,rating_i",
sort="user_s
asc")'
{"result-‐set":{"docs":[
{"raLng_i":5,"id":"book2_r1","user_s":"Yonik","book_s":"book2"},
{"raLng_i":5,"id":"book1_r1","user_s":"Yonik","book_s":"book1"},
{"raLng_i":5,"id":"book12_r1","user_s":"Yonik","book_s":"book12"},
{"EOF":true,"RESPONSE_TIME":4}]}}](https://image.slidesharecdn.com/yonikeseeleyparallelsqlanalyticslucenesolrrev2016-161031200627/85/Parallel-SQL-and-Analytics-with-Solr-Presented-by-Yonik-Seeley-Cloudera-39-320.jpg)
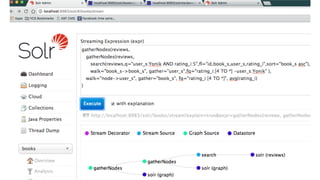
![40
©
Cloudera,
Inc.
All
rights
reserved.
2.
gatherNodes
expression
to
find
users
curl
$URL
-‐d
'expr=gatherNodes(reviews,
search(reviews,
q="user_s:Yonik
AND
rating_i:5",
fl="book_s,user_s,rating_i",sort="user_s
asc"),
walk="book_s-‐>book_s",
gather="user_s",
fq="rating_i:[4
TO
*]
-‐user_s:Yonik",
trackTraversal=true
)'
{"result-‐set":{"docs":[
{"node":"Haruka","collecLon":"reviews","field":"user_s","ancestors":["book1"],"level":1},
{"node":"Maria","collecLon":"reviews","field":"user_s","ancestors":["book2"],"level":1},
{"EOF":true,"RESPONSE_TIME":22}]}}
"gather"
values](https://image.slidesharecdn.com/yonikeseeleyparallelsqlanalyticslucenesolrrev2016-161031200627/85/Parallel-SQL-and-Analytics-with-Solr-Presented-by-Yonik-Seeley-Cloudera-40-320.jpg)
![41
©
Cloudera,
Inc.
All
rights
reserved.
3.
gatherNodes
to
find
high
raLngs
by
those
users
curl
$URL
-‐d
'expr=gatherNodes(reviews,
gatherNodes(reviews,
search(reviews,q="user_s:Yonik
AND
rating_i:
5",fl="id,book_s,user_s,rating_i",sort="user_s
asc"),
walk="book_s-‐>book_s",
gather="user_s",fq="rating_i:[4
TO
*]
-‐user_s:Yonik"),
walk="node-‐>user_s",
gather="book_s",
fq="rating_i:[4
TO
*]",
avg(rating_i),
trackTraversal=true)'
{"result-‐set":{"docs":[
{"node":"book10","avg(raLng_i)":5.0,"field":"book_s","level":
2,"collecLon":"reviews","ancestors":["Maria"]},
{"EOF":true,"RESPONSE_TIME":65}]}}](https://image.slidesharecdn.com/yonikeseeleyparallelsqlanalyticslucenesolrrev2016-161031200627/85/Parallel-SQL-and-Analytics-with-Solr-Presented-by-Yonik-Seeley-Cloudera-41-320.jpg)
![42
©
Cloudera,
Inc.
All
rights
reserved.
Retrieving
complete
traversal
curl
$URL
-‐d
'expr=gatherNodes(reviews,
[...],
scaFer="branches,leaves")'
{"result-‐set":{"docs":[
{"node":"book12","collecLon":"reviews","field":"book_s","level":0},
{"node":"book1","collecLon":"reviews","field":"book_s","level":0},
{"node":"book2","collecLon":"reviews","field":"book_s","level":0},
{"node":"Haruka","collecLon":"reviews","field":"user_s","level":1},
{"node":"Maria","collecLon":"reviews","field":"user_s","level":1},
{"node":"book10","avg(raLng_i)":5.0,"field":"book_s","level":2,
"collecLon":"reviews","ancestors":["Maria"]},
{"EOF":true,"RESPONSE_TIME":111}]}}](https://image.slidesharecdn.com/yonikeseeleyparallelsqlanalyticslucenesolrrev2016-161031200627/85/Parallel-SQL-and-Analytics-with-Solr-Presented-by-Yonik-Seeley-Cloudera-42-320.jpg)

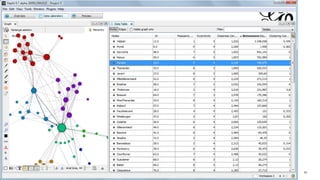
![45
©
Cloudera,
Inc.
All
rights
reserved.
Network
analysis
and
visualizaLon
curl
http://localhost:8983/solr/reviews/graph
-‐d
'expr=gatherNodes(reviews,
[...],
scaFer="branches,leaves")'
<?xml
version="1.0"
encoding="UTF-‐8"?>
<graphml
xmlns="hFp://graphml.graphdrawing.org/xmlns"
xmlns:xsi="hFp://www.w3.org/2001/XMLSchema-‐instance"
xsi:schemaLocaLon="hFp://graphml.graphdrawing.org/xmlns
hFp://graphml.graphdrawing.org/xmlns/1.0/
graphml.xsd">
<graph
id="G"
edgedefault="directed">
<node
id="book12">
<data
key="field">book_s</data>
<data
key="level">0</data>
</node>
<node
id="book1">
<data
key="field">book_s</data>
[...]](https://image.slidesharecdn.com/yonikeseeleyparallelsqlanalyticslucenesolrrev2016-161031200627/85/Parallel-SQL-and-Analytics-with-Solr-Presented-by-Yonik-Seeley-Cloudera-45-320.jpg)




The document discusses Apache Solr, an open-source search platform. It provides an overview of Solr's capabilities including search, faceting, analytics and its use by major Hadoop vendors. It then describes different methods for calculating statistics and facets in Solr, including the JSON Facet API, which provides a powerful and flexible way to generate aggregated results and sub-facets within search responses.






































![Query Understanding at LinkedIn [Talk at Facebook]](https://cdn.slidesharecdn.com/ss_thumbnails/8c193eb7-3e7f-4ce4-8517-ee9ae67ab9de-160410073847-thumbnail.jpg?width=640&height=640&fit=bounds)



































![[Webinar] Intelligent Policing. Leveraging Data to more effectively Serve Com...](https://cdn.slidesharecdn.com/ss_thumbnails/insightdrivenpolicingv2-201027222903-thumbnail.jpg?width=640&height=640&fit=bounds)
































