





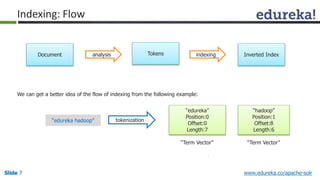
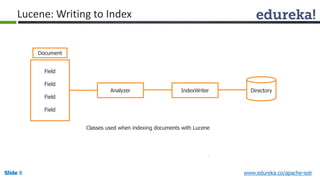
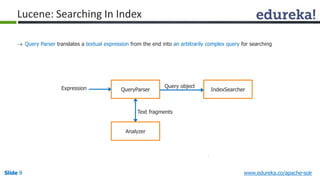
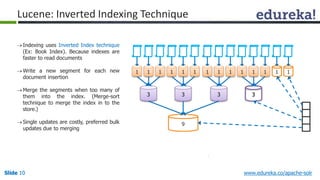




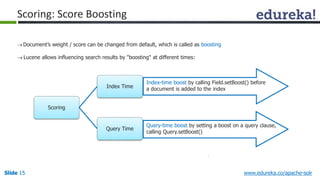

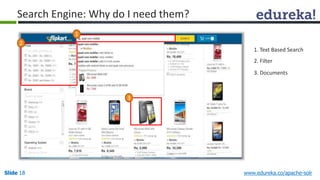



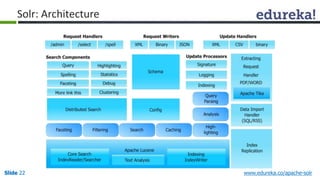
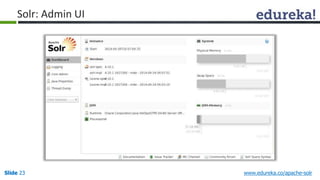
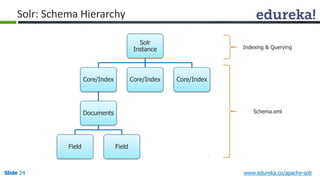





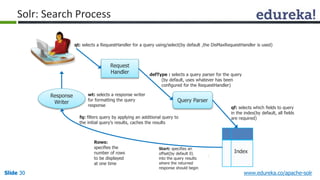

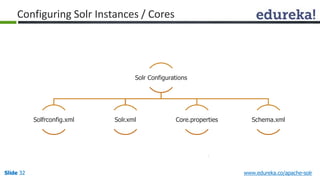


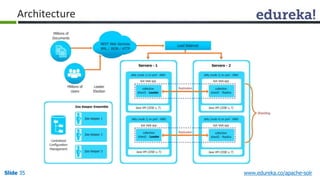
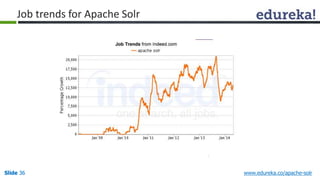






The document provides an introduction to Apache Solr, an open source enterprise search platform. It outlines the objectives of the training, which are to understand the need for enterprise search, how indexing and searching works in Lucene and Solr, Solr features like faceting and highlighting, and job opportunities for Solr developers. The training will cover topics such as Solr architecture, indexing, querying, analysis, and configuration using solrconfig.xml.























































































