Downloaded 132 times











![Streaming Expression Request - search
curl -d 'expr=search(gettingstarted,
q="*:*",
fl=“id, manu_exact”,
sort=“manu_exact asc")' http://localhost:8983/solr/gettingstarted/stream
{
"result-set": {
"docs": [
{"manu_exact": "A-DATA Technology Inc.”, "id": "VDBDB1A16"},
{"manu_exact": "ASUS Computer Inc.”, "id": "EN7800GTX/2DHTV/256M"},
{"manu_exact": "ATI Technologies”, "id": "100-435805"}
…
{"EOF": true,"RESPONSE_TIME": 15}]
}
}](https://image.slidesharecdn.com/whats-new-in-solr-6-160316220243/75/Webinar-What-s-New-in-Solr-6-12-2048.jpg)

![Streaming Expression Response
{“result-set":
{"docs":[
{"id":"0380014300","group":[{"id":"0380014300"},{"id":"0553573403"}]},
{"manu_exact":"A-DATA Technology Inc.","id":"VDBDB1A16","group":[{"manu_exact":"A-DATA Technology
Inc.","id":"VDBDB1A16"}]},
{"manu_exact":"Apache Software Foundation","id":"UTF8TEST","group":[{"manu_exact":"Apache Software
Foundation","id":"UTF8TEST"},{"manu_exact":"Apache Software Foundation","id":"SOLR1000"}]},
{"manu_exact":"Apple Computer Inc.","id":"MA147LL/A","group":[{"manu_exact":"Apple Computer
Inc.","id":"MA147LL/A"}]},
{"manu_exact":"Bank of America","id":"USD","group":[{"manu_exact":"Bank of America","id":"USD"}]},
{"manu_exact":"Bank of Norway","id":"NOK","group":[{"manu_exact":"Bank of Norway","id":"NOK"}]},
{"manu_exact":"Canon Inc.","id":"9885A004","group":[{"manu_exact":"Canon Inc.","id":"9885A004"},
{"manu_exact":"Canon Inc.","id":"0579B002"}]},
{"manu_exact":"Corsair Microsystems Inc.","id":"VS1GB400C3","group":[{"manu_exact":"Corsair Microsystems
Inc.","id":"VS1GB400C3"},{"manu_exact":"Corsair Microsystems Inc.","id":"TWINX2048-3200PRO"}]},
{"manu_exact":"Dell, Inc.","id":"3007WFP","group":[{"manu_exact":"Dell, Inc.","id":"3007WFP"}]},
{“EOF":true,"RESPONSE_TIME":24}]}
}](https://image.slidesharecdn.com/whats-new-in-solr-6-160316220243/75/Webinar-What-s-New-in-Solr-6-15-2048.jpg)


![SQL Syntax
• SELECT and SELECT DISTINCT
• select id, manu_exact from techproducts
• select distinct id, manu_exact from techproducts
• WHERE
• select id, manu_exact from techproducts where inStock=true
• select id, manu_exact from techproducts order where price=‘[10 TO 50]’
• select id, manu_exact from techproducts where cat=‘(electronics or music)’](https://image.slidesharecdn.com/whats-new-in-solr-6-160316220243/75/Webinar-What-s-New-in-Solr-6-19-2048.jpg)


![SQL Statement and Results
{"result-set":
{"docs":[
{"manu_exact":"A-DATA Technology Inc.","id":"VDBDB1A16"},
{"manu_exact":"Apache Software Foundation","id":"SOLR1000"},
{"manu_exact":"Apache Software Foundation","id":"UTF8TEST"},
{"manu_exact":"Apple Computer Inc.","id":"MA147LL/A"},
{"manu_exact":"Bank of America","id":"USD"},
{"EOF":"true","RESPONSE_TIME":8}]
}
}
curl -d '&stmt=select id, manu_exact from techproducts where inStock='true' order by
manu_exact limit 5' http://localhost:8983/solr/techproducts/sql](https://image.slidesharecdn.com/whats-new-in-solr-6-160316220243/75/Webinar-What-s-New-in-Solr-6-22-2048.jpg)












![{
"schema":{
"name":"example",
"version":1.6,
"uniqueKey":"id",
"fieldTypes":[{
"name":"_bbox_coord",
"class":"solr.TrieDoubleField",
"stored":false,
"docValues":true,
“precisionStep":"8"}],
"fields":[{
"name":"_root_",
"type":"string",
"indexed":true,
"stored":false},
{
"name":"_src_",
"type":"string",
"indexed":false,
"stored":true},
{
"name":"_version_",
"type":"long",
"indexed":true,
“stored”:true}]
}
}
http://localhost:8983/solr/v2/cores/techproducts/schema
truncated response](https://image.slidesharecdn.com/whats-new-in-solr-6-160316220243/75/Webinar-What-s-New-in-Solr-6-37-2048.jpg)
![{
"spec": [{
"documentation": "https://cwiki.apache.org/confluence/display/solr/Schema+API",
"methods": ["POST"],
"url": {
"paths": ["$handlerName"]
},
"commands": {
"add-field": {
"properties": {},
"additionalProperties": true
},
"delete-field": {
"additionalProperties": true
}
}
}, {
"documentation": "https://cwiki.apache.org/confluence/display/solr$handlerName+API",
"methods": ["GET"],
"url": {
"paths": ["$handlerName", "$handlerName/name", "$handlerName/uniquekey", "$handlerName/version", "$handlerName/similarity",
"$handlerName/solrqueryparser", "$handlerName/zkversion", "$handlerName/zkversion", "$handlerName/solrqueryparser/defaultoperator",
"$handlerName/name", "$handlerName/version", "$handlerName/uniquekey", "$handlerName/similarity", "$handlerName/similarity"]
},
"body": null
}]
}
http://localhost:8983/solr/v2/cores/techproducts/schema/_introspect
truncated response](https://image.slidesharecdn.com/whats-new-in-solr-6-160316220243/75/Webinar-What-s-New-in-Solr-6-38-2048.jpg)

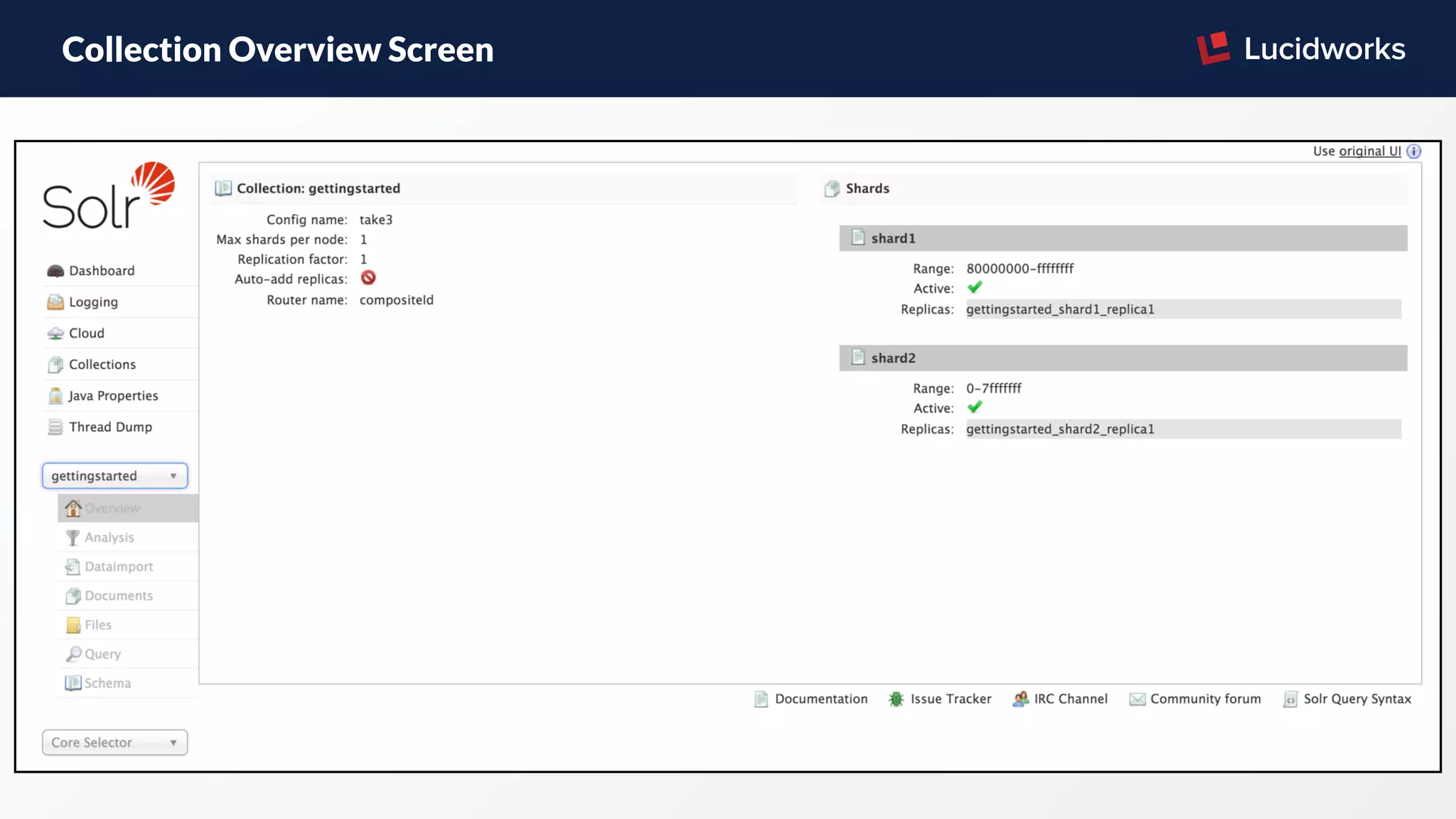









The document discusses features and improvements in Solr 6, highlighting its scalability, security, and user-friendliness built on Solr 5's enhancements. Key new functionalities include parallel SQL support, cross data center replication, and graph traversal capabilities, alongside a modernized API. It also outlines best practices for using Solr with the new features, warnings about limitations, and references to further resources.





















































![[Webinar] Intelligent Policing. Leveraging Data to more effectively Serve Com...](https://cdn.slidesharecdn.com/ss_thumbnails/insightdrivenpolicingv2-201027222903-thumbnail.jpg?width=640&height=640&fit=bounds)




















![Vibe Coding vs. Spec-Driven Development [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/vibecodingvsspecdrivendevelopment-251209105622-43f455e7-thumbnail.jpg?width=640&height=640&fit=bounds)












