Copyright@2014 NTT DATAMathematical Systems Inc.
8
人間はアナロジー関係を適切にとらえる ことができます。 Skip-gramに代表される言語モデルの進化 により、このようなアナロジー関係をあ る程度機械的に計算できるようになりま した。
9.
Copyright@2014 NTT DATAMathematical Systems Inc.
9
Skip-gram モデル(+ Noise Sampling)
•T. Mikolov+, “Distributed Representations of Words and Phrases and their Compositionality”, NIPS2013
•Skip-gram モデルは、単語に同じ次元のベクタを割り当てます(語 푢 に 割り当てられたベクタが 휃푢 )。
•コーパスで共起する単語ペア(푢,푣∼푃퐷)は、ベクタの内積が大きく なるようにします。
•コーパスの푘倍の個数の単語ペア(푢,푣∼푃푁)を別途作成しますが、 それらの単語ペアのベクタの内積は小さくなるようにします。
Skip-gram (+NS) maximize 휃 퐿(휃)=피푢,푣∼푃퐷[log푃(푢,푣;휃)]+푘피푢,푣∼푃푁log(1−푃(푢,푣;휃), 푤ℎ푒푟푒 푃푢,푣;휃=휎휃푢⋅휃푣 푠푖푔푚표푖푑 = 11+exp (−휃푢⋅휃푣)
10.
Copyright@2014 NTT DATAMathematical Systems Inc.
10
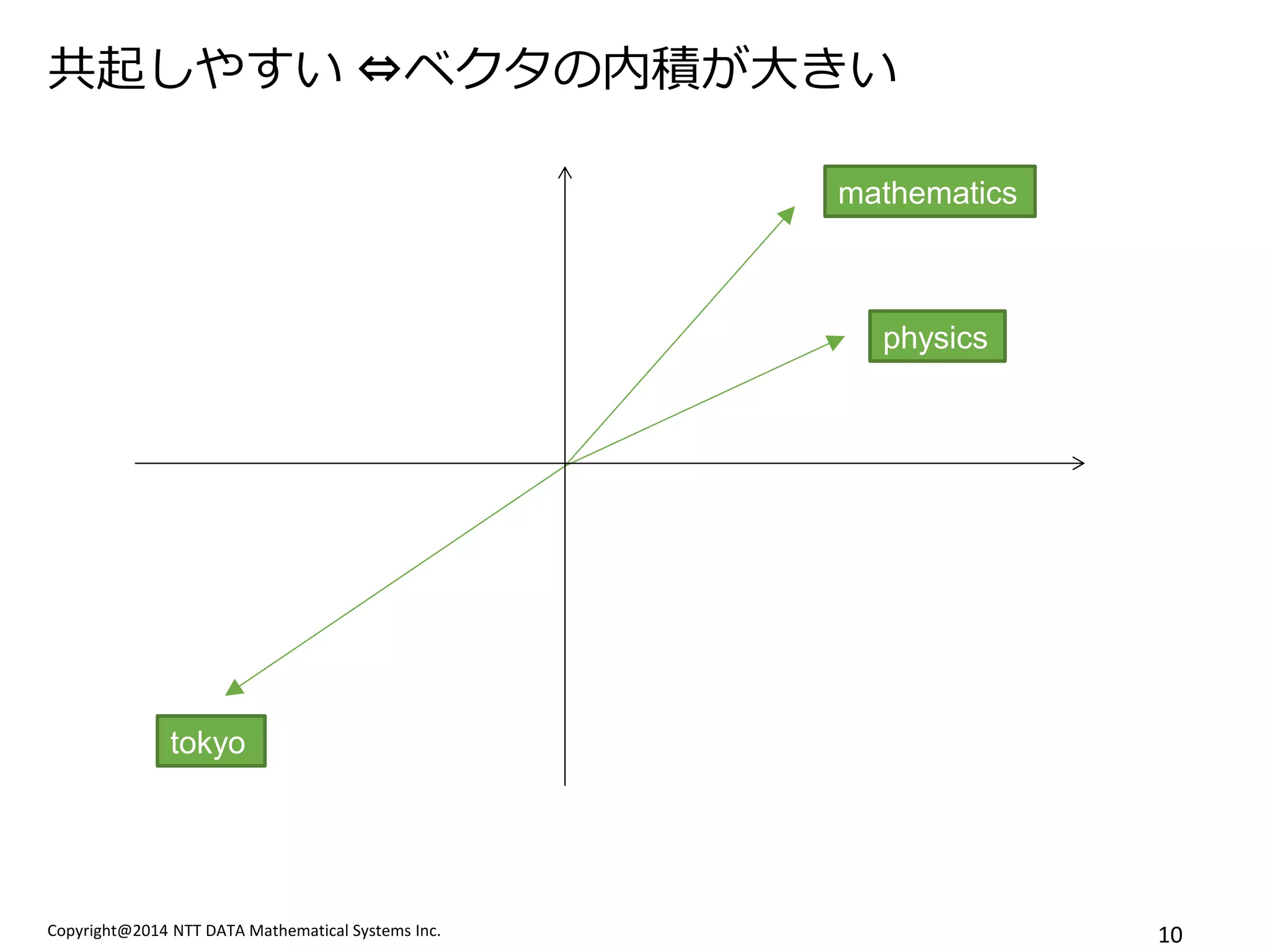
共起しやすい ⇔ベクタの内積が大きい
mathematics
physics
tokyo
11.
Copyright@2014 NTT DATAMathematical Systems Inc.
11
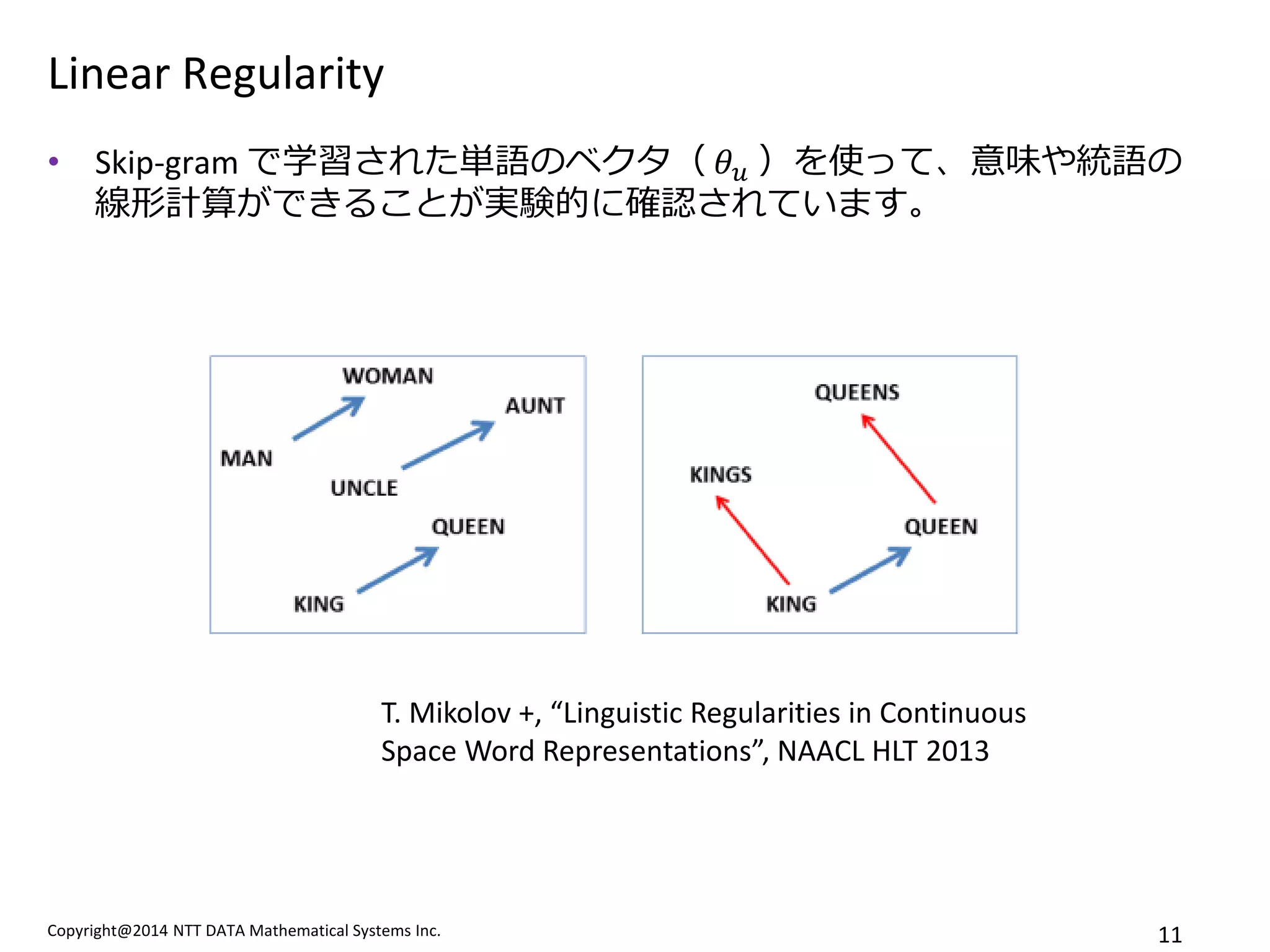
Linear Regularity
•Skip-gram で学習された単語のベクタ( 휃푢 )を使って、意味や統語の 線形計算ができることが実験的に確認されています。
T. Mikolov +, “Linguistic Regularities in Continuous Space Word Representations”, NAACL HLT 2013
12.
Copyright@2014 NTT DATAMathematical Systems Inc.
12
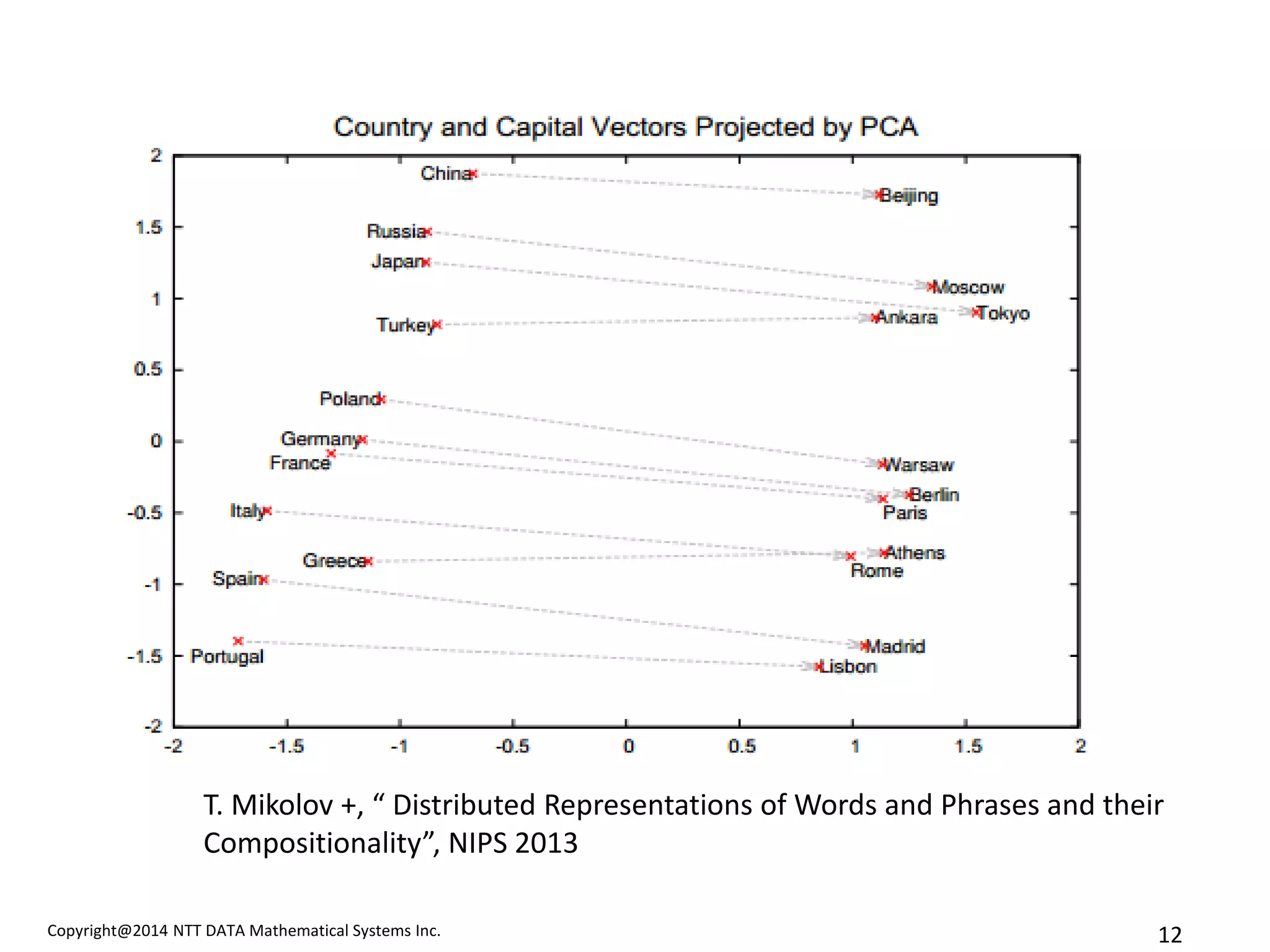
T. Mikolov +, “ Distributed Representations of Words and Phrases and their Compositionality”, NIPS 2013
13.
Copyright@2014 NTT DATAMathematical Systems Inc.
13
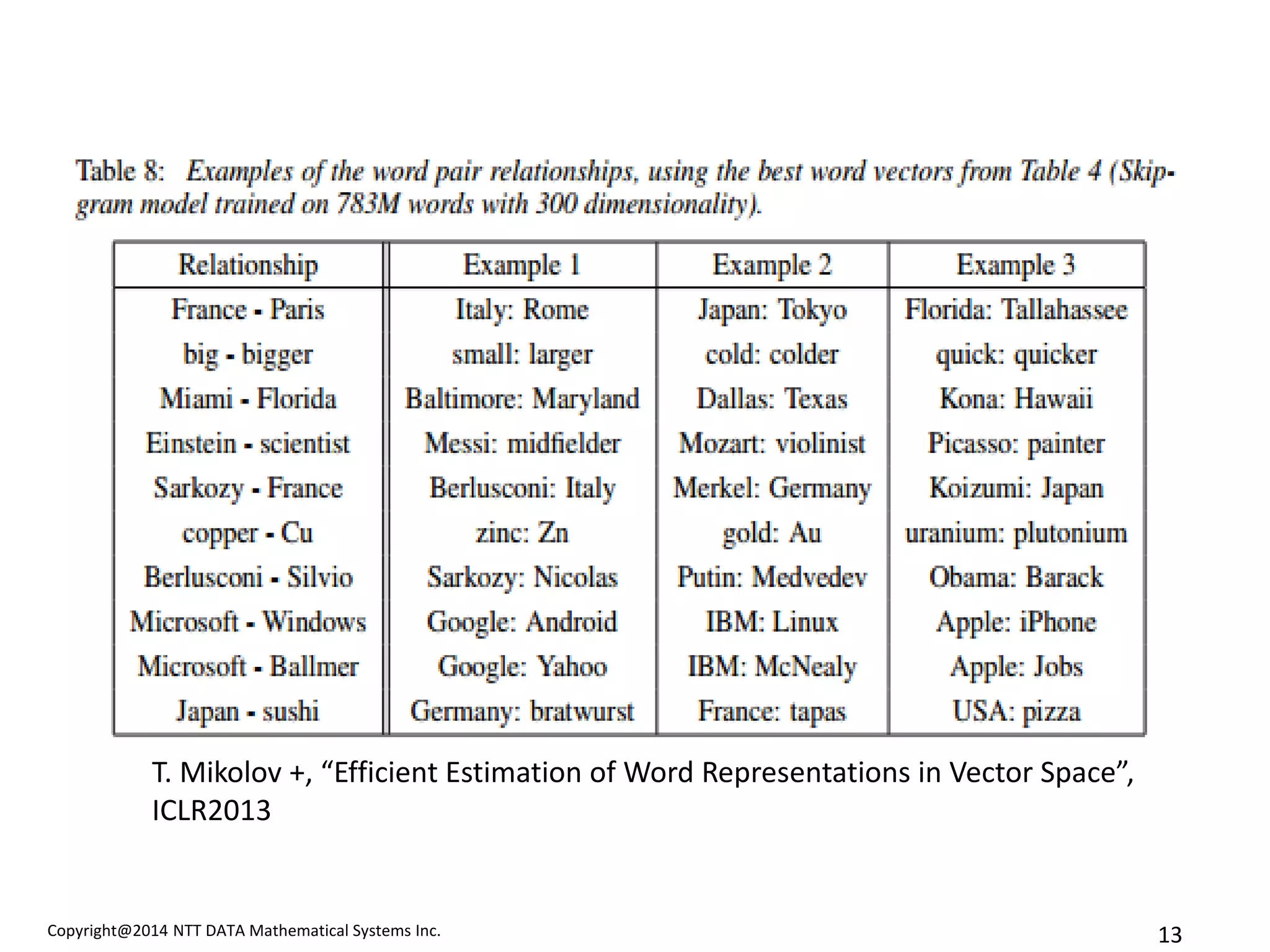
T. Mikolov +, “Efficient Estimation of Word Representations in Vector Space”, ICLR2013
14.
Copyright@2014 NTT DATAMathematical Systems Inc.
14
語の相対的な位置関係は言語非依存(?)
T. Mikolov +, “Exploiting Similarities among Languages for Machine Translation”, arXiv:1309.4168
15.
Copyright@2014 NTT DATAMathematical Systems Inc.
15
Skip-gram = PMI行列の行列分解
•最近、푘=1,푃푁(푢,푣)=푃퐷푢푃퐷푣 (ユニグラム分布の積)ととった Skip-gram モデルは PMI 行列の行列分解に相当することが示されました。
•O. Levy+, “Neural Word Embedding as Implecit Matrix Factorization”, NIPS2014
Skip-gram (+NS) maximize 휃 퐿(휃)=피푢,푣∼푃퐷[log푃(푢,푣;휃)]+푘피푢,푣∼푃푁log(1−푃(푢,푣;휃), 푤ℎ푒푟푒 푃푢,푣;휃=휎휃푢⋅휃푣 푠푖푔푚표푖푑 = 11+exp (−휃푢⋅휃푣)
푢
푣
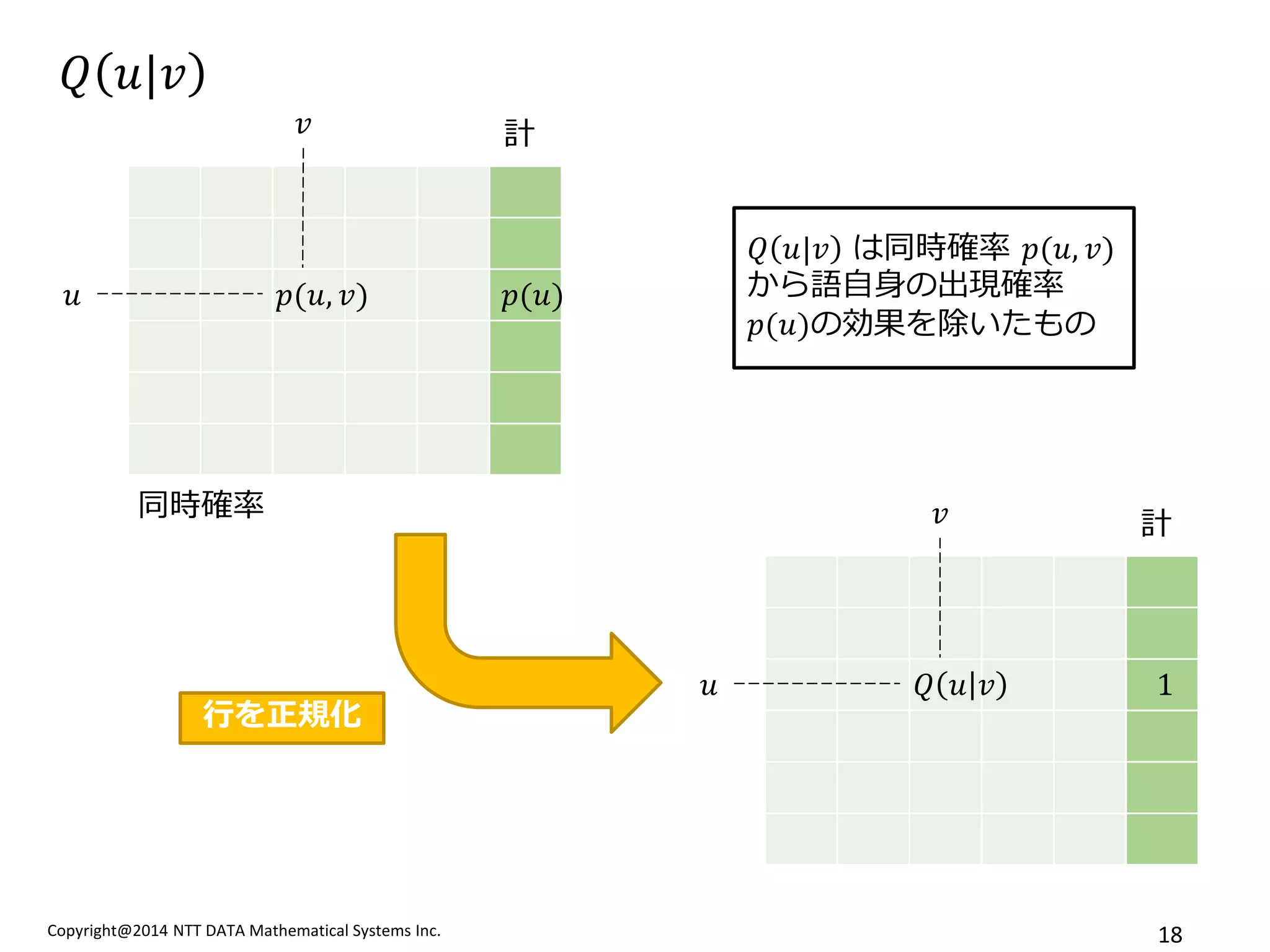
Pointwise Mutual Information
푃푀퐼푢,푣=log 푃퐷푢,푣 푃퐷푢푃퐷(푣)
PMI行列
16.
Copyright@2014 NTT DATAMathematical Systems Inc.
16
証明
下記の証明は、本質的には次の論文によるものです。 I. J. Goodfellow+, “Generative Adversarial Networks”, NIPS2014
(証明) 퐿(휃)=피푢,푣∼푃퐷[log푃(푢,푣;휃)]+푘피푢,푣∼푃푁log(1−푃(푢,푣;휃) = 푃퐷푢,푣log푃푢,푣;휃+푘푃푁푢,푣log1−푃푢,푣;휃 푑(푢,푣) ですが、푎log푥+푏log1−푥は푥=푎/(푎+푏)で唯一の最大値をとるので、 퐿(휃) を最大化すると、下記へ収束します。 푃푢,푣;휃= 푃퐷푢,푣 푃퐷푢,푣+푘푃푁(푢,푣) =휎−log 푃퐷푢,푣 푘푃푁푢,푣 푃푢,푣;휃=휎휃푢⋅휃푣と比べると 휃푢⋅휃푣=log 푃퐷푢,푣 푘푃푁푢,푣
を得ます。よって、푘=1,푃푁=푃퐷푢푃퐷푣 の場合には、PMI行列の分解 になります。








![Copyright@2014 NTT DATA Mathematical Systems Inc.
9
Skip-gram モデル(+ Noise Sampling)
•T. Mikolov+, “Distributed Representations of Words and Phrases and their Compositionality”, NIPS2013
•Skip-gram モデルは、単語に同じ次元のベクタを割り当てます(語 푢 に 割り当てられたベクタが 휃푢 )。
•コーパスで共起する単語ペア(푢,푣∼푃퐷)は、ベクタの内積が大きく なるようにします。
•コーパスの푘倍の個数の単語ペア(푢,푣∼푃푁)を別途作成しますが、 それらの単語ペアのベクタの内積は小さくなるようにします。
Skip-gram (+NS) maximize 휃 퐿(휃)=피푢,푣∼푃퐷[log푃(푢,푣;휃)]+푘피푢,푣∼푃푁log(1−푃(푢,푣;휃), 푤ℎ푒푟푒 푃푢,푣;휃=휎휃푢⋅휃푣 푠푖푔푚표푖푑 = 11+exp (−휃푢⋅휃푣)](https://image.slidesharecdn.com/skipgramshirakawa20141121-141120192449-conversion-gate01/75/Skip-gram-shirakawa_20141121-9-2048.jpg)

![Copyright@2014 NTT DATA Mathematical Systems Inc.
15
Skip-gram = PMI行列の行列分解
•最近、푘=1,푃푁(푢,푣)=푃퐷푢푃퐷푣 (ユニグラム分布の積)ととった Skip-gram モデルは PMI 行列の行列分解に相当することが示されました。
•O. Levy+, “Neural Word Embedding as Implecit Matrix Factorization”, NIPS2014
Skip-gram (+NS) maximize 휃 퐿(휃)=피푢,푣∼푃퐷[log푃(푢,푣;휃)]+푘피푢,푣∼푃푁log(1−푃(푢,푣;휃), 푤ℎ푒푟푒 푃푢,푣;휃=휎휃푢⋅휃푣 푠푖푔푚표푖푑 = 11+exp (−휃푢⋅휃푣)
푢
푣
Pointwise Mutual Information
푃푀퐼푢,푣=log 푃퐷푢,푣 푃퐷푢푃퐷(푣)
PMI行列](https://image.slidesharecdn.com/skipgramshirakawa20141121-141120192449-conversion-gate01/75/Skip-gram-shirakawa_20141121-15-2048.jpg)
![Copyright@2014 NTT DATA Mathematical Systems Inc.
16
証明
下記の証明は、本質的には次の論文によるものです。 I. J. Goodfellow+, “Generative Adversarial Networks”, NIPS2014
(証明) 퐿(휃)=피푢,푣∼푃퐷[log푃(푢,푣;휃)]+푘피푢,푣∼푃푁log(1−푃(푢,푣;휃) = 푃퐷푢,푣log푃푢,푣;휃+푘푃푁푢,푣log1−푃푢,푣;휃 푑(푢,푣) ですが、푎log푥+푏log1−푥は푥=푎/(푎+푏)で唯一の最大値をとるので、 퐿(휃) を最大化すると、下記へ収束します。 푃푢,푣;휃= 푃퐷푢,푣 푃퐷푢,푣+푘푃푁(푢,푣) =휎−log 푃퐷푢,푣 푘푃푁푢,푣 푃푢,푣;휃=휎휃푢⋅휃푣と比べると 휃푢⋅휃푣=log 푃퐷푢,푣 푘푃푁푢,푣
を得ます。よって、푘=1,푃푁=푃퐷푢푃퐷푣 の場合には、PMI行列の分解 になります。](https://image.slidesharecdn.com/skipgramshirakawa20141121-141120192449-conversion-gate01/75/Skip-gram-shirakawa_20141121-16-2048.jpg)




















![SSII2022 [TS1] Transformerの最前線〜 畳込みニューラルネットワークの先へ 〜](https://cdn.slidesharecdn.com/ss_thumbnails/ts120220608ssiitransformerr2-220607054025-3adacf07-thumbnail.jpg?width=640&height=640&fit=bounds)





![[DL輪読会]Learning Transferable Visual Models From Natural Language Supervision](https://cdn.slidesharecdn.com/ss_thumbnails/dlkobayashi0115-210115012308-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会]GENESIS: Generative Scene Inference and Sampling with Object-Centric L...](https://cdn.slidesharecdn.com/ss_thumbnails/20191206genesis-191206004127-thumbnail.jpg?width=640&height=640&fit=bounds)


![[第2回3D勉強会 研究紹介] Neural 3D Mesh Renderer (CVPR 2018)](https://cdn.slidesharecdn.com/ss_thumbnails/201807263dv-180728060959-thumbnail.jpg?width=640&height=640&fit=bounds)






![[NeurIPS2018読み会@PFN] On the Dimensionality of Word Embedding](https://cdn.slidesharecdn.com/ss_thumbnails/pfnonthedimensionalityofwordembedding-190126060357-thumbnail.jpg?width=640&height=640&fit=bounds)












