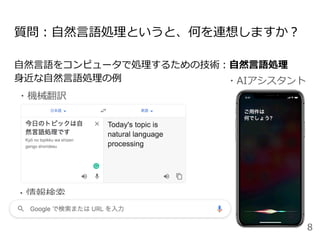
⾃然⾔語処理をもっと学びたい⼈に:参考資料
Stanford⼤学の講義資料
Natural Language Processingwith Deep Learning
動画・演習のソースコードも充実
http://web.stanford.edu/class/cs224n/
Speech and Language Processing
Dan Jurafsky and James H. Martin
https://web.stanford.edu/~jurafsky/slp3/
東⼯⼤岡崎先⽣の講義資料
https://chokkan.github.io/deeplearning/
最新の研究は、Twitterも情報源
(NLPerの多くはTwitterにいる:ハッシュタグは#NLProc)
4














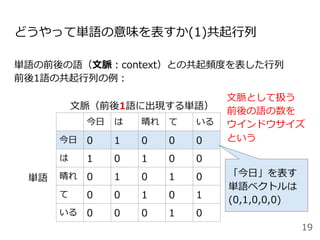
![分布仮説(distributional hypothesis)[Harris+, 1954]
単語の意味はその周囲の単語から形成されるという仮説
天気という単語は今⽇という単語と同時に出現しやすい(共起)
→単語の意味を周囲の単語との共起頻度で表現できそう
18
今⽇の天気は晴れである。
今⽇の1時間ごとの天気、気温、降⽔量を掲載します。
あなたが知りたい天気予報をお伝えします。
今⽇は天気が良いので布団を⼲した。](https://image.slidesharecdn.com/20200625-200703072256/85/2020-Deep-learning-9-18-320.jpg)
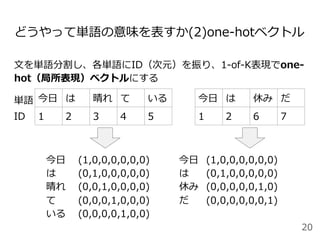



![● 分布仮説に基づき、埋め込み⾏列 を学習する⾔語モデル
● 周辺の単語から中⼼の単語を予測するCBOW (Continuous
Bag of Words)モデル(左)と、
ある単語が与えられた時にその周辺の単語を予測する
Skip-Gramモデル(右)から構成される
Word2Vec [Micolov+,2013]
⼊⼒
V次元
隠れ層
N次元
出⼒
V次元
⼊⼒
V次元
隠れ層
N次元
出⼒
V次元
V×N
次元
N×V
次元
N×V
次元
V×N
次元
24](https://image.slidesharecdn.com/20200625-200703072256/85/2020-Deep-learning-9-24-320.jpg)



![⽂脈を考慮した単語ベクトル:ELMo [Peters+2018]
⼤規模コーパス1B Word Benchmarkを⽤い、
⽂字レベルの双⽅向(left-to-right, right-to-left)2層LSTMで
前後の⽂脈を考慮した単語ベクトルの学習を実現
28
図は[Devlin+2019]から引⽤](https://image.slidesharecdn.com/20200625-200703072256/85/2020-Deep-learning-9-28-320.jpg)


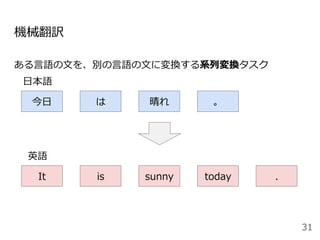
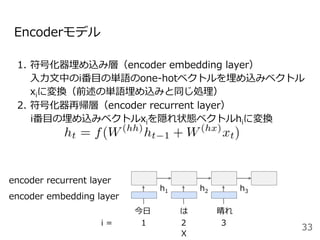
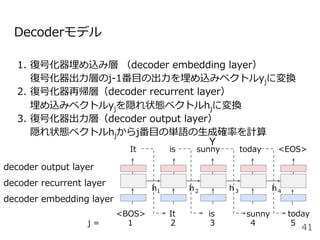
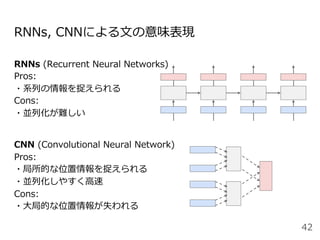
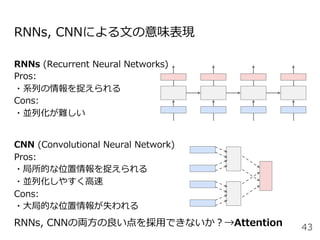

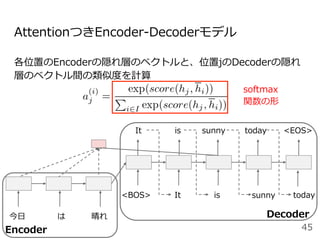
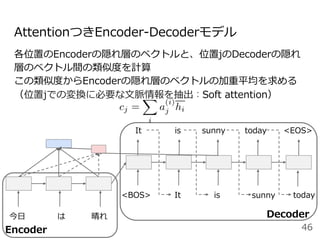
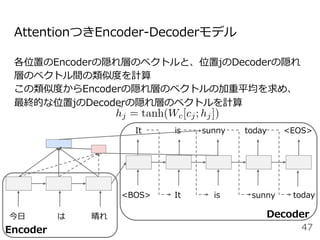
![Attentionを⽤いた代表的なモデル:Transformer
[Vaswani+ 2017]
48
Encoder
● RNNやCNNを⽤いず、
Attentionのみを使⽤したEncoder-
Decoderモデル
● N=6層のEncoderとDecoder
● Attentionは3箇所
○ Encoder-Decoder Attention
○ Encoder Self-Attention
○ Decoder Masked Self-Attention
Decoder](https://image.slidesharecdn.com/20200625-200703072256/85/2020-Deep-learning-9-48-320.jpg)
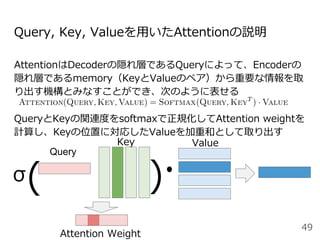
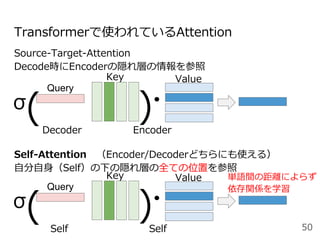
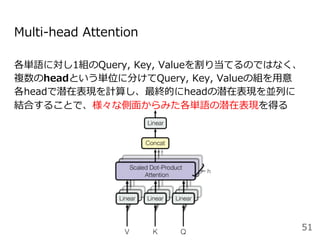

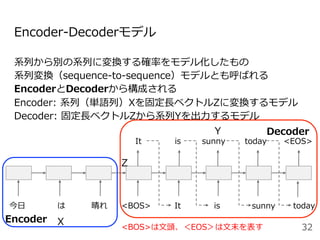
![GPT (Generative Pre-trained Transformer)
[Radford+2018]
元祖・Transformerによる事前学習に基づく汎⽤⾔語モデル
12層⽚⽅向(left-to-right)Transformerの⾃⼰回帰⾔語モデル
:逆⽅向の情報を利⽤できていないのが難点
53図は[Devlin+2019]から引⽤](https://image.slidesharecdn.com/20200625-200703072256/85/2020-Deep-learning-9-53-320.jpg)
![BERT (Bidirectional Encoder Representations
from Transformers)[Devlin+ 2019]
24層の双⽅向Transformerをベースとした、
1. ⼤規模コーパスによる事前学習
2. タスクに応じたファインチューニング
によって様々なタスク・⾔語に応⽤できる汎⽤⾔語モデル
54](https://image.slidesharecdn.com/20200625-200703072256/85/2020-Deep-learning-9-54-320.jpg)
![[CLS] 今⽇ の [MASK] は ⾬ だ [SEP] 傘 を 持っ て [SEP]
BERTの事前学習
2つの事前学習タスクによって双⽅向Transformerの学習を実現
1. Masked Language Model
⼊⼒データの⼀部を[MASK]でマスキングし、前後の単語ではなく
マスキングされた単語を予測するタスクで双⽅向の情報を考慮
2. Next Sentence Prediction
⽂のペア(A, B)が⼊⼒として与えられた時、⽂Bが⽂Aの次に続く
か否かを予測する
55
…
⽂B⽂A
is_next 天気](https://image.slidesharecdn.com/20200625-200703072256/85/2020-Deep-learning-9-55-320.jpg)
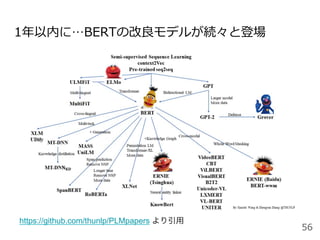
![1年以内に…BERTの改良モデルが続々と登場
● XLNet[Zhilin+2019]
マスキングに⽤いられる特殊記号[MASK]はfine-tuning時には
出現しないためバイアスとなる問題に対して、
単語の並び替え(Permutation Language Model)を採⽤
● RoBERTa[Yinhan+2019]
マスキングの位置を動的に変えることで効率的な学習を実現
● ALBERT[Lan+2019]
BERTで使われているパラメータ数を減らし軽量化
● T5[Raffel+2019]
Text-to-Text Transfer Transformerの略。
分類・翻訳・質問応答などの全タスクで⼊⼒と出⼒をテキスト
フォーマットに統⼀し転移学習することで、⾼精度を実現
57](https://image.slidesharecdn.com/20200625-200703072256/85/2020-Deep-learning-9-57-320.jpg)
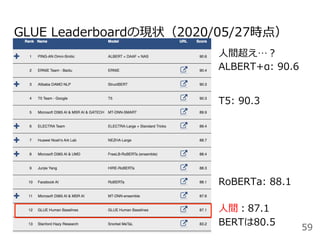
![汎⽤⾔語モデルの評価ベンチマーク
General Language Understanding Evaluation Benchmark
(GLUE)[Wang+2019] https://gluebenchmark.com/
・⽂単位の理解(⽂法性評価、感情分析)
・⽂間の理解(質問応答、類似度、⾔い換え、推論、照応)
を問う9種類のデータセットを組み合わせている
SuperGLUE[Wang+2020] https://super.gluebenchmark.com/
・GLUEの後続。共参照などGLUEよりもハードなタスクを追加
58](https://image.slidesharecdn.com/20200625-200703072256/85/2020-Deep-learning-9-58-320.jpg)
![汎⽤⾔語モデルの実装:transformersの利⽤
huggingfaceが提供するpytorchフレームワークtransformers
https://github.com/huggingface/transformers
で、簡単にBERTなどの汎⽤⾔語モデルを動かせる
例えば、BERTを⽤いた⽇本語単語分割も、数⾏で書けてしまう!
60
from transformers import BertJapaneseTokenizer
tokenizer = BertJapaneseTokenizer.from_pretrained('bert-
base-japanese-whole-word-masking')
tokenizer.tokenize('今日は晴れている')
#['今日', 'は', '晴れ', 'て', 'いる']](https://image.slidesharecdn.com/20200625-200703072256/85/2020-Deep-learning-9-60-320.jpg)
![汎⽤⾔語モデルの課題:
⾔語の意味を真に理解しているか?
⾃然⾔語推論 (Natural Language Inference) a.k.a.
含意関係認識(Recognizing Textual Entailment)[Dagan,2013]
前提⽂が仮説⽂の意味を含むか否かを⾃動判定するタスク
61
前提文: 今年はある日本人がノーベル文学賞を受賞した
仮説文: 今年はある日本人がノーベル賞を受賞した 含意
前提文: 今年はある日本人がノーベル文学賞を受賞した
仮説文: 日本人は誰もノーベル賞を受賞しなかった 矛盾
前提文: 今年はある日本人がノーベル文学賞を受賞した
仮説文: 去年はある日本人がノーベル文学賞を受賞した 非含意 (中立)](https://image.slidesharecdn.com/20200625-200703072256/85/2020-Deep-learning-9-61-320.jpg)
![汎⽤⾔語モデルの課題:
⾔語の意味を真に理解しているか?
62
⼤規模データMultiNLI[Williams+2018]でfinetuningしたBERTの正答率
・MultiNLIテストデータ
・様々な推論現象に特化したテストデータ
- MED[Yanaka+2019]
- Logic Fragments[Richardson+2020]
特定の推論は全く解けていない
MEDに含まれる、BERTが解けない推論の例(downward monotone)
前提⽂: 今年は⽇本⼈は誰もノーベル賞を受賞しなかった
仮説⽂: 今年は⽇本⼈は誰もノーベル⽂学賞を受賞しなかった 含意](https://image.slidesharecdn.com/20200625-200703072256/85/2020-Deep-learning-9-62-320.jpg)
![汎⽤⾔語モデルの課題:
⾔語の意味を真に理解しているか?
63
⼤規模データMultiNLI[Williams+2018]でfinetuningしたBERTの正答率
・MultiNLIテストデータ
・様々な推論現象に特化したテストデータ
- MED[Yanaka+2019]
- Logic Fragments[Richardson+2020]
特定の推論は全く解けていない
⼤規模データセットの問題:
・簡単な問題が多い
・クラウドワーカーの作業バイアス
ニューラル⾔語モデルの問題:
・否定・数量などの離散的な意味を埋め込むことが難しい
・⼊⼒から出⼒までの過程がブラックボックス化されており、
なぜ解ける/解けないのかがわからない](https://image.slidesharecdn.com/20200625-200703072256/85/2020-Deep-learning-9-63-320.jpg)
![汎⽤⾔語モデルの分析:プロービング(probing)
汎⽤⾔語モデルが⾔語を真に理解しているかを分析するための
様々なデータセットや⼿法が研究されている
subject-verb agreement[Linzen+2016][Gulordava+2018]
主語と動詞の数の⼀致を正しく予測できるかで⾔語モデルが⽂法
性を獲得しているか評価
● The keys are/*is ...
● The keys to the cabinet are/*is ...
64
⽂法構造を捉えていないと、
直前のcabinetに対応する動詞
を予測してしまう](https://image.slidesharecdn.com/20200625-200703072256/85/2020-Deep-learning-9-64-320.jpg)
![判断の根拠を⽣成可能なDNNに向けて(1)データ
● e-SNLI[Camburu+,2018]
⾃然⾔語推論の判断根拠をアノテーションしたデータセット
● e-SNLI-VE[Xie+2019][Do+2020]
e-SNLIのマルチモーダル版。画像ーテキスト間の含意関係と
判断根拠がアノテーションされている
65](https://image.slidesharecdn.com/20200625-200703072256/85/2020-Deep-learning-9-65-320.jpg)
![判断の根拠を⽣成可能なDNNに向けて(2)モデル
WT5[Narang+,2020]
Text-to-Textの汎⽤⾔語モデルT5を応⽤したモデル
タスクの種類と問題のテキストを⼊⼒として、
問題の答えと根拠を予測
66](https://image.slidesharecdn.com/20200625-200703072256/85/2020-Deep-learning-9-66-320.jpg)
![記号推論が可能なDNNに向けて(1)データ
DROP[Dua+,2019]:数値演算・ソート・⽐較などの記号推論を
問う⽂書読解データセット
67](https://image.slidesharecdn.com/20200625-200703072256/85/2020-Deep-learning-9-67-320.jpg)
![記号推論が可能なDNNに向けて(2)モデル
Neural Symbolic Reader[Chen+,2020]
Neural Module Networks[Gupta+,2020][Andreas+,2016]
質問⽂から回答を算出するためのプログラムに変換することで、
数値演算を実現
68](https://image.slidesharecdn.com/20200625-200703072256/85/2020-Deep-learning-9-68-320.jpg)


![[DL輪読会]Flow-based Deep Generative Models](https://cdn.slidesharecdn.com/ss_thumbnails/20190307-190328024744-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DL輪読会]The Neural Process Family−Neural Processes関連の実装を読んで動かしてみる−](https://cdn.slidesharecdn.com/ss_thumbnails/20190415dlhacks-190422075753-thumbnail.jpg?width=640&height=640&fit=bounds)





![[DL輪読会]Set Transformer: A Framework for Attention-based Permutation-Invariant...](https://cdn.slidesharecdn.com/ss_thumbnails/20200221settransformer-200221020423-thumbnail.jpg?width=640&height=640&fit=bounds)









![[DL輪読会]Grokking: Generalization Beyond Overfitting on Small Algorithmic Datasets](https://cdn.slidesharecdn.com/ss_thumbnails/20220325okimura-220405024717-thumbnail.jpg?width=640&height=640&fit=bounds)





![[DL輪読会]Focal Loss for Dense Object Detection](https://cdn.slidesharecdn.com/ss_thumbnails/focalloss-180208092846-thumbnail.jpg?width=640&height=640&fit=bounds)


![[旧版] JSAI2018 チュートリアル「"深層学習時代の" ゼロから始める自然言語処理」](https://cdn.slidesharecdn.com/ss_thumbnails/jsai2018tutorialslideshare-180606065226-thumbnail.jpg?width=640&height=640&fit=bounds)
![[最新版] JSAI2018 チュートリアル「"深層学習時代の" ゼロから始める自然言語処理」](https://cdn.slidesharecdn.com/ss_thumbnails/jsai2018tutorialslideshare-180607030706-thumbnail.jpg?width=640&height=640&fit=bounds)















