Download to read offline




















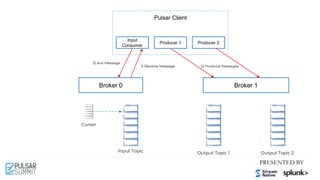

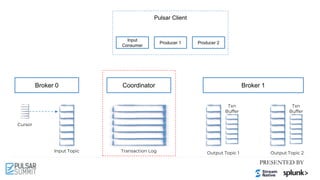

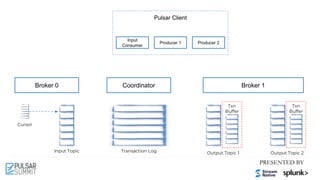

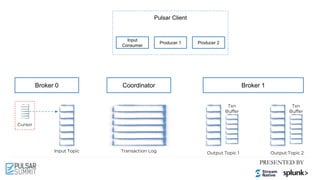




![Pulsar Client
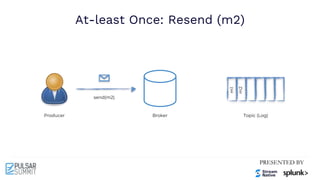
Cursor
Input Topic Output Topic 1 Output Topic 2
Broker 0 Broker 1
Input
Consumer
Producer 2
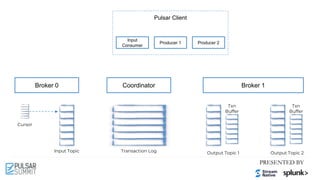
Coordinator
Transaction Log
Txn
Buffer
Txn
Buffer
Txn
New Txn
Producer 1
Tx1
Tx1: add [T1, T2] Tx1: M1 Tx1: M2
2.2 Produced Messages To
Topics with Txn
2.1 Add Produced
Topics To Txn](https://image.slidesharecdn.com/exactly-oncemadeeasytransactionalmessaginginapachepulsar-210622213137/85/Exactly-Once-Made-Easy-Transactional-Messaging-in-Apache-Pulsar-Pulsar-Summit-NA-2021-63-320.jpg)

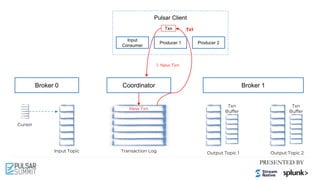
![Pulsar Client
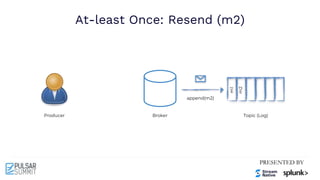
Cursor
Input Topic Output Topic 1 Output Topic 2
Broker 0 Broker 1
Input
Consumer
Producer 2
Coordinator
Transaction Log
Txn
Buffer
Txn
Buffer
Txn
New Txn
Producer 1
Tx1
Tx1: add [T1, T2] Tx1: M1 Tx1: M2
3.1 Add Acked
Subscriptions to Txn
Tx1: ACK (M0)
3.2 Ack messages with Txn
Tx1: add [S0]](https://image.slidesharecdn.com/exactly-oncemadeeasytransactionalmessaginginapachepulsar-210622213137/85/Exactly-Once-Made-Easy-Transactional-Messaging-in-Apache-Pulsar-Pulsar-Summit-NA-2021-65-320.jpg)

![Pulsar Client
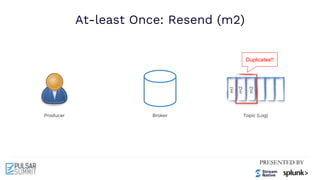
Cursor
Input Topic Output Topic 1 Output Topic 2
Broker 0 Broker 1
Input
Consumer
Producer 2
Coordinator
Transaction Log
Txn
Buffer
Txn
Buffer
Txn
New Txn
Producer 1
Tx1
Tx1: add [T1, T2] Tx1: M1 Tx1: M2
4.0 Commit Txn
Tx1: ACK (M0)
Tx1: add [S0]
4.0.1 Committing Txn
Tx1: Committing](https://image.slidesharecdn.com/exactly-oncemadeeasytransactionalmessaginginapachepulsar-210622213137/85/Exactly-Once-Made-Easy-Transactional-Messaging-in-Apache-Pulsar-Pulsar-Summit-NA-2021-67-320.jpg)
![Pulsar Client
Cursor
Input Topic Output Topic 1 Output Topic 2
Broker 0 Broker 1
Input
Consumer
Producer 2
Coordinator
Transaction Log
Txn
Buffer
Txn
Buffer
Txn
New Txn
Producer 1
Tx1
Tx1: add [T1, T2] Tx1: M1 Tx1: M2
Tx1: ACK (M0)
Tx1: add [S0]
Tx1: Committing
Tx1: Committed Tx1: (c) Tx1: (c)
4.1.1 Commit Txn
on Subscriptions
4.1.0 Commit Txn
on Topics](https://image.slidesharecdn.com/exactly-oncemadeeasytransactionalmessaginginapachepulsar-210622213137/85/Exactly-Once-Made-Easy-Transactional-Messaging-in-Apache-Pulsar-Pulsar-Summit-NA-2021-68-320.jpg)
![Pulsar Client
Cursor
Input Topic Output Topic 1 Output Topic 2
Broker 0 Broker 1
Input
Consumer
Producer 2
Coordinator
Transaction Log
Txn
Buffer
Txn
Buffer
Txn
New Txn
Producer 1
Tx1
Tx1: add [T1, T2] Tx1: M1 Tx1: M2
Tx1: ACK (M0)
Tx1: add [S0]
Tx1: Committing
Tx1: Committed
Tx1: Committed Tx1: (c) Tx1: (c)
4.2 Commit Txn](https://image.slidesharecdn.com/exactly-oncemadeeasytransactionalmessaginginapachepulsar-210622213137/85/Exactly-Once-Made-Easy-Transactional-Messaging-in-Apache-Pulsar-Pulsar-Summit-NA-2021-69-320.jpg)

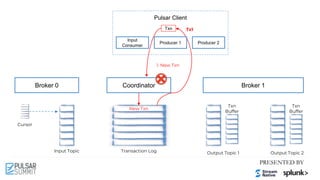
![Pulsar Client
Cursor
Input Topic Output Topic 1 Output Topic 2
Broker 0 Broker 1
Input
Consumer
Producer 2
Coordinator
Transaction Log
Txn
Buffer
Txn
Buffer
Txn
New Txn
Producer 1
Tx1
Tx1: add [T1, T2] Tx1: M1 Tx1: M2
2.2 Produced Messages To
Topics with Txn
2.1 Add Produced
Topics To Txn](https://image.slidesharecdn.com/exactly-oncemadeeasytransactionalmessaginginapachepulsar-210622213137/85/Exactly-Once-Made-Easy-Transactional-Messaging-in-Apache-Pulsar-Pulsar-Summit-NA-2021-72-320.jpg)
![Pulsar Client
Cursor
Input Topic Output Topic 1 Output Topic 2
Broker 0 Broker 1
Input
Consumer
Producer 2
Coordinator
Transaction Log
Txn
Buffer
Txn
Buffer
Txn
New Txn
Producer 1
Tx1
Tx1: add [T1, T2] Tx1: M1 Tx1: M2
3.1 Add Acked
Subscriptions to Txn
Tx1: ACK (M0)
3.2 Ack messages with Txn
Tx1: add [S0]](https://image.slidesharecdn.com/exactly-oncemadeeasytransactionalmessaginginapachepulsar-210622213137/85/Exactly-Once-Made-Easy-Transactional-Messaging-in-Apache-Pulsar-Pulsar-Summit-NA-2021-73-320.jpg)
![Pulsar Client
Cursor
Input Topic Output Topic 1 Output Topic 2
Broker 0 Broker 1
Input
Consumer
Producer 2
Coordinator
Transaction Log
Txn
Buffer
Txn
Buffer
Txn
New Txn
Producer 1
Tx1
Tx1: add [T1, T2] Tx1: M1 Tx1: M2
Tx1: ACK (M0)
Tx1: add [S0]
Tx1: Committing
Tx1: Committed Tx1: (c) Tx1: (c)
4.1.1 Commit Txn
on Subscriptions
4.1.0 Commit Txn
on Topics](https://image.slidesharecdn.com/exactly-oncemadeeasytransactionalmessaginginapachepulsar-210622213137/85/Exactly-Once-Made-Easy-Transactional-Messaging-in-Apache-Pulsar-Pulsar-Summit-NA-2021-74-320.jpg)

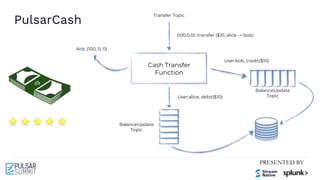
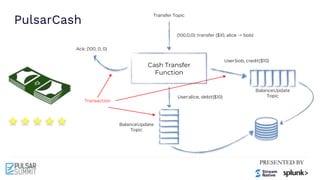








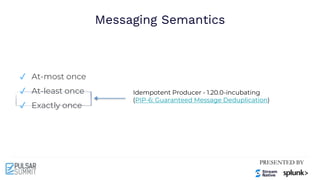
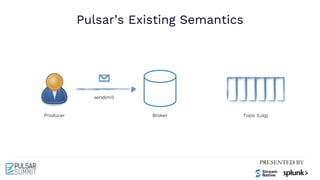
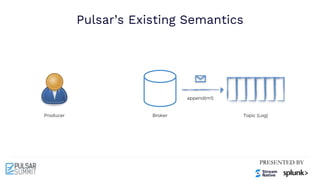
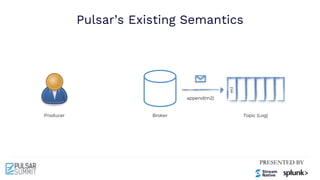
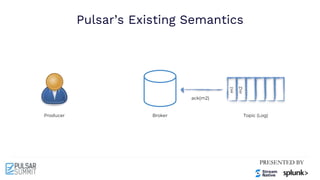
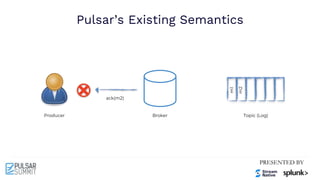
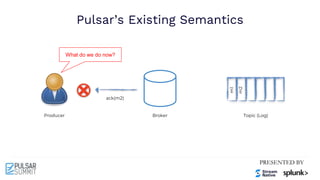
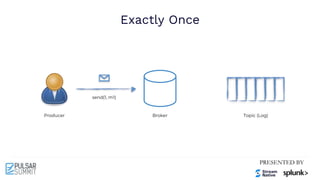
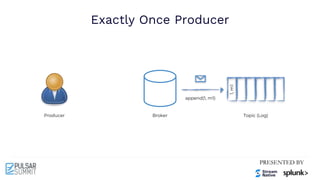
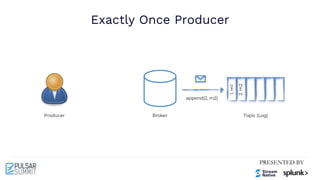
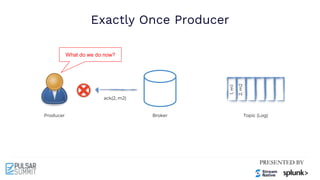
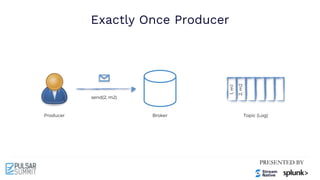
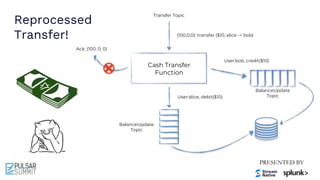
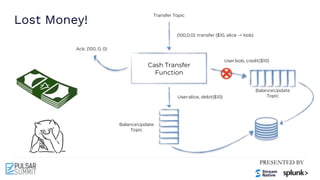
The Pulsar Virtual Summit North America 2021 featured discussions on achieving exactly-once semantics in transactional messaging using Apache Pulsar, focusing on features such as idempotent producers and guaranteed message deduplication. It introduced the concept of transactions which allow for atomic writes and acknowledgments across multiple topic partitions, ensuring that all operations succeed or fail as a unit. The summit highlighted ongoing developments and support for transactions in various programming languages and integrations with other systems.






![[pgday.Seoul 2022] PostgreSQL구조 - 윤성재](https://cdn.slidesharecdn.com/ss_thumbnails/pgday2022-postgresql-20221112-221114014106-bbfb1955-thumbnail.jpg?width=640&height=640&fit=bounds)










![[135] 오픈소스 데이터베이스, 은행 서비스에 첫발을 내밀다.](https://cdn.slidesharecdn.com/ss_thumbnails/35-171016061446-thumbnail.jpg?width=640&height=640&fit=bounds)






![[Keynote] 슬기로운 AWS 데이터베이스 선택하기 - 발표자: 강민석, Korea Database SA Manager, WWSO, A...](https://cdn.slidesharecdn.com/ss_thumbnails/d3s01aws-230704014400-3eeae447-thumbnail.jpg?width=640&height=640&fit=bounds)















![[March sn meetup] apache pulsar + apache nifi for cloud data lake](https://cdn.slidesharecdn.com/ss_thumbnails/marchsnmeetupapachepulsarapachenififorclouddatalake-220311125943-thumbnail.jpg?width=640&height=640&fit=bounds)














































