Download as PDF, PPTX



![3
What is Kafka, Really?
[NetDB 2011]a scalable Pub-sub messaging system..](https://image.slidesharecdn.com/kafkastreamsdataengconf2016-161108184438/85/Apache-Kafka-and-the-Rise-of-Stream-Processing-3-320.jpg)
![4
What is Kafka, Really?
[NetDB 2011]
[Hadoop Summit 2013]
a scalable Pub-sub messaging system..
a real-time data pipeline..](https://image.slidesharecdn.com/kafkastreamsdataengconf2016-161108184438/85/Apache-Kafka-and-the-Rise-of-Stream-Processing-4-320.jpg)
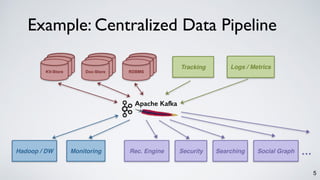
![6
What is Kafka, Really?
[NetDB 2011]
[Hadoop Summit 2013]
[VLDB 2015]
a scalable Pub-sub messaging system..
a real-time data pipeline..
a distributed and replicated log..](https://image.slidesharecdn.com/kafkastreamsdataengconf2016-161108184438/85/Apache-Kafka-and-the-Rise-of-Stream-Processing-6-320.jpg)
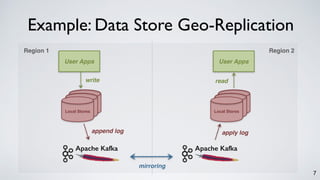
![8
What is Kafka, Really?
a scalable Pub-sub messaging system.. [NetDB 2011]
a real-time data pipeline.. [Hadoop Summit 2013]
a distributed and replicated log.. [VLDB 2015]
a unified data integration stack.. [CIDR 2015]](https://image.slidesharecdn.com/kafkastreamsdataengconf2016-161108184438/85/Apache-Kafka-and-the-Rise-of-Stream-Processing-8-320.jpg)
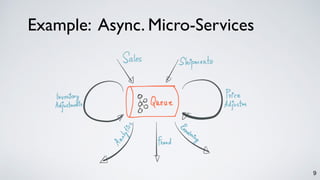
![10
Which of the following is true?
a scalable Pub-sub messaging system.. [NetDB 2011]
a real-time data pipeline.. [Hadoop Summit 2013]
a distributed and replicated log.. [VLDB 2015]
a unified data integration stack.. [CIDR 2015]](https://image.slidesharecdn.com/kafkastreamsdataengconf2016-161108184438/85/Apache-Kafka-and-the-Rise-of-Stream-Processing-10-320.jpg)
![11
Which of the following is true?
a scalable Pub-sub messaging system.. [NetDB 2011]
a real-time data pipeline.. [Hadoop Summit 2013]
a distributed and replicated log.. [VLDB 2015]
a unified data integration stack.. [CIDR 2015]
All of them!](https://image.slidesharecdn.com/kafkastreamsdataengconf2016-161108184438/85/Apache-Kafka-and-the-Rise-of-Stream-Processing-11-320.jpg)

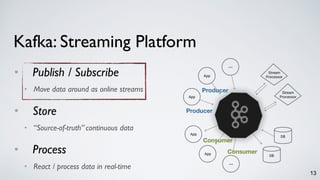







![Kafka Streams DSL
28
public static void main(String[] args) {
// specify the processing topology by first reading in a stream from a topic
KStream<String, String> words = builder.stream(”topic1”);
// count the words in this stream as an aggregated table
KTable<String, Long> counts = words.countByKey(”Counts”);
// write the result table to a new topic
counts.to(”topic2”);
// create a stream processing instance and start running it
KafkaStreams streams = new KafkaStreams(builder, config);
streams.start();
}](https://image.slidesharecdn.com/kafkastreamsdataengconf2016-161108184438/85/Apache-Kafka-and-the-Rise-of-Stream-Processing-28-320.jpg)
![Kafka Streams DSL
29
public static void main(String[] args) {
// specify the processing topology by first reading in a stream from a topic
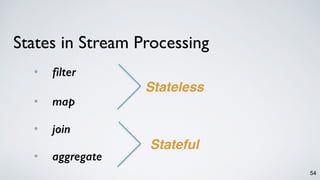
KStream<String, String> words = builder.stream(”topic1”);
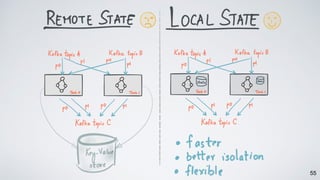
// count the words in this stream as an aggregated table
KTable<String, Long> counts = words.countByKey(”Counts”);
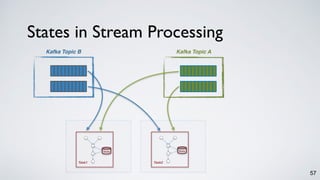
// write the result table to a new topic
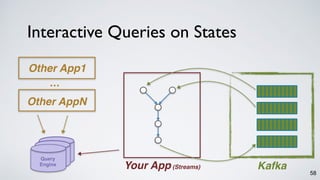
counts.to(”topic2”);
// create a stream processing instance and start running it
KafkaStreams streams = new KafkaStreams(builder, config);
streams.start();
}](https://image.slidesharecdn.com/kafkastreamsdataengconf2016-161108184438/85/Apache-Kafka-and-the-Rise-of-Stream-Processing-29-320.jpg)
![Kafka Streams DSL
30
public static void main(String[] args) {
// specify the processing topology by first reading in a stream from a topic
KStream<String, String> words = builder.stream(”topic1”);
// count the words in this stream as an aggregated table
KTable<String, Long> counts = words.countByKey(”Counts”);
// write the result table to a new topic
counts.to(”topic2”);
// create a stream processing instance and start running it
KafkaStreams streams = new KafkaStreams(builder, config);
streams.start();
}](https://image.slidesharecdn.com/kafkastreamsdataengconf2016-161108184438/85/Apache-Kafka-and-the-Rise-of-Stream-Processing-30-320.jpg)
![Kafka Streams DSL
31
public static void main(String[] args) {
// specify the processing topology by first reading in a stream from a topic
KStream<String, String> words = builder.stream(”topic1”);
// count the words in this stream as an aggregated table
KTable<String, Long> counts = words.countByKey(”Counts”);
// write the result table to a new topic
counts.to(”topic2”);
// create a stream processing instance and start running it
KafkaStreams streams = new KafkaStreams(builder, config);
streams.start();
}](https://image.slidesharecdn.com/kafkastreamsdataengconf2016-161108184438/85/Apache-Kafka-and-the-Rise-of-Stream-Processing-31-320.jpg)
![Kafka Streams DSL
32
public static void main(String[] args) {
// specify the processing topology by first reading in a stream from a topic
KStream<String, String> words = builder.stream(”topic1”);
// count the words in this stream as an aggregated table
KTable<String, Long> counts = words.countByKey(”Counts”);
// write the result table to a new topic
counts.to(”topic2”);
// create a stream processing instance and start running it
KafkaStreams streams = new KafkaStreams(builder, config);
streams.start();
}](https://image.slidesharecdn.com/kafkastreamsdataengconf2016-161108184438/85/Apache-Kafka-and-the-Rise-of-Stream-Processing-32-320.jpg)


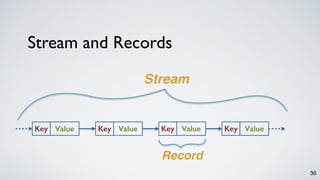

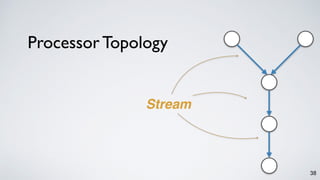
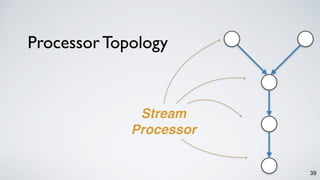





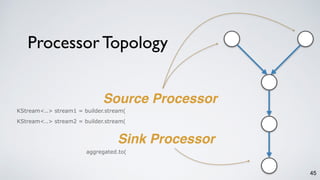
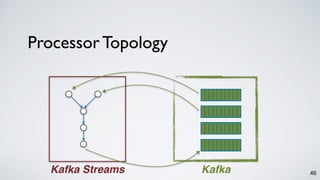
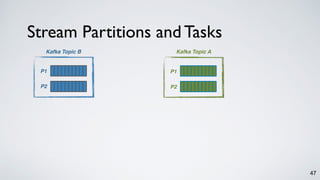
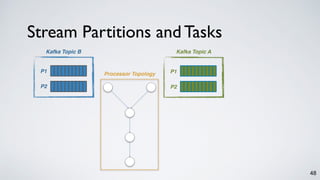
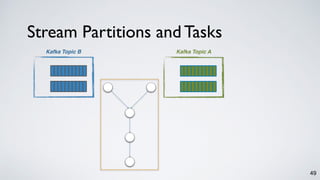
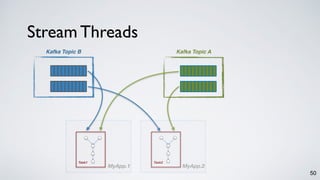
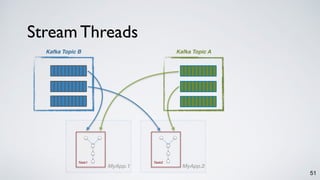
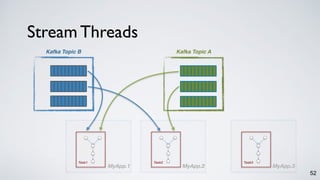
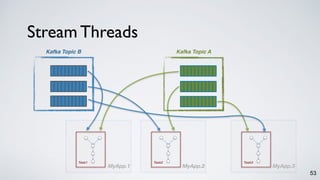

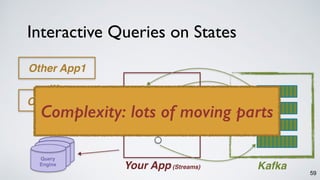
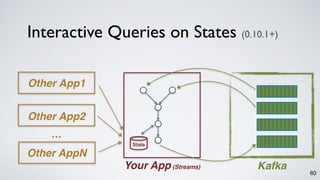




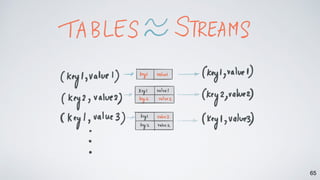


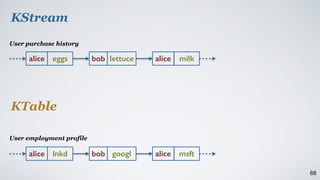
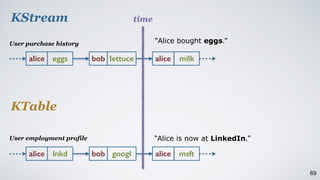
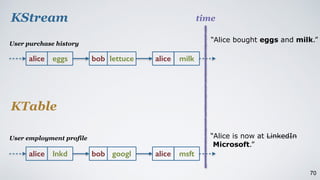
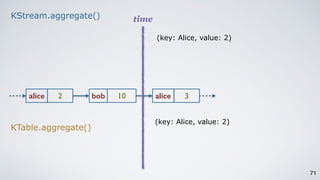
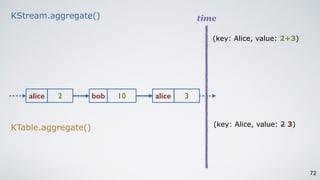
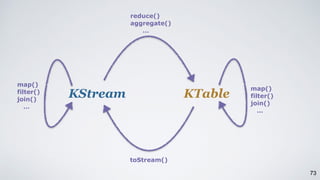
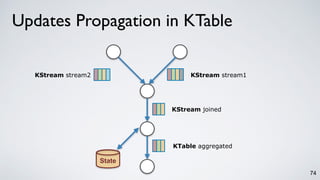
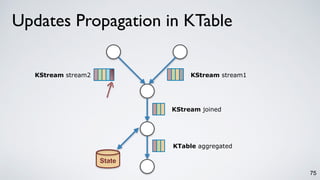
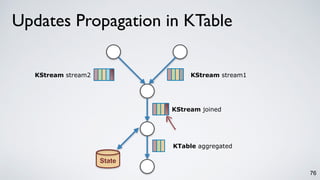
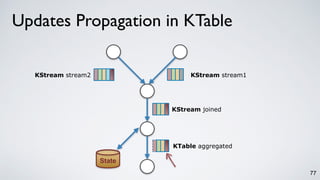

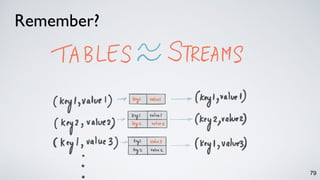
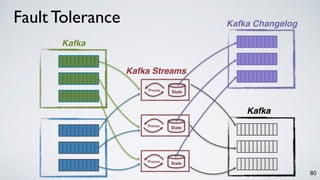
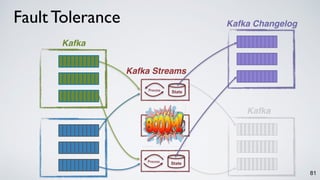
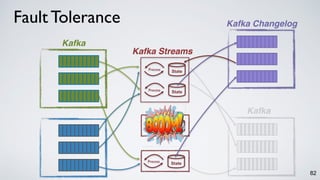
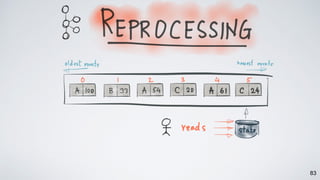
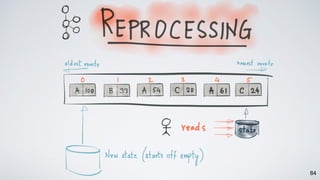
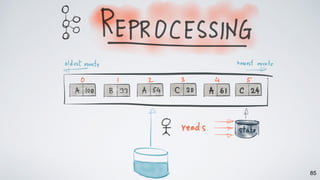
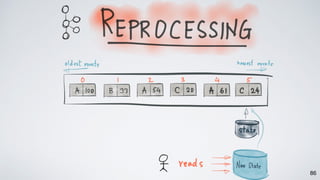







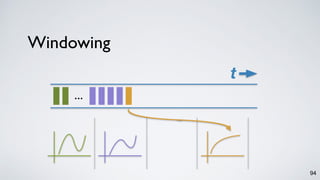
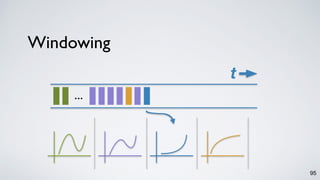
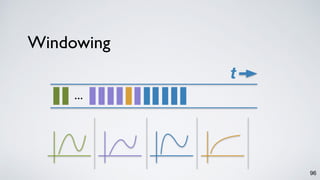
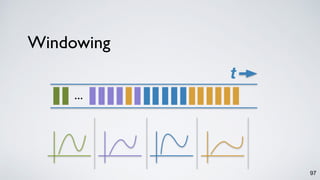
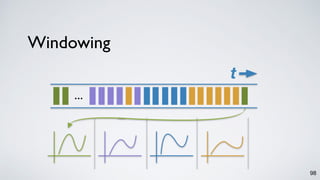
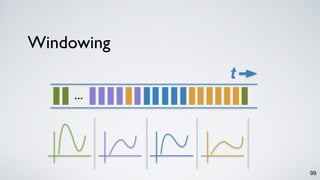







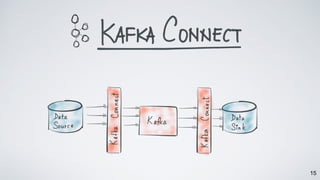
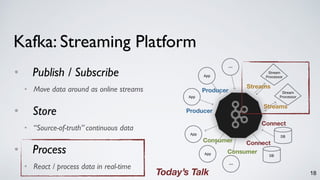
The document discusses Apache Kafka as a scalable and distributed pub-sub messaging system that serves as a real-time data pipeline and integrated data processing platform. It explains Kafka Streams, a client library for processing streaming data, the concepts of event-time and processing-time, and the importance of fault tolerance and state management in stream processing. The document highlights ongoing developments in Kafka, including new features and support for multiple programming languages.



































































![Building streaming data applications using Kafka*[Connect + Core + Streams] b...](https://cdn.slidesharecdn.com/ss_thumbnails/buildingstreamingdataapplicationsusingapachekafka-171011211455-thumbnail.jpg?width=640&height=640&fit=bounds)



















