Download as PDF, PPTX





![Hardware Infrastructure is Evolving
+ Compute
+ From 100+ cores → 1,000+ cores per server
+ From multicore CPUs → full System on a Chip (SoC) designs (CPU,
GPU, Cache, Memory)
+ Memory
+ Terabyte-scale RAM per server
+ DDR4 — 800 to 1600 MHz, 2011-present
+ DDR5 — 4600 MHz in 2020, 8000 MHz by 2024
+ DDR6 — 9600 MHz by 2025
+ Storage
+ Petabyte-scale storage per server
+ NVMe 2.0 [2021] — separation of base and transport
Distributed Database Design Decisions to Support High Performance Event Streaming](https://image.slidesharecdn.com/355pmpetercorlessscylladb-221128034713-8a8062d4/85/Distributed-Database-Design-Decisions-to-Support-High-Performance-Event-Streaming-Pulsar-Summit-SF-2022-5-320.jpg)
![Distributed Database Design Decisions to Support High Performance Event Streaming
Databases are Evolving
+ Consistency Models [CAP Model: AP vs. CP]
+ Strong, Eventual, Tunable
+ ACID vs. BASE
+ Data Model / Query Languages [SQL vs. NoSQL]
+ RDBMS / SQL
+ NoSQL [Document, Key-Value, Wide-Column, Graph]
+ Big Data → HUGE Data
+ Data Stored: Gigabytes? Terabytes? Petabytes? Exabytes?
+ Payload Sizes: Kilobytes? Megabytes?
+ OPS / TPS: Hundreds of thousands? Millions?
+ Latencies: Sub-millisecond? Single-digit milliseconds?](https://image.slidesharecdn.com/355pmpetercorlessscylladb-221128034713-8a8062d4/85/Distributed-Database-Design-Decisions-to-Support-High-Performance-Event-Streaming-Pulsar-Summit-SF-2022-6-320.jpg)
![Distributed Database Design Decisions to Support High Performance Event Streaming
Databases are [or should be] designed for
specific kinds of data, specific kinds of
workloads, and specific kinds of queries.
How aligned or far away from your specific
use case a database may be in its design &
implementation from your desired utility of it
determines the resistance of the system
Variable
Resistors
Anyone?](https://image.slidesharecdn.com/355pmpetercorlessscylladb-221128034713-8a8062d4/85/Distributed-Database-Design-Decisions-to-Support-High-Performance-Event-Streaming-Pulsar-Summit-SF-2022-7-320.jpg)
![Distributed Database Design Decisions to Support High Performance Event Streaming
Δ Data
––––––––––––
t
t ~ n ×0.001s
For a database to be appropriate for event streaming, it needs to
support managing changes to data over time in “real time” —
measured in single-digit milliseconds or less.
And where changes to data can be produced at a rate of
hundreds of thousands or millions of events per second. [And
greater rates in future]](https://image.slidesharecdn.com/355pmpetercorlessscylladb-221128034713-8a8062d4/85/Distributed-Database-Design-Decisions-to-Support-High-Performance-Event-Streaming-Pulsar-Summit-SF-2022-9-320.jpg)
![DBaaS
Single-cloud vs.
Multi-cloud?
Multi-datacenter
Elasticity
Serverless
Orchestration
DevSecOps
Scalability
Reliability
Durability
Manageability
Observability
Flexibility
Facility / Usability
Compatibility
Interoperability
Linearizability
“Batch” → “Stream”
Change Data
Capture (CDC)
Sink & Source
Time Series
Event Streaming
Event Sourcing*
[* ≠ Event Streaming]
SQL or NoSQL?
Query Language
Data Model
Data Distribution
Workload [R/W]
Speed
Price/TCO/ROI
Cloud Native
Qualities
All the “-ilities” Event-Driven Best Fit to Use Case
Distributed Database Design Decisions to Support High Performance Event Streaming](https://image.slidesharecdn.com/355pmpetercorlessscylladb-221128034713-8a8062d4/85/Distributed-Database-Design-Decisions-to-Support-High-Performance-Event-Streaming-Pulsar-Summit-SF-2022-10-320.jpg)


![Distributed Database Design Decisions to Support High Performance Event Streaming
Database-as-a-Service (DBaaS)
+ Lift-and-Shift to Cloud — Same base offering as on-premises version,
offered as a cloud-hosted managed service
+ Easy/fast to bring to market, but no fundamental design changes
+ Cloud Native — Designed from-the-ground-up for cloud [only] usage
+ Elasticity — Dynamic provisioning, scale up/down for throughput, storage
+ Serverless — Do I need to know what hardware I’m running on?
+ Microservices & API integration — App integration, connectors, DevEx
+ Billing — making it easy to consume & measure ROI/TCO
+ Governance: Privacy Compliance / Data Localization](https://image.slidesharecdn.com/355pmpetercorlessscylladb-221128034713-8a8062d4/85/Distributed-Database-Design-Decisions-to-Support-High-Performance-Event-Streaming-Pulsar-Summit-SF-2022-13-320.jpg)
![Distributed Database Design Decisions to Support High Performance Event Streaming
What does a database need to be, or have, or do, to properly support
event streaming in 2022?
+ High Availability [“Always On”]
+ Impedance Match of Database to Event Streaming Systems
+ Similar characteristics for throughput, latency
+ All the Appropriate “Goesintos/Goesouttas”
+ Sink Connector
+ Change Data Capture (CDC) / Source Connector
+ Supports your favorite streaming flavor of the day
+ Kafka, Pulsar, RabbitMQ Streams, etc.](https://image.slidesharecdn.com/355pmpetercorlessscylladb-221128034713-8a8062d4/85/Distributed-Database-Design-Decisions-to-Support-High-Performance-Event-Streaming-Pulsar-Summit-SF-2022-14-320.jpg)

![Distributed Database Design Decisions to Support High Performance Event Streaming
ScyllaDB: Building on “Good Bones”
+ Performant: Shard-per-core, async-everywhere, shared-nothing architecture
+ Scalable: both horizontal [100s/1000s of nodes] & vertical [100s/1000s cores]
+ Available: Peer-to-Peer, Active-Active; no single point of failure
+ Distribution: Multi-datacenter clustering & replication, auto-sharding
+ Consistency: tunable; primarily eventual, but also Lightweight Transactions (LWT)
+ Topology Aware: Shard-aware, Node-aware, Rack-aware, Datacenter-aware
+ Compatible: Cassandra CQL & Amazon DynamoDB APIs](https://image.slidesharecdn.com/355pmpetercorlessscylladb-221128034713-8a8062d4/85/Distributed-Database-Design-Decisions-to-Support-High-Performance-Event-Streaming-Pulsar-Summit-SF-2022-16-320.jpg)
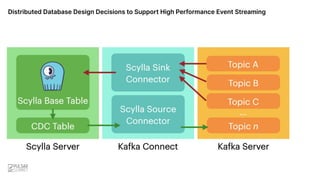
![Distributed Database Design Decisions to Support High Performance Event Streaming
ScyllaDB Journey to Event Streaming — Starting with Kafka
+ Shard-Aware Kafka Sink Connector [January 2020]
+ Github: https://github.com/scylladb/kafka-connect-scylladb
+ Blog: https://www.scylladb.com/2020/02/18/introducing-the-kafka-scylla-connector/](https://image.slidesharecdn.com/355pmpetercorlessscylladb-221128034713-8a8062d4/85/Distributed-Database-Design-Decisions-to-Support-High-Performance-Event-Streaming-Pulsar-Summit-SF-2022-17-320.jpg)
![Distributed Database Design Decisions to Support High Performance Event Streaming
ScyllaDB Journey to Event Streaming — Starting with Kafka
+ Shard-Aware Kafka Sink Connector [January 2020]
+ Github: https://github.com/scylladb/kafka-connect-scylladb
+ Blog: https://www.scylladb.com/2020/02/18/introducing-the-kafka-scylla-connector/
+ Change Data Capture [January 2020 – October 2021]
+ January 2020: ScyllaDB Open Source 3.2 — Experimental
+ Course of 2020 - 3.3, 3.4, 4.0, 4.1, 4.2 — Experimental iterations
+ January 2021: 4.3: Production-ready, new API
+ March 2021: 4.4: new API
+ October 2021: 4.5: performance & stability](https://image.slidesharecdn.com/355pmpetercorlessscylladb-221128034713-8a8062d4/85/Distributed-Database-Design-Decisions-to-Support-High-Performance-Event-Streaming-Pulsar-Summit-SF-2022-18-320.jpg)
![Distributed Database Design Decisions to Support High Performance Event Streaming
ScyllaDB Journey to Event Streaming — Starting with Kafka
+ Shard-Aware Kafka Sink Connector [January 2020]
+ Github: https://github.com/scylladb/kafka-connect-scylladb
+ Blog: https://www.scylladb.com/2020/02/18/introducing-the-kafka-scylla-connector/
+ Change Data Capture [January 2020 – October 2021]
+ January 2020: ScyllaDB Open Source 3.2 — Experimental
+ Course of 2020 - 3.3, 3.4, 4.0, 4.1, 4.2 — Experimental iterations
+ January 2021: 4.3: Production-ready, new API
+ March 2021: 4.4: new API
+ October 2021: 4.5: performance & stability
+ CDC Kafka Source Connector [April 2021]
+ Github: https://github.com/scylladb/scylla-cdc-source-connector
+ Blog: https://debezium.io/blog/2021/09/22/deep-dive-into-a-debezium-community-conn
ector-scylla-cdc-source-connector/](https://image.slidesharecdn.com/355pmpetercorlessscylladb-221128034713-8a8062d4/85/Distributed-Database-Design-Decisions-to-Support-High-Performance-Event-Streaming-Pulsar-Summit-SF-2022-19-320.jpg)






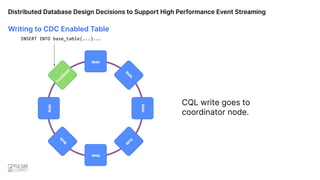
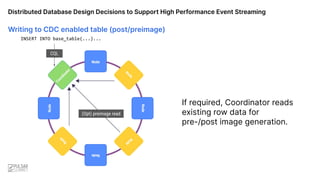
![Writing to Base Table [No CDC]
CQL write goes to
coordinator node.
INSERT INTO base_table(...)...
Distributed Database Design Decisions to Support High Performance Event Streaming](https://image.slidesharecdn.com/355pmpetercorlessscylladb-221128034713-8a8062d4/85/Distributed-Database-Design-Decisions-to-Support-High-Performance-Event-Streaming-Pulsar-Summit-SF-2022-28-320.jpg)
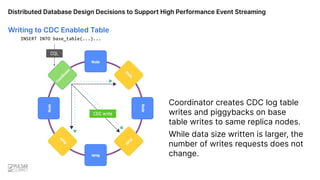
![Coordinator node creates
write calls to replica nodes.
INSERT INTO base_table(...)...
CQL
Replicated writes
Writing to Base Table [No CDC]
Distributed Database Design Decisions to Support High Performance Event Streaming](https://image.slidesharecdn.com/355pmpetercorlessscylladb-221128034713-8a8062d4/85/Distributed-Database-Design-Decisions-to-Support-High-Performance-Event-Streaming-Pulsar-Summit-SF-2022-29-320.jpg)



Peter Corless, Director of Technical Advocacy at ScyllaDB, discusses the design decisions needed for distributed databases to effectively support high-performance event streaming. He emphasizes the importance of database architectures that accommodate real-time data changes, high availability, and scalability while highlighting ScyllaDB's evolution towards robust event streaming capabilities. The presentation also covers the future of database technology in the context of increasing demands for data storage and processing speeds.









![[WSO2Con EU 2018] Streaming SQL in the Real World](https://cdn.slidesharecdn.com/ss_thumbnails/wso2coneu2018streamingsqlintherealworld-181113090808-thumbnail.jpg?width=640&height=640&fit=bounds)

![[WSO2Con EU 2018] The Rise of Streaming SQL](https://cdn.slidesharecdn.com/ss_thumbnails/1-181113084942-thumbnail.jpg?width=640&height=640&fit=bounds)


![[WSO2Con USA 2018] The Rise of Streaming SQL](https://cdn.slidesharecdn.com/ss_thumbnails/wso2conusa2018theriseofstreamingsql-180717041454-thumbnail.jpg?width=640&height=640&fit=bounds)




















































