


![Challenges of data platform[1]
•
•
•
•
•
•
•
•
High throughput
Horizontal scale to address growth
High availability of data services
No Data loss
Satisfy Real-Time demands
Enforce structural data with schemas
Process Big Data and Enterprise Data
Single Source of Truth (SSOT)](https://image.slidesharecdn.com/fromakafkaesquestorytothepromisedland-130707104535-phpapp02-131121034336-phpapp01/85/From-a-Kafkaesque-Story-to-The-Promised-Land-at-LivePerson-3-320.jpg)
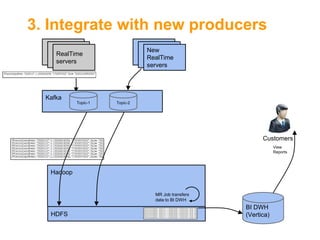
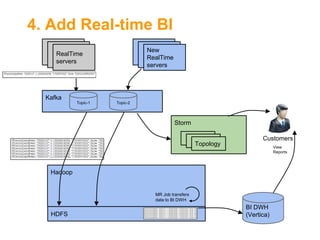
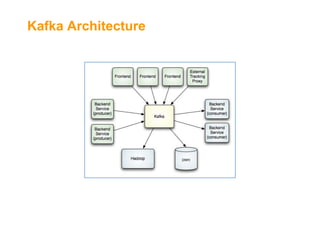
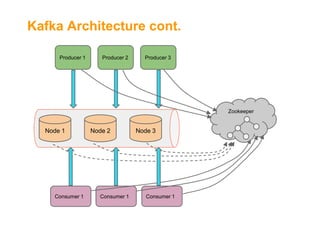
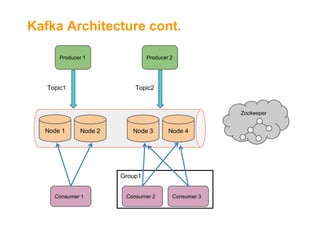
![Kafka[2] as Backbone for Data
•
•
•
•
•
•
•
•
Central "Message Bus"
Support multiple topics (MQ style)
Write ahead to files
Distributed & Highly Available
Horizontal Scale
High throughput (10s MB/Sec per server)
Service is agnostic to consumers' state
Retention policy](https://image.slidesharecdn.com/fromakafkaesquestorytothepromisedland-130707104535-phpapp02-131121034336-phpapp01/85/From-a-Kafkaesque-Story-to-The-Promised-Land-at-LivePerson-12-320.jpg)
![Kafka API[3]
•
•
Producer API
Consumer API
o
High-level API
using zookeeper to access brokers and to save
offsets
o
SimpleConsumer API
•
direct access to Kafka brokers
Kafka-Spout, Camus, and KafkaHadoopConsumer all
use SimpleConsumer](https://image.slidesharecdn.com/fromakafkaesquestorytothepromisedland-130707104535-phpapp02-131121034336-phpapp01/85/From-a-Kafkaesque-Story-to-The-Promised-Land-at-LivePerson-17-320.jpg)
![Kafka API[3]
•
Producer
messages = new List<KeyedMessage<K, V>>()
Messages.add(new KeyedMessage(“topic1”, null, msg1));
Send(messages);
•
Consumer
streams[] = Consumer.createMessageStream((“topic1”, 1);
for (message: streams[0]{
//do something with message
}](https://image.slidesharecdn.com/fromakafkaesquestorytothepromisedland-130707104535-phpapp02-131121034336-phpapp01/85/From-a-Kafkaesque-Story-to-The-Promised-Land-at-LivePerson-18-320.jpg)

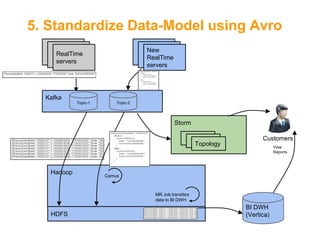
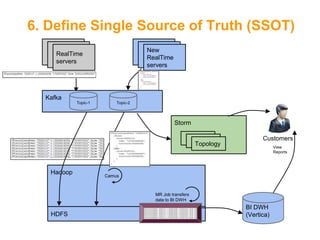
![Introducing Avro[5]
•
•
Schema representation using JSON
Support types
o
Primitive types: boolean, int, long, string, etc.
o
Complex types:
Record, Enum, Union, Arrays, Maps, Fixed
•
•
Data is serialized using its schema
Avro files include file-header of the schema](https://image.slidesharecdn.com/fromakafkaesquestorytothepromisedland-130707104535-phpapp02-131121034336-phpapp01/85/From-a-Kafkaesque-Story-to-The-Promised-Land-at-LivePerson-20-320.jpg)
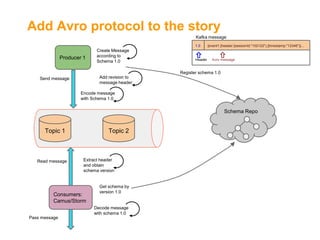


![Major Improvements in Kafka 0.8[4]
•
•
•
Partitions replication
Message send guarantee
Consumer offsets are represented numbers instead of
bytes (e.g., 1, 2, 3, ..)](https://image.slidesharecdn.com/fromakafkaesquestorytothepromisedland-130707104535-phpapp02-131121034336-phpapp01/85/From-a-Kafkaesque-Story-to-The-Promised-Land-at-LivePerson-26-320.jpg)


![References
•
[1]Satisfying new requirements for Data Integration By
David Loshin
•
•
•
•
•
[2]Apache Kafka
[3]Kafka API
[4]Kafka 0.8 Quick Start
[5]Apache Avro
[5]Storm](https://image.slidesharecdn.com/fromakafkaesquestorytothepromisedland-130707104535-phpapp02-131121034336-phpapp01/85/From-a-Kafkaesque-Story-to-The-Promised-Land-at-LivePerson-29-320.jpg)


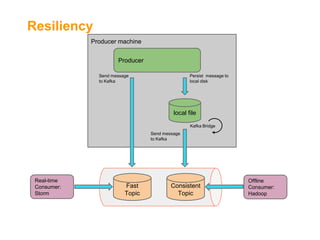
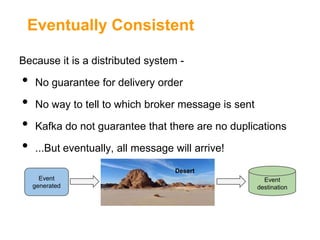
The document outlines the architecture and challenges of implementing a data platform using Kafka alongside other technologies like Hadoop and Storm. It emphasizes the importance of high throughput, availability, and real-time data processing while detailing the integration and operational aspects of managing data with a single source of truth and schemas using Avro. Additionally, it discusses the limitations of Kafka such as maturity, lack of supporting tools, and challenges with message delivery guarantees.
















































































![Apache Avro in LivePerson [Hebrew]](https://cdn.slidesharecdn.com/ss_thumbnails/apacheavroinliveperson2014-141027092641-conversion-gate02-thumbnail.jpg?width=640&height=640&fit=bounds)






















![Getting Started with Apache Spark: Big Data Made Simple [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/apachesparkgettingstarted-260203175547-8361bcc3-thumbnail.jpg?width=640&height=640&fit=bounds)


