
Downloaded 36 times









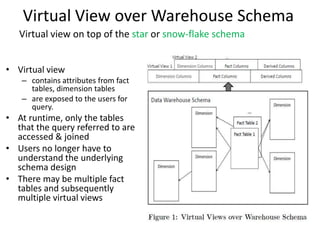






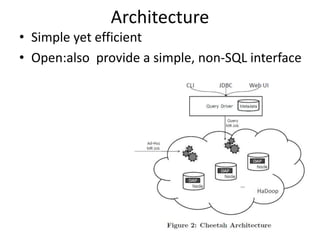








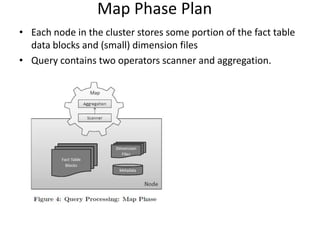


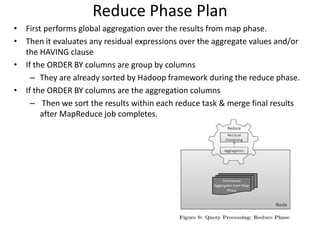




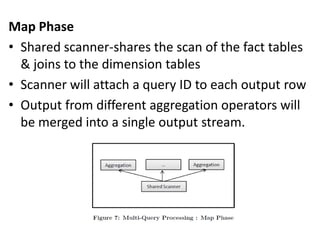
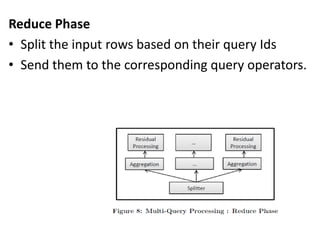



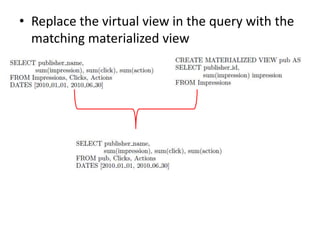










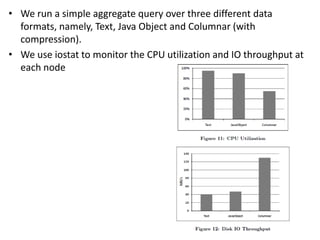







Cheetah is a custom data warehouse system built on top of Hadoop that provides high performance for storing and querying large datasets. It uses a virtual view abstraction over star and snowflake schemas to provide a simple yet powerful SQL-like query language. The system architecture utilizes MapReduce to parallelize query execution across many nodes. Cheetah employs columnar data storage and compression, multi-query optimization, and materialized views to improve query performance. Based on evaluations, Cheetah can efficiently handle both small and large queries and outperforms single-query execution when processing batches of queries together.







![Kb 40 kevin_klineukug_reading20070717[1]](https://cdn.slidesharecdn.com/ss_thumbnails/kb40kevinklineukugreading200707171-101026100915-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)















































































