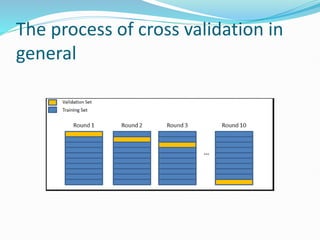
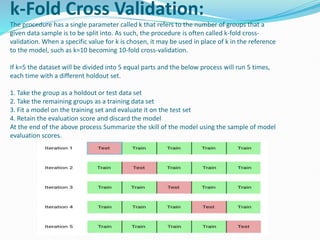
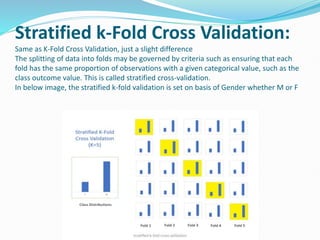
The document discusses the concepts of underfitting and overfitting in machine learning, explaining that overfitting occurs when a model captures noise in the data, leading to poor performance on new data, while underfitting arises when a model is too simple to capture underlying trends. It emphasizes the importance of cross-validation as a technique to mitigate overfitting by evaluating models on different subsets of data, with methods such as k-fold and stratified k-fold cross-validation highlighted. The document provides guidance on how to select the value of k and explains leave one out cross-validation (LOOCV) as a method to assess model performance more rigorously.





































































![Hacking-Uncovered-How-People-Get-Hacked-and-How-to-Stay-Safe[1].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/hacking-uncovered-how-people-get-hacked-and-how-to-stay-safe1-260130170011-4883a9c7-thumbnail.jpg?width=640&height=640&fit=bounds)

















![7.__Developing_a_Research_Proposal[1].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/7-260131073037-df92dd7d-thumbnail.jpg?width=640&height=640&fit=bounds)