
Downloaded 130 times










![Pig Latin-Operators
• LOAD : LOAD 'data' [USING function] [AS schema];
where, „data‟ : Name of file or directory
USING, AS : Keywords
function : Load function.
schema : Loader produces data of type specified by schema. If data does not
conform to schema, error is generated.
ex: LOAD `clicks‘ AS (userid, pageid, linkid, viewedat);
LOAD `query_log.txt‘ USING myLoad() AS (userId, queryString, timestamp);
• STORE : Stores results to file system
– STORE alias INTO 'directory' [USING function];
where, alias : name of relation
INTO, USING : keywords
„directory‟ : storage directory‟s name. If directory already exists,
operation fails
function: Store function.
ex: STORE result INTO `myOutput';
STORE query_revenues INTO `myoutput‘ USING myStore();](https://image.slidesharecdn.com/pig-130207065218-phpapp01/85/Pig-Experience-12-320.jpg)
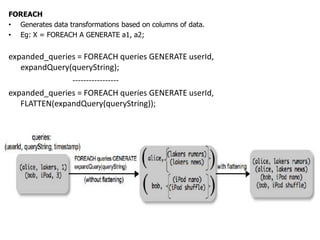
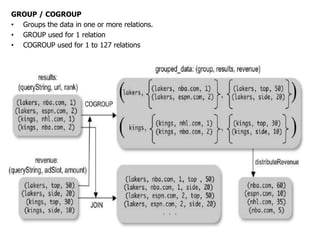






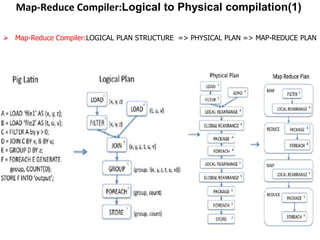
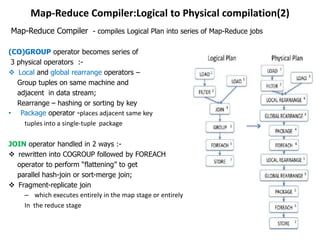



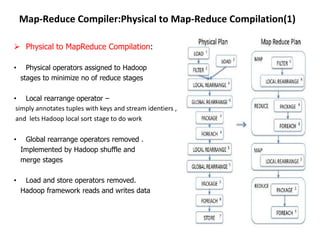


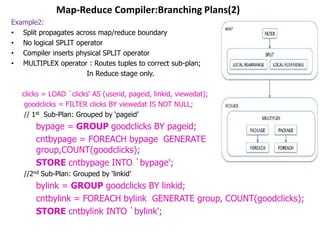

















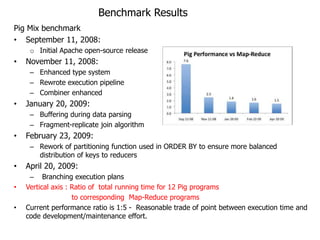






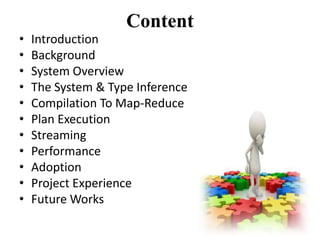
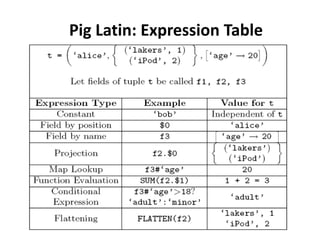
This document describes the Pig system, which is a high-level data flow system built on top of MapReduce. Pig provides a language called Pig Latin for analyzing large datasets. Pig Latin programs are compiled into MapReduce jobs. The compilation process involves several steps: (1) parsing and type checking the Pig Latin code, (2) logical optimization, (3) converting the logical plan into physical operators like GROUP and JOIN, (4) mapping the physical operators to MapReduce stages, and (5) optimizing the MapReduce plan. This allows users to write data analysis programs more declaratively without coding MapReduce jobs directly.



































































