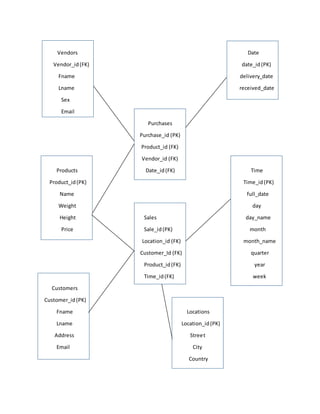
1. Vendors Date
Vendor_id(FK) date_id(PK)
Fname delivery_date
Lname received_date
Sex
Email
Purchases
Purchase_id (PK)
Product_id (FK)
Vendor_id (FK)
Products Date_id(FK) Time
Product_id(PK) Time_id(PK)
Name full_date
Weight day
Height Sales day_name
Price Sale_id(PK) month
Location_id (FK) month_name
Customer_Id (FK) quarter
Product_id(FK) year
Time_id(FK) week
Customers
Customer_id(PK)
Fname Locations
Lname Location_id(PK)
Address Street
Email City
Country
2. 2. Identification and explanation of the source systems for the data warehouse.
Data source for our data warehouse come from both formal applications and informal sources.
Formal applications include our operational system used by sales department and purchasing
department to record values for various attributes of each transaction. We will ask for help from
the IT department to extract the data for us by querying the database with SQL or by using a
ETL tool. Of course, in order to speed up the favor, we will bring an IT person on board. The
extracted data can then be loaded into staging area directly or into flat files for further
manipulation. But for data come from applications like legacy system, mid range CPU, and
Excel files, we then ask the IT specialist to extract the data for us, and then load these data into a
flat file, from where the data can be loaded into staging area or further manipulated. As for data
from informal sources, first of all, we need to collect all the data if possible, because we don’t
want to create confusion by having multiple versions of the data. Therefore, we will first ask
everyone within sales and purchasing department to turn in all the data they have in hand if any,
then we will need to organize the data, and clean them up. Last but not the least, we will have to
conform and across verify data just to avoid data missing and data redundancies.
3. detail description of the ETL process
To get started, we will extract data from our various data resources, with some being informal
and others formal. The general guideline behind the extraction process is not only to extract as
much relevant data as possible, but also to understand the source, and its associated business
purpose. To understand a source, we to need to know the following aspects of it: hardware,
operating systems, communication protocols, file form (database, file management systems,
Excel file, flat file…). After understanding each source, we need to determine the system-of-
record. If we are directly extracting from the source system, then we are extracting from system-
of-record, but if we are extracting from a second or even third system, then we will have to make
sure the data transformation between the system-of-record and second or third system is valid.
After all the data is extracted, we need to find out the roadmap from each source to the final data
warehouse, and all the extracts will be loaded only once at inception. In order to do that, we need
to create a mapping from source to target. In this document, we will record the following things:
1. Table name
2. Column name
3. Data type (character, numeric, decimal…)
4. Length
5. Column description
6. Source system
7. Source table/file
8. Source column/field
9. Data transformation
3. Last but not the least in the extraction process, we need to determine which approach to take to
detect changes to data. In our case, we will ask the source application owners to add timestamp
for new records that users insert into the system.
In the transformation process, the first thing we need to take care of is the data integration issue,
which is caused by different operational systems not having the same standard in keeping the
data. In order to minimize our efforts on integrating data from multiple sources, we will take on
the phased implementation approach, and we will perform data transformation dusting
extraction. By doing that, we require source application team to prepare the data based on our
needs of the data. To be specific on things we need to do in the transformation process, I will
explain our process in a step-by-step fashion.
1. Integration: we will create surrogate primary keys, and creating connections between
each system and the common system, which, in our case, in the sales operational
database. After all the connection have been built up, we will draw the roadmap to
demonstrate all these relationships.
2. Type Conversion: this step involves data transportation, therefore we need to transform
our data from one system to a different system. To do that we will use a file transfer
protocol.
3. Referential integrity checking: since each table in a database should have connections
with other tables, then there is no reason for data in one specific table to stand alone.
Therefore in this step we need to make sure the connection between data exists.
4. Normalizing data, then de-normalizing it: the reason for us to normalize data first, then to
de-normalize it is because we need to make sure data integrity.
5. Mapping of codes to description: make everything that the business users see readable for
them.
6. Cleansing of data: multiple ways to ensure data standardization
7. Building aggregate tables: our database architecture calls for data aggregations because
we have hierarchical dimensions in several dimensions. Therefore, in order to improve
the query performance of data warehouse, we decided to build several aggregates on time
dimension, as well as locations dimension.
As the final step of the ETL process, loading is relatively easy. Yet we still need to pay attention
to several aspects of this process. For example, how are we loading data, what’s the timing of
loads, what’s the scheduling of loads, and how we are going to handle errors. First of all, we are
going to load data all at once at inception, and we are loading our data with SQL commands. As
for when and how often we are loading incremental data depends on our subject of the data
warehouse. In our case, since we are focusing on the sales and purchase side of the business,
which require data to help make short to mid-term decisions, so I believe a weekly or monthly
refresh will do the job.
All the above is a brief introduction to our ETL processes.