Download as ODP, PPTX





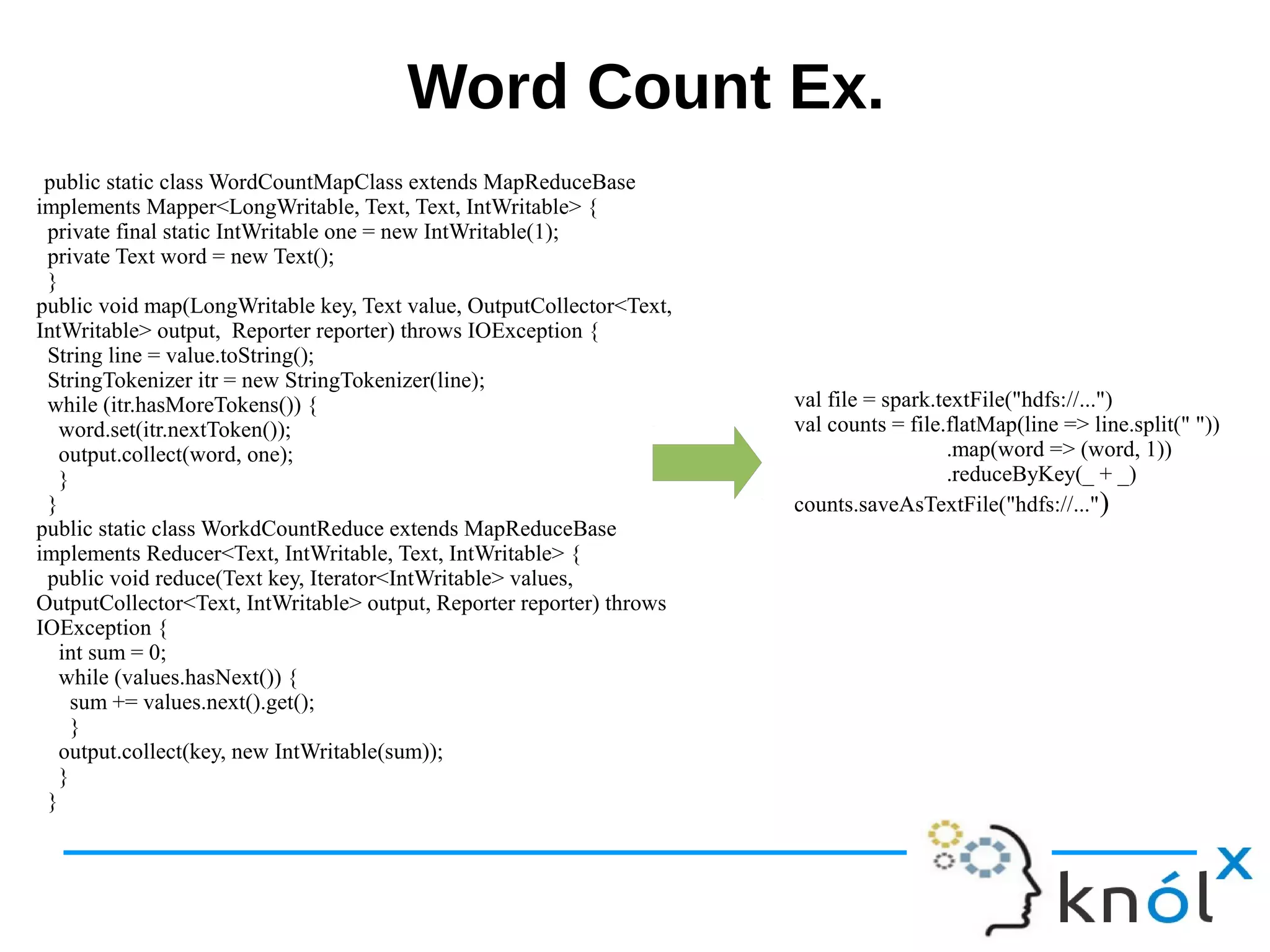




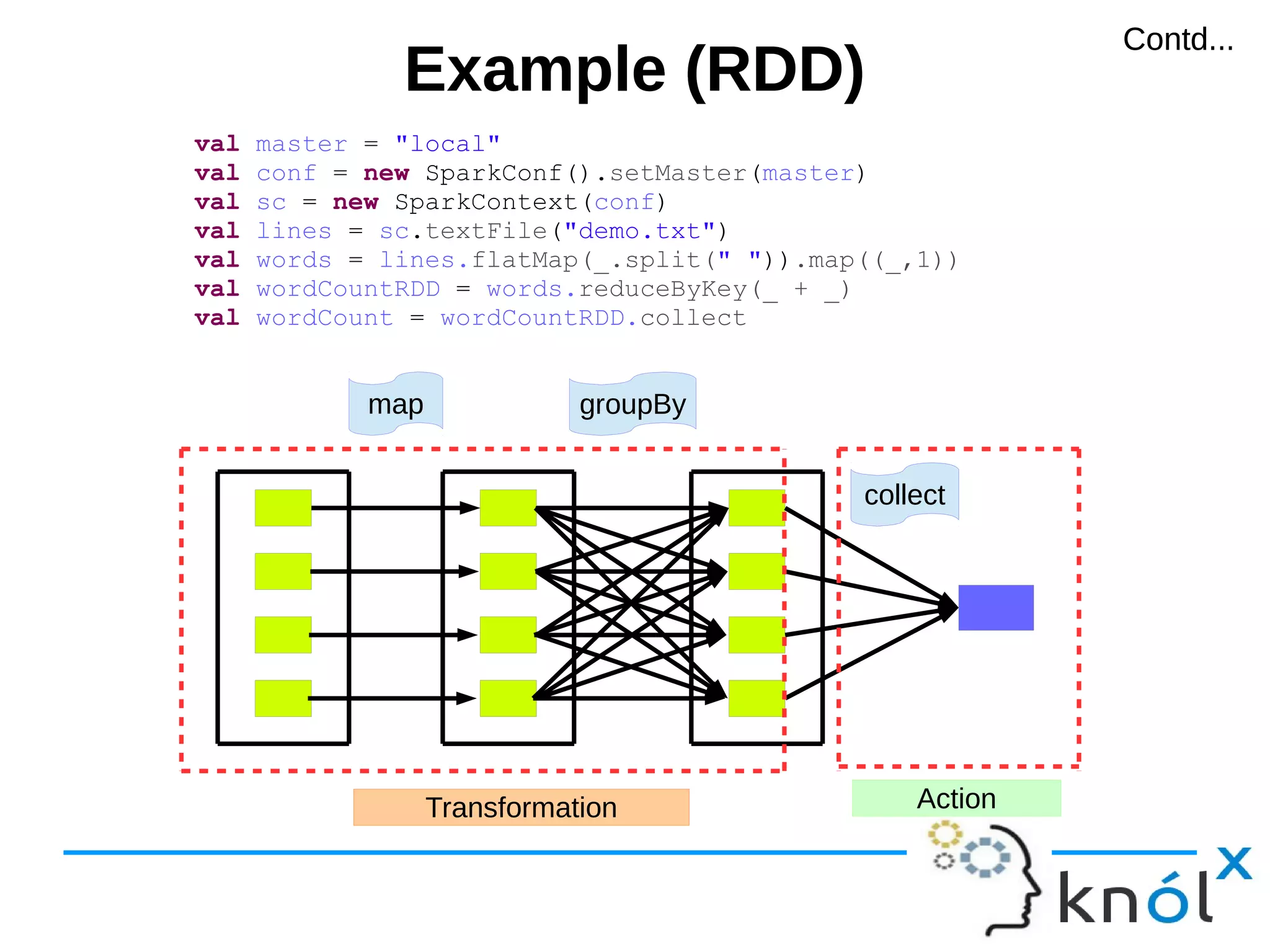
![Example (RDD)Example (RDD)
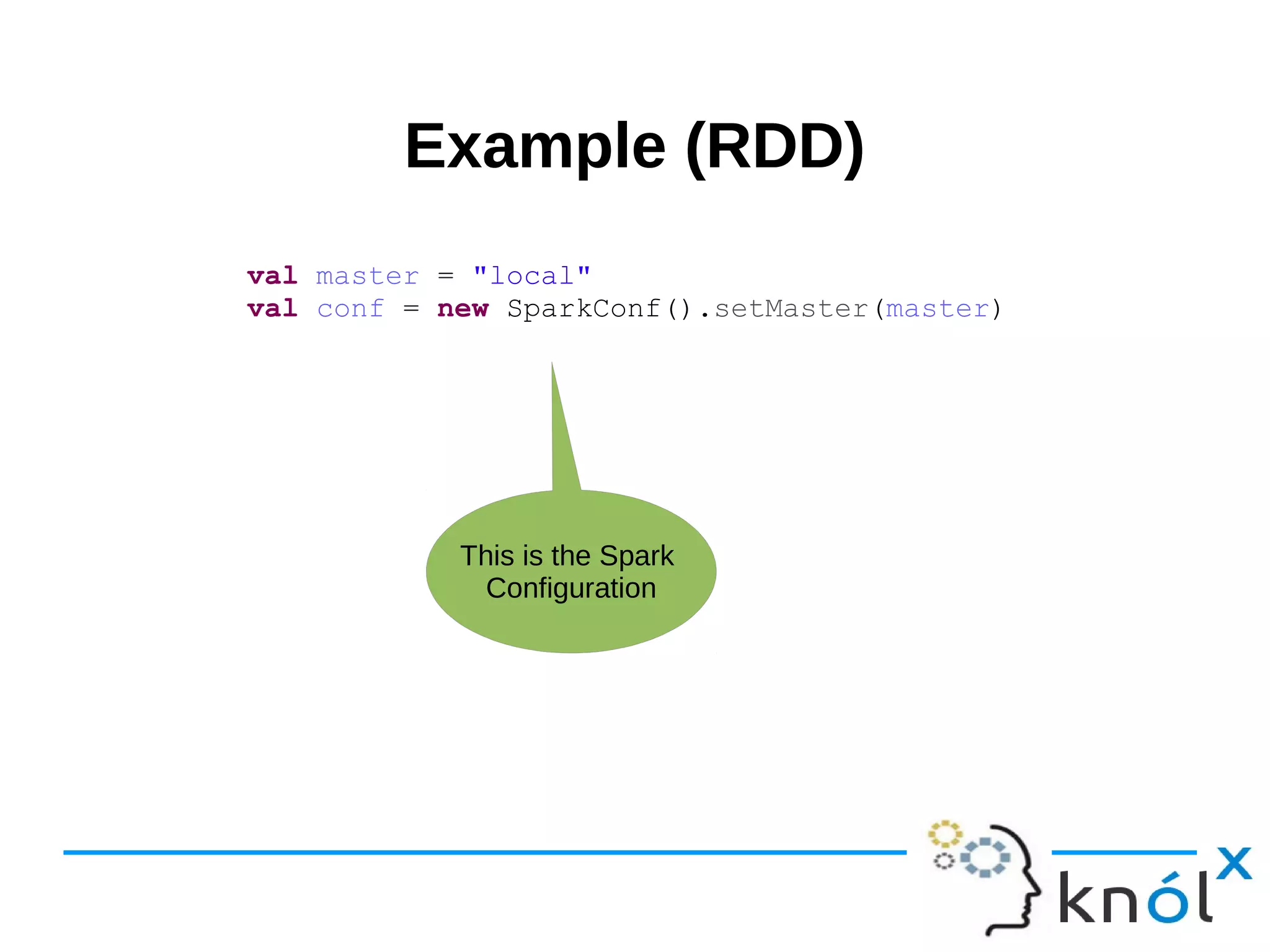
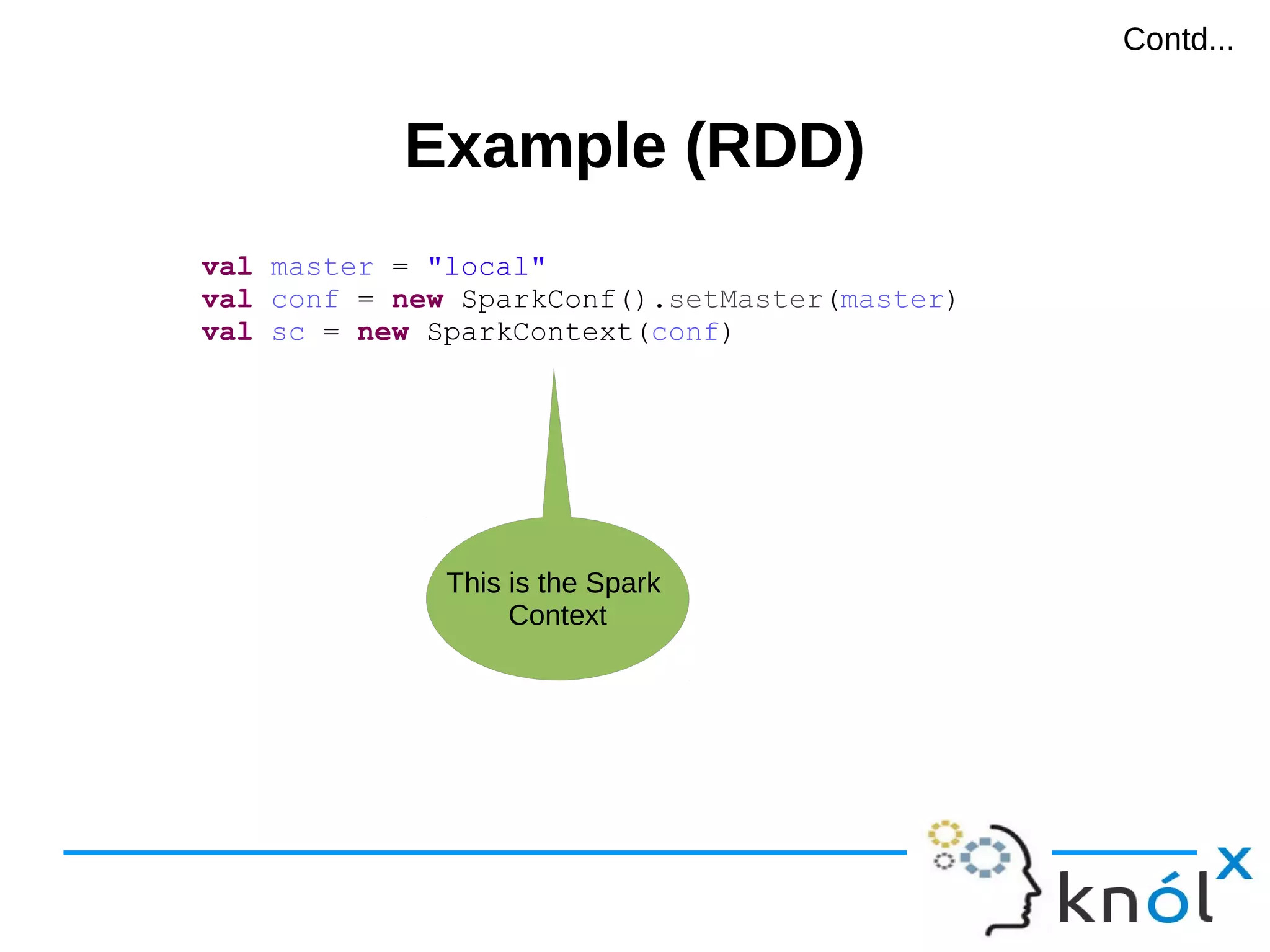
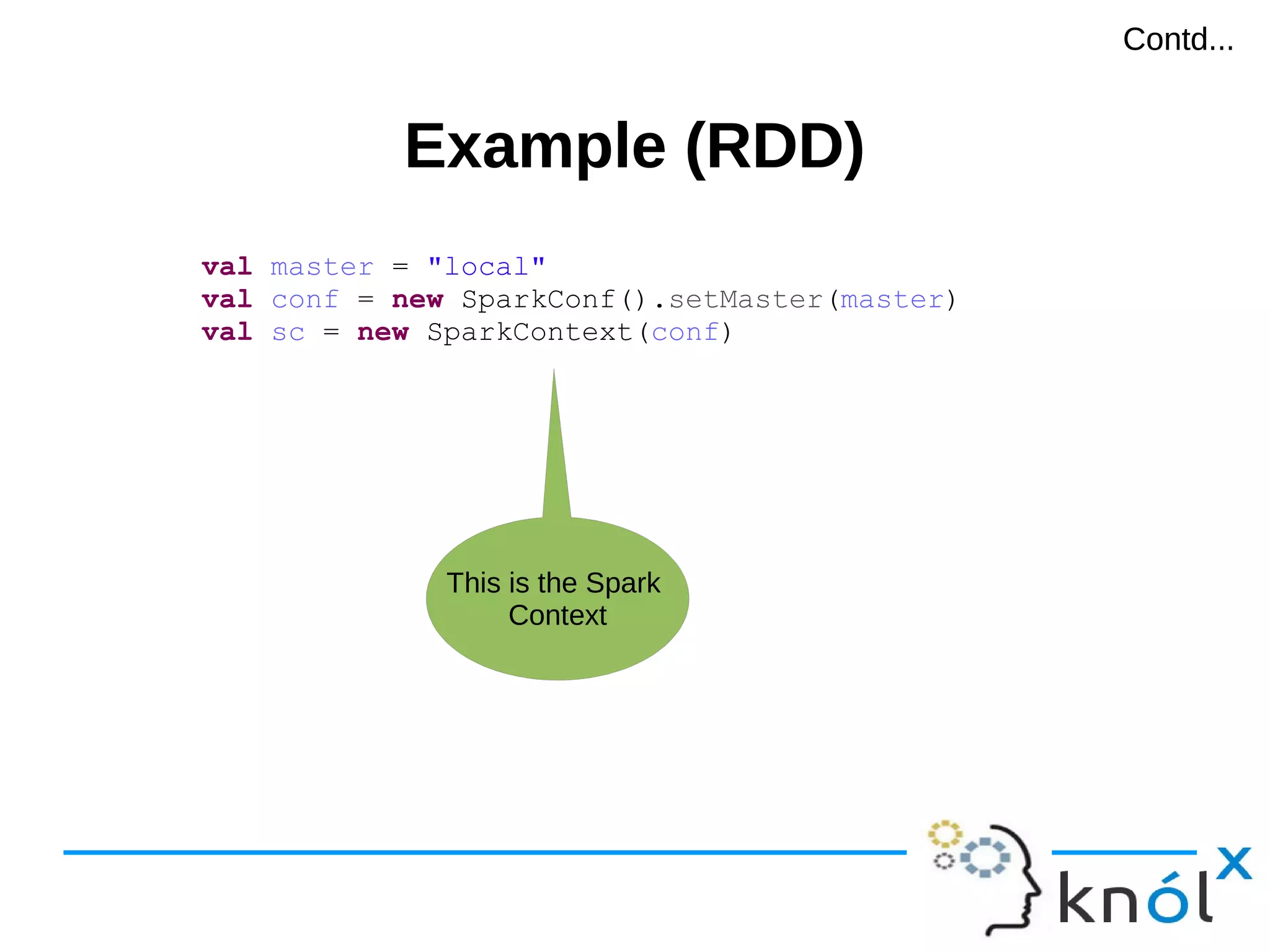
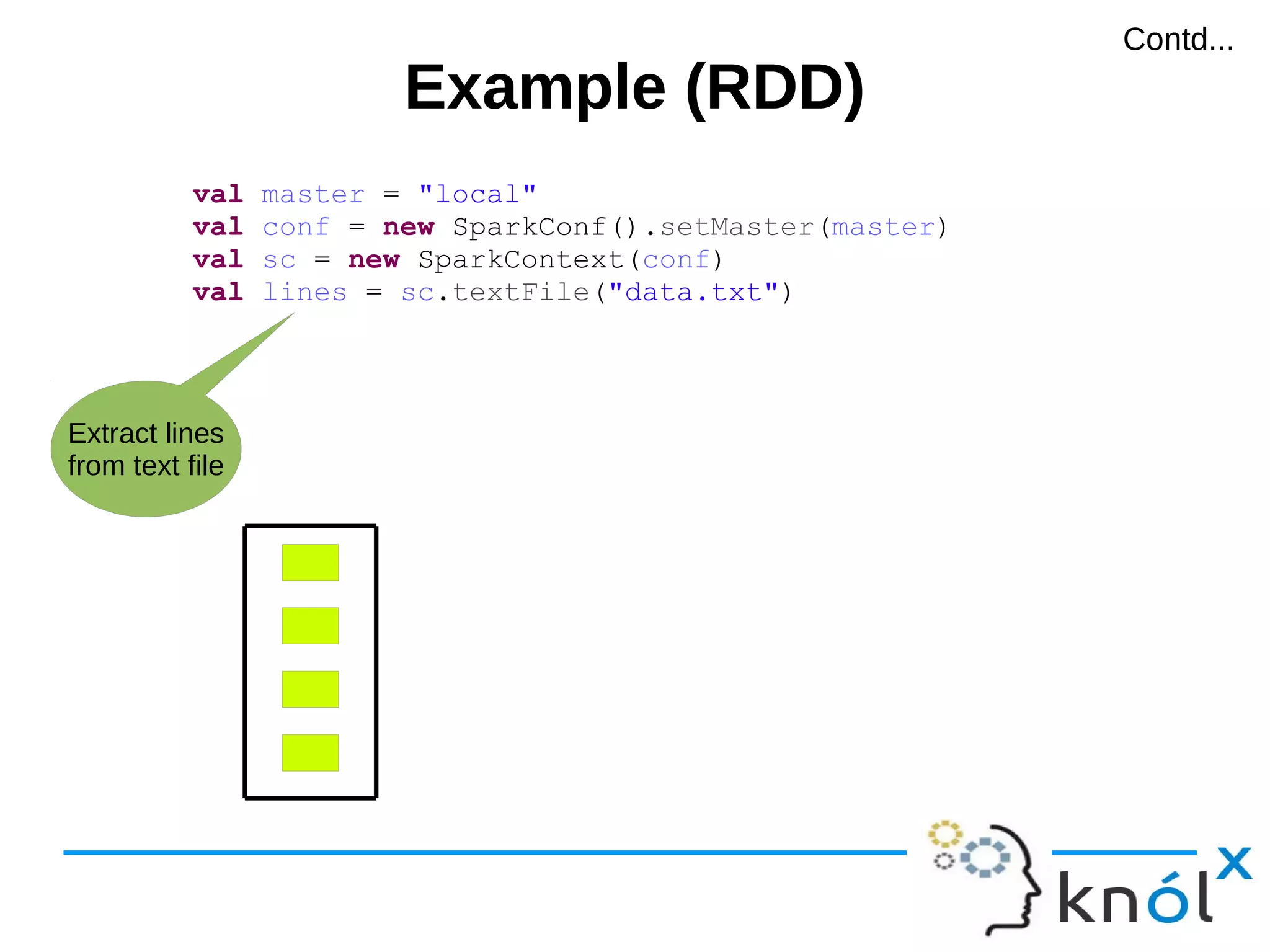
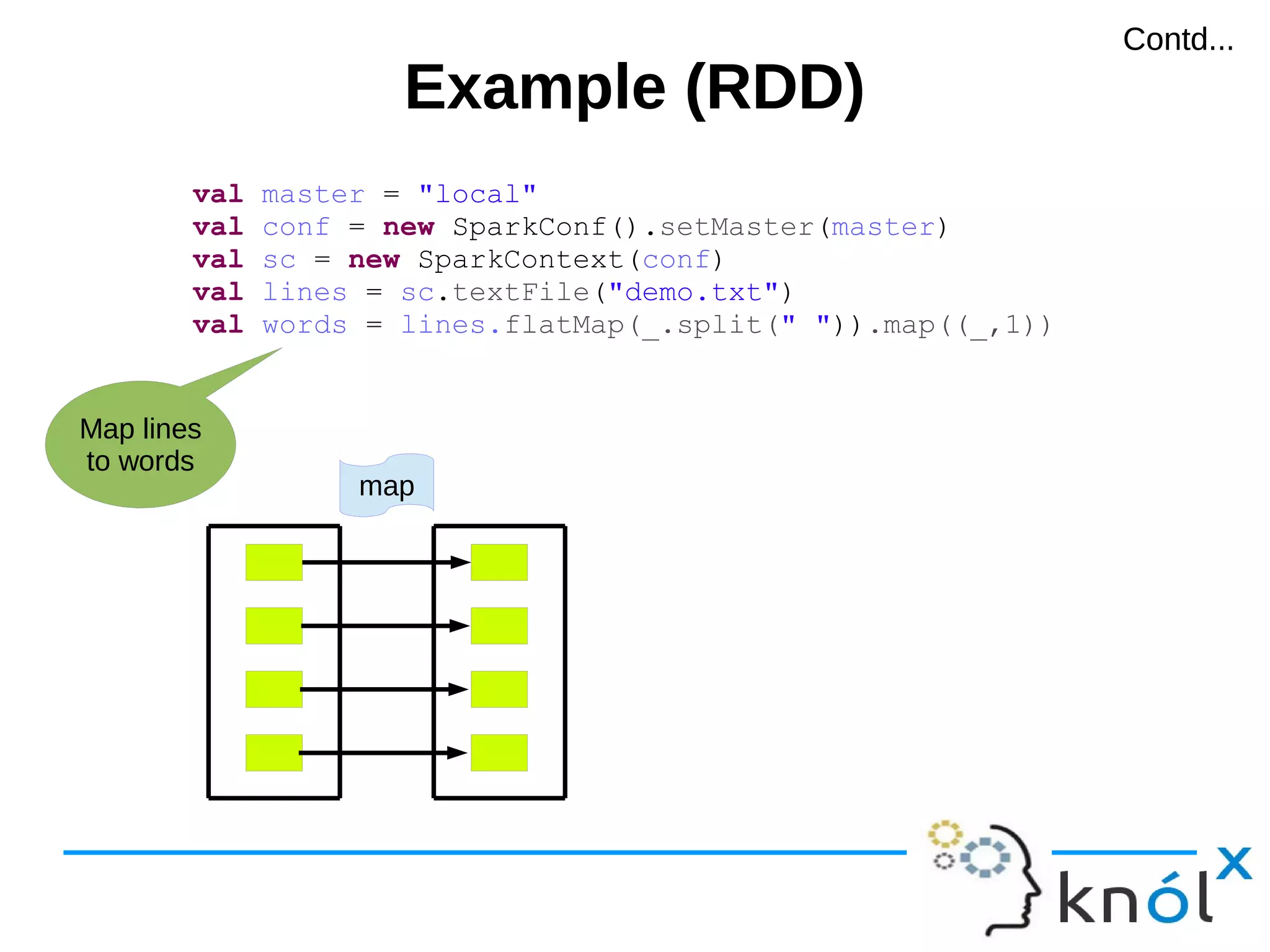
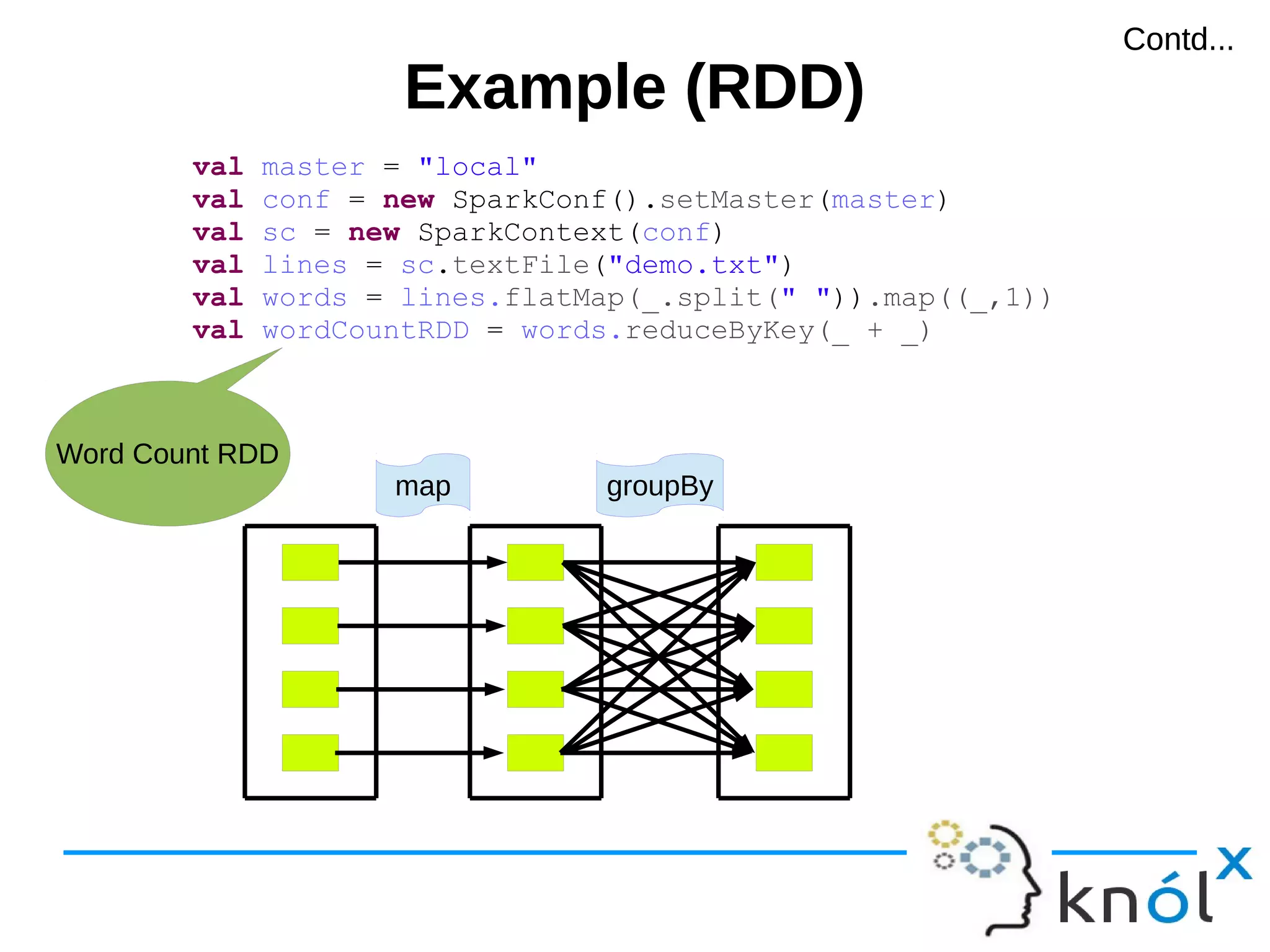
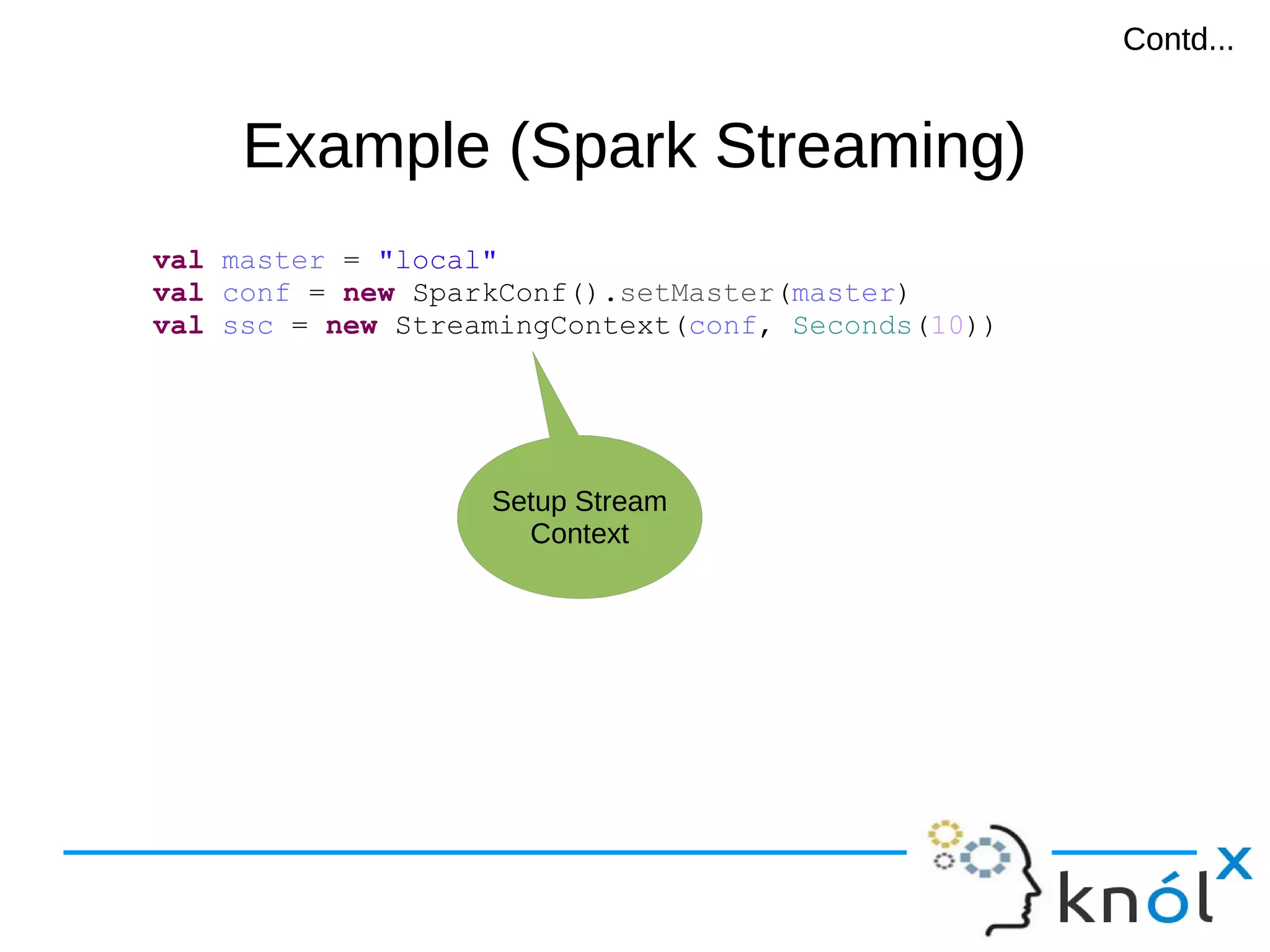
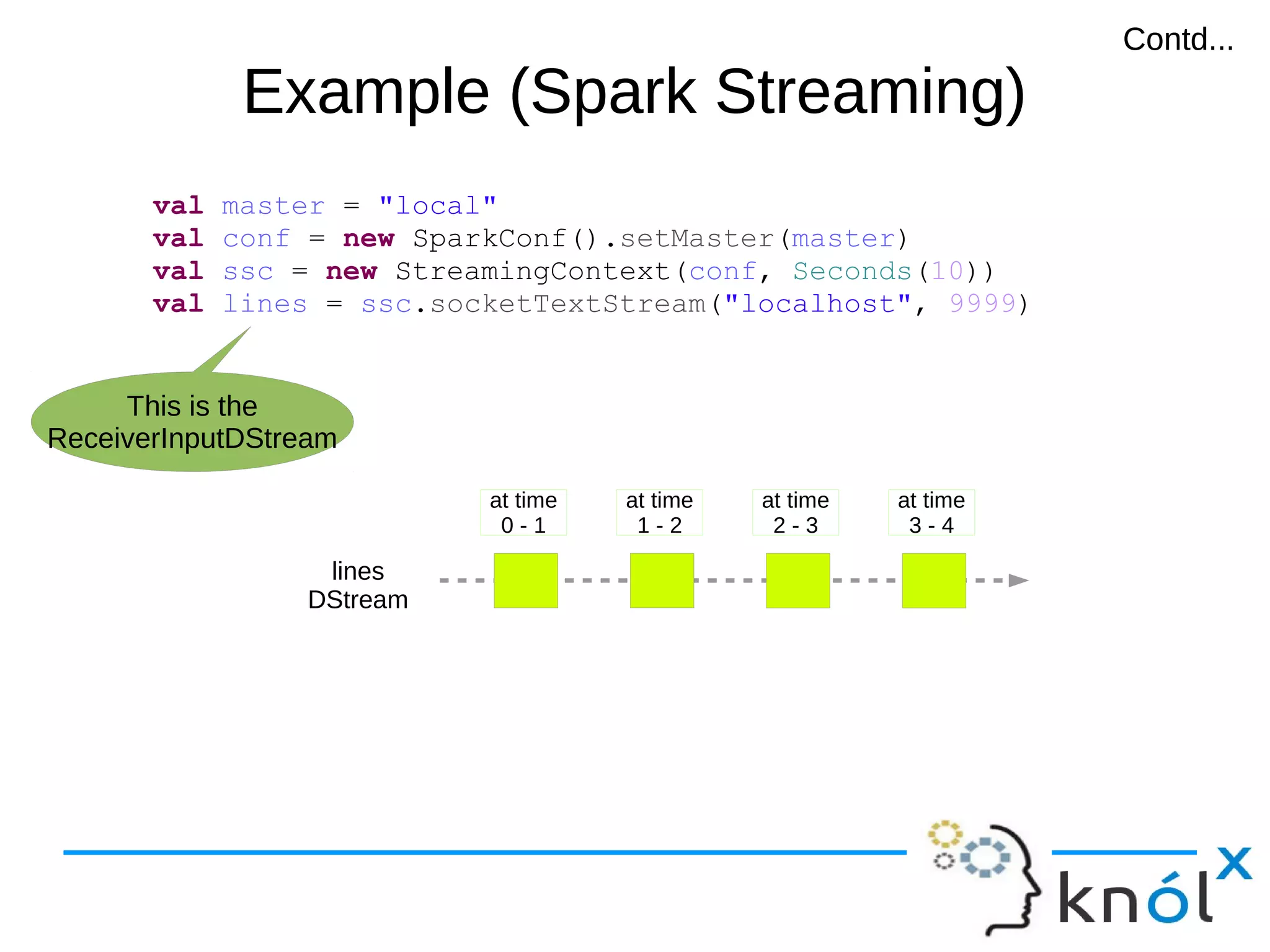
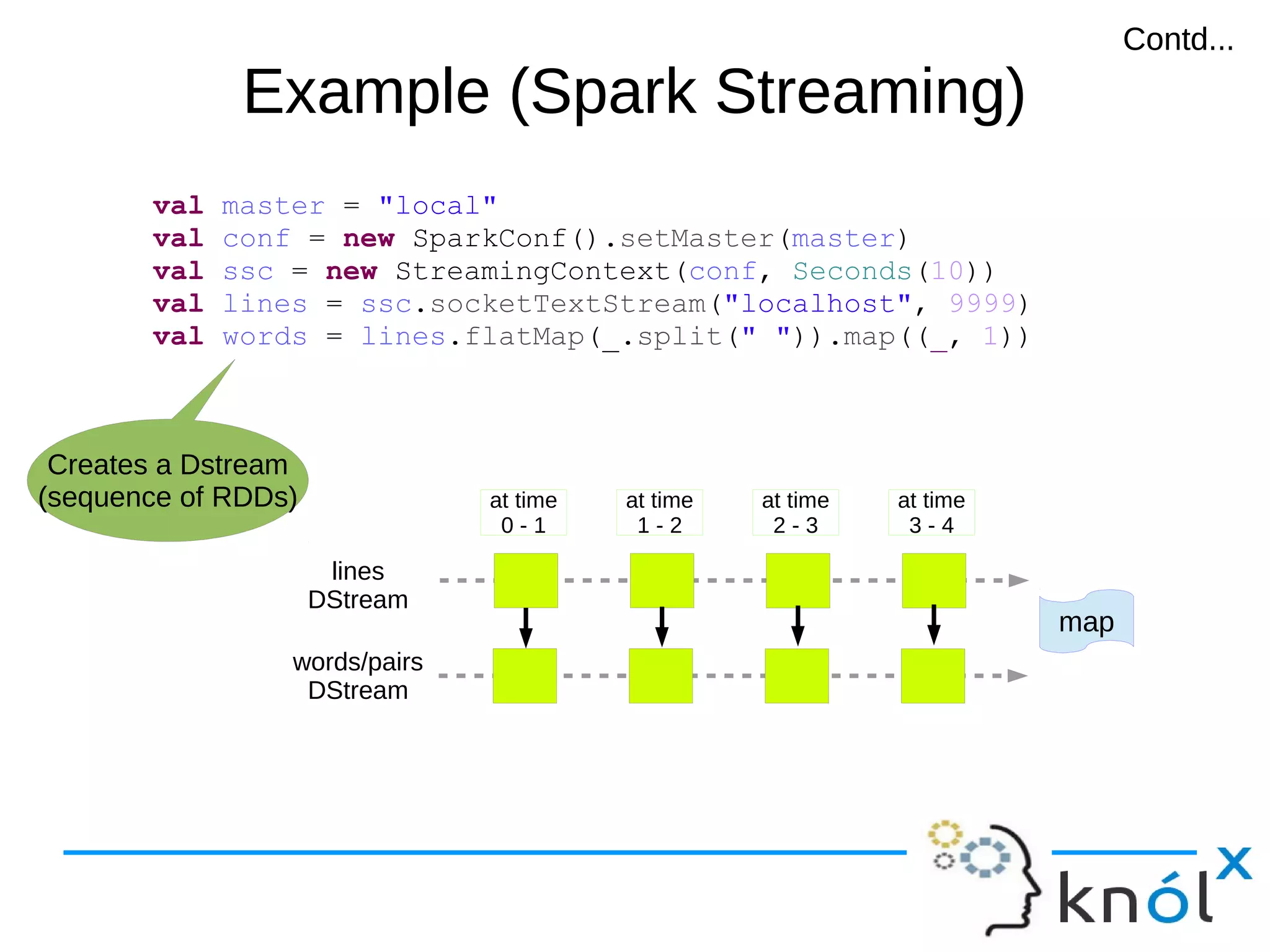
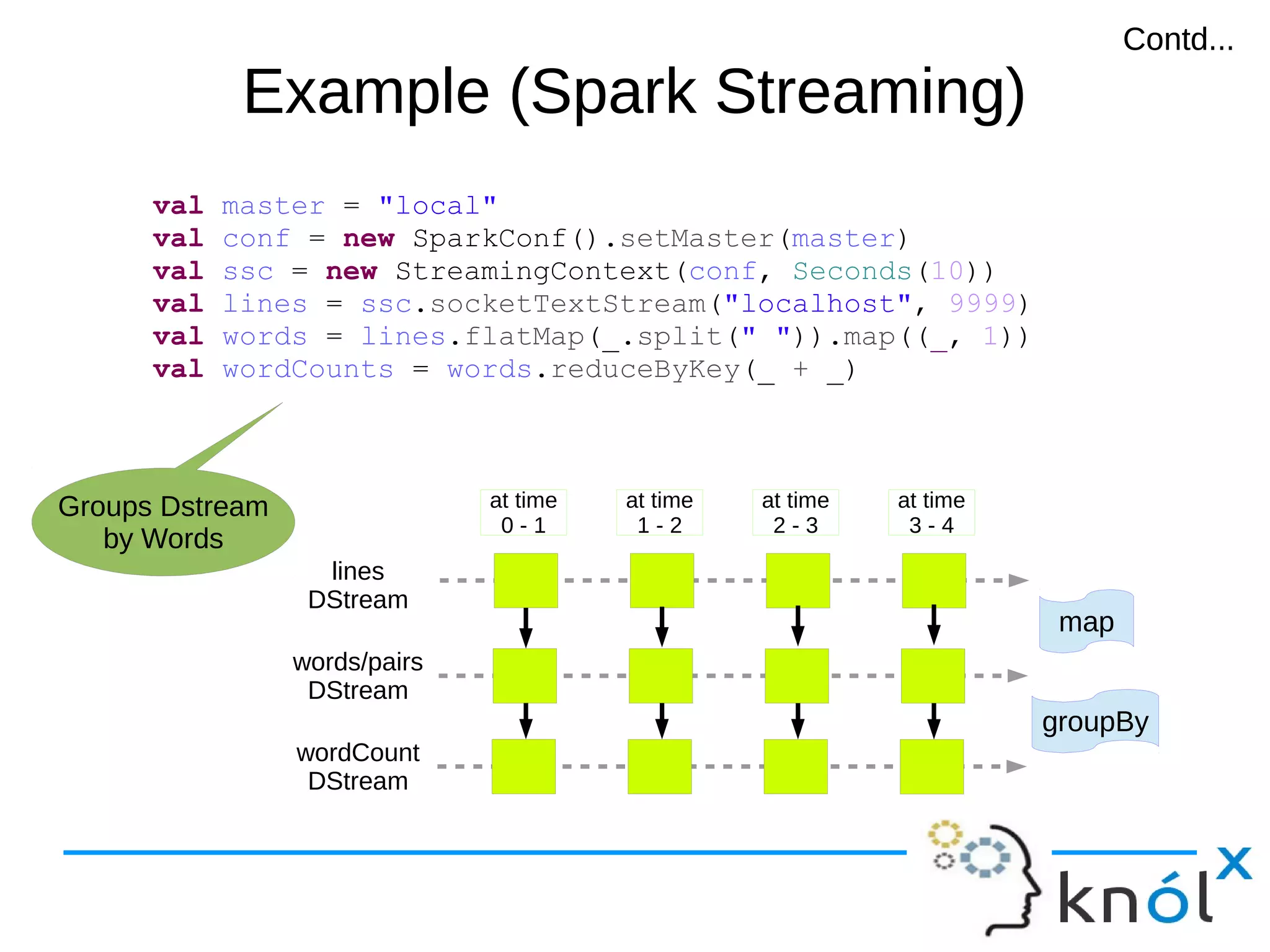
val master = "local"
val conf = new SparkConf().setMaster(master)
val sc = new SparkContext(conf)
val lines = sc.textFile("demo.txt")
val words = lines.flatMap(_.split(" ")).map((_,1))
val wordCountRDD = words.reduceByKey(_ + _)
val wordCount = wordCountRDD.collect
Map[word, count] map groupBy
collect
Starts
Computation
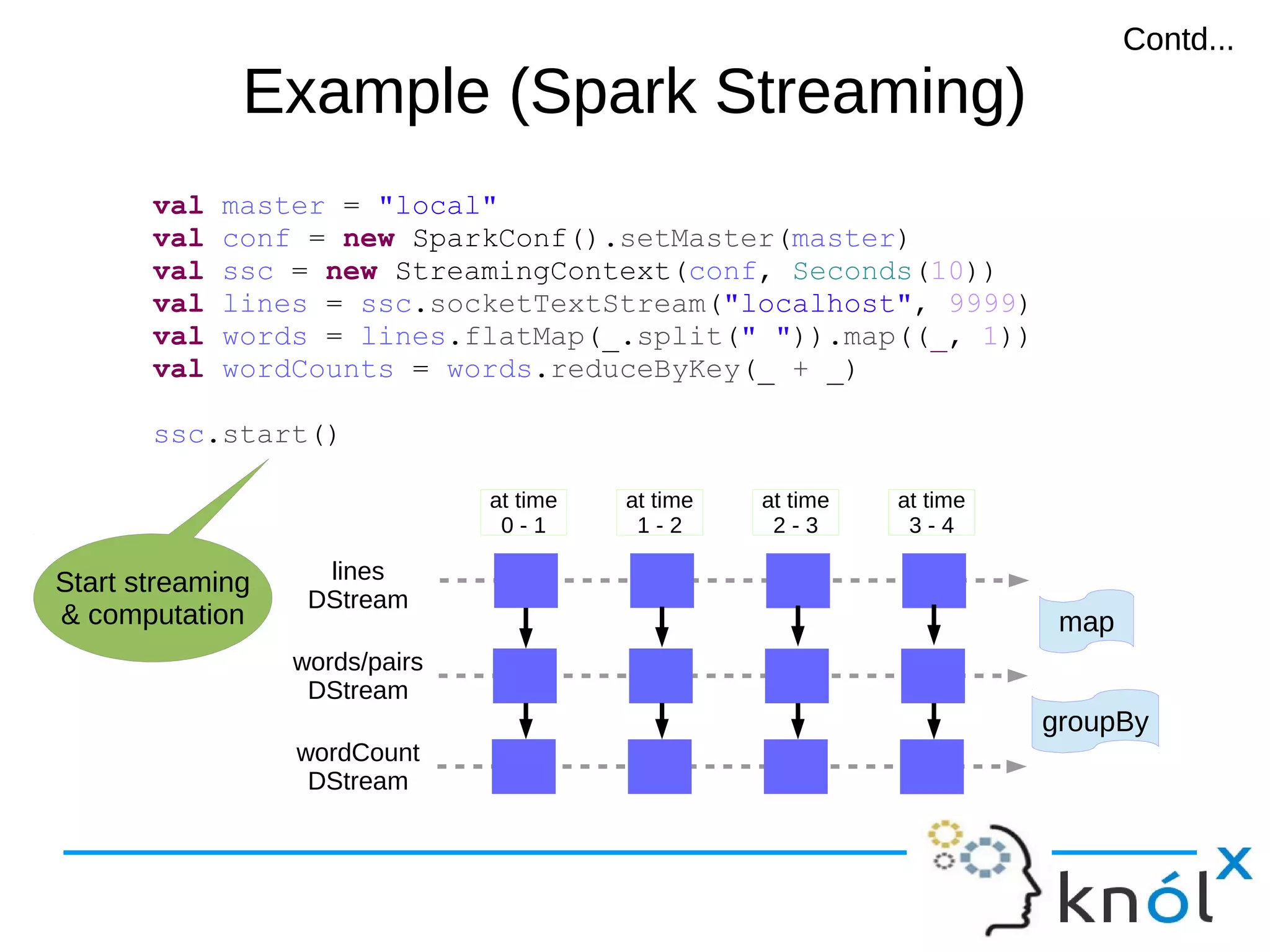
Contd...Contd...](https://image.slidesharecdn.com/sparkmeetup2-150402040552-conversion-gate01/75/Introduction-to-Spark-with-Scala-22-2048.jpg)

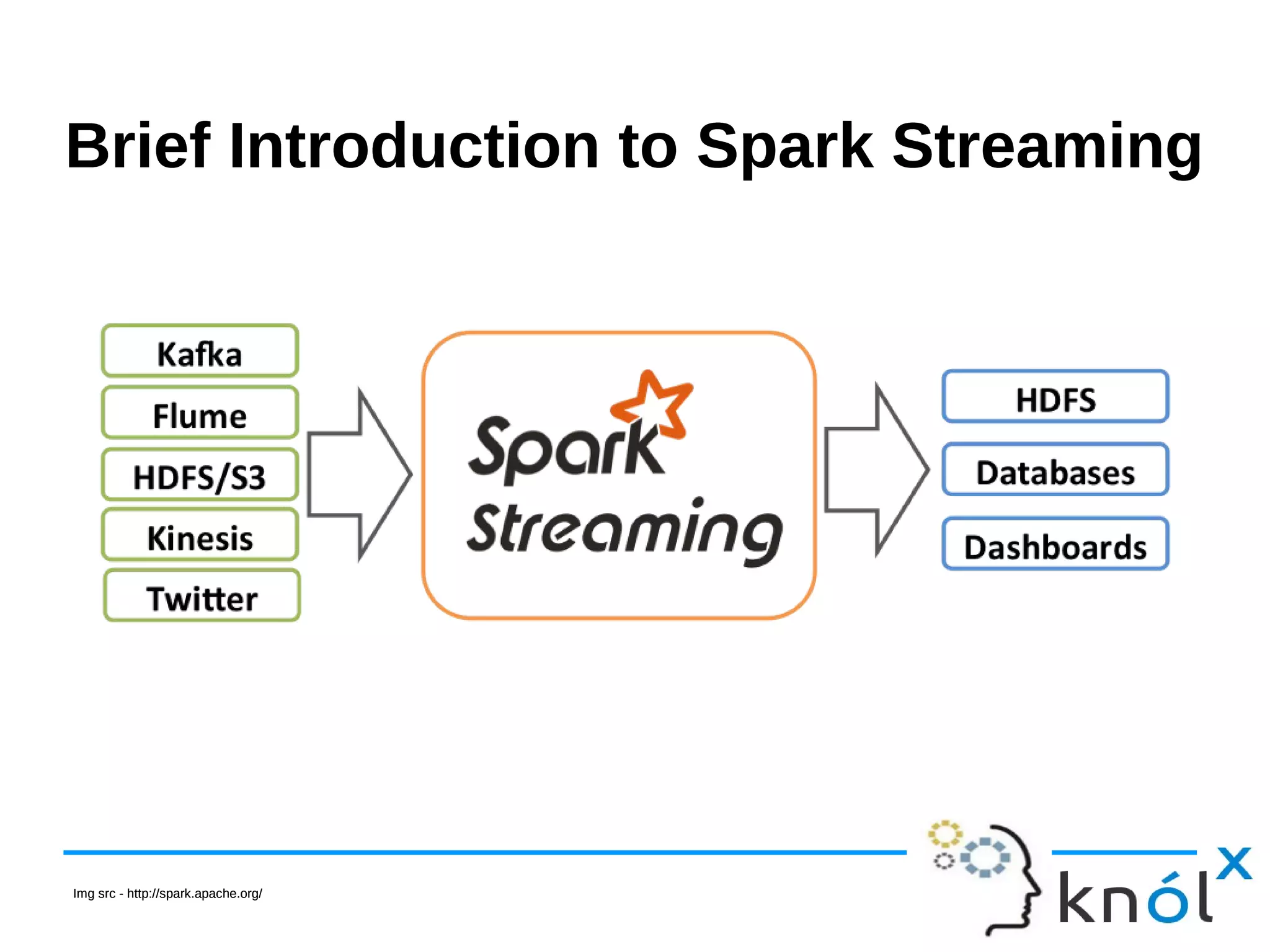
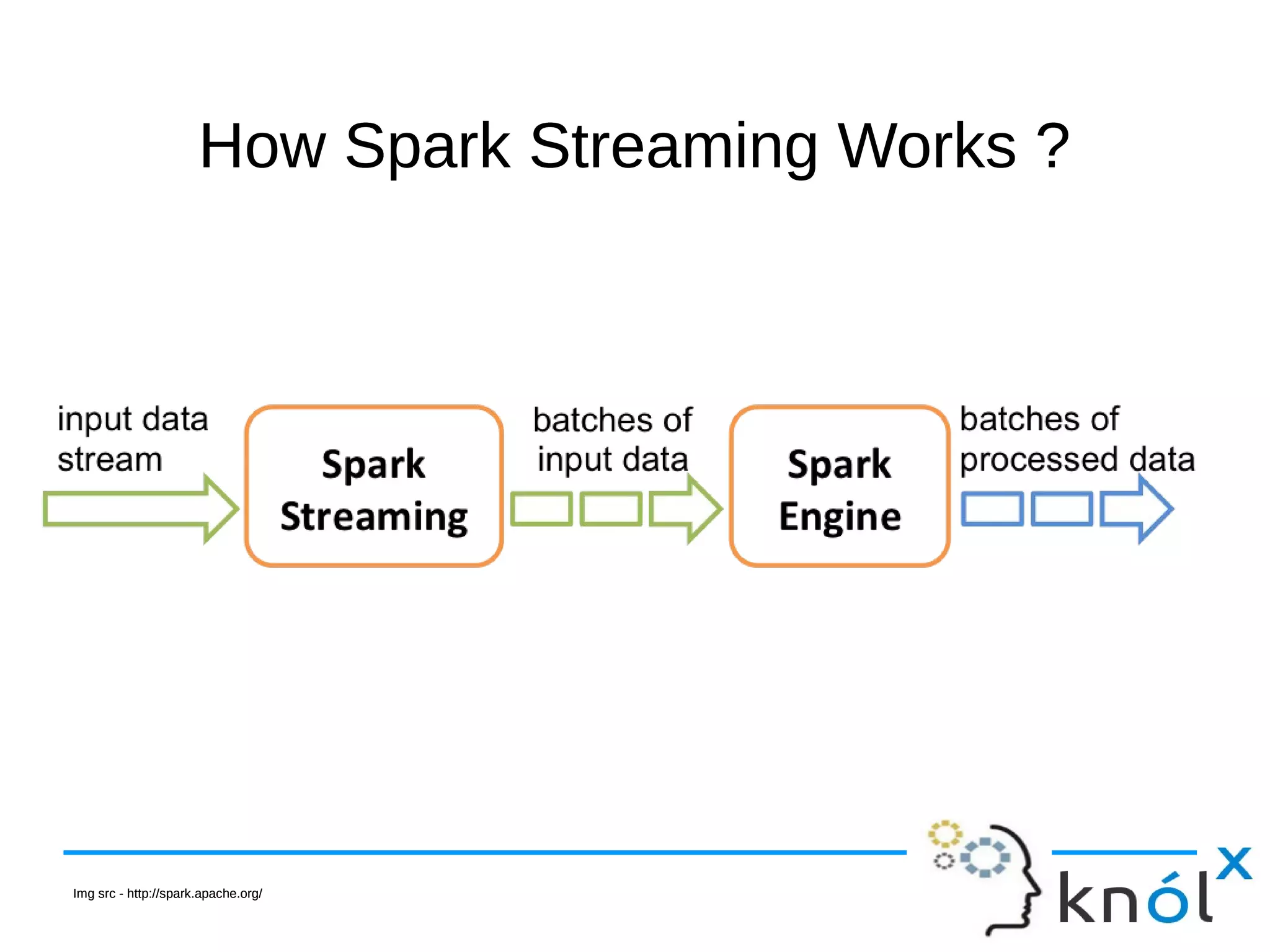










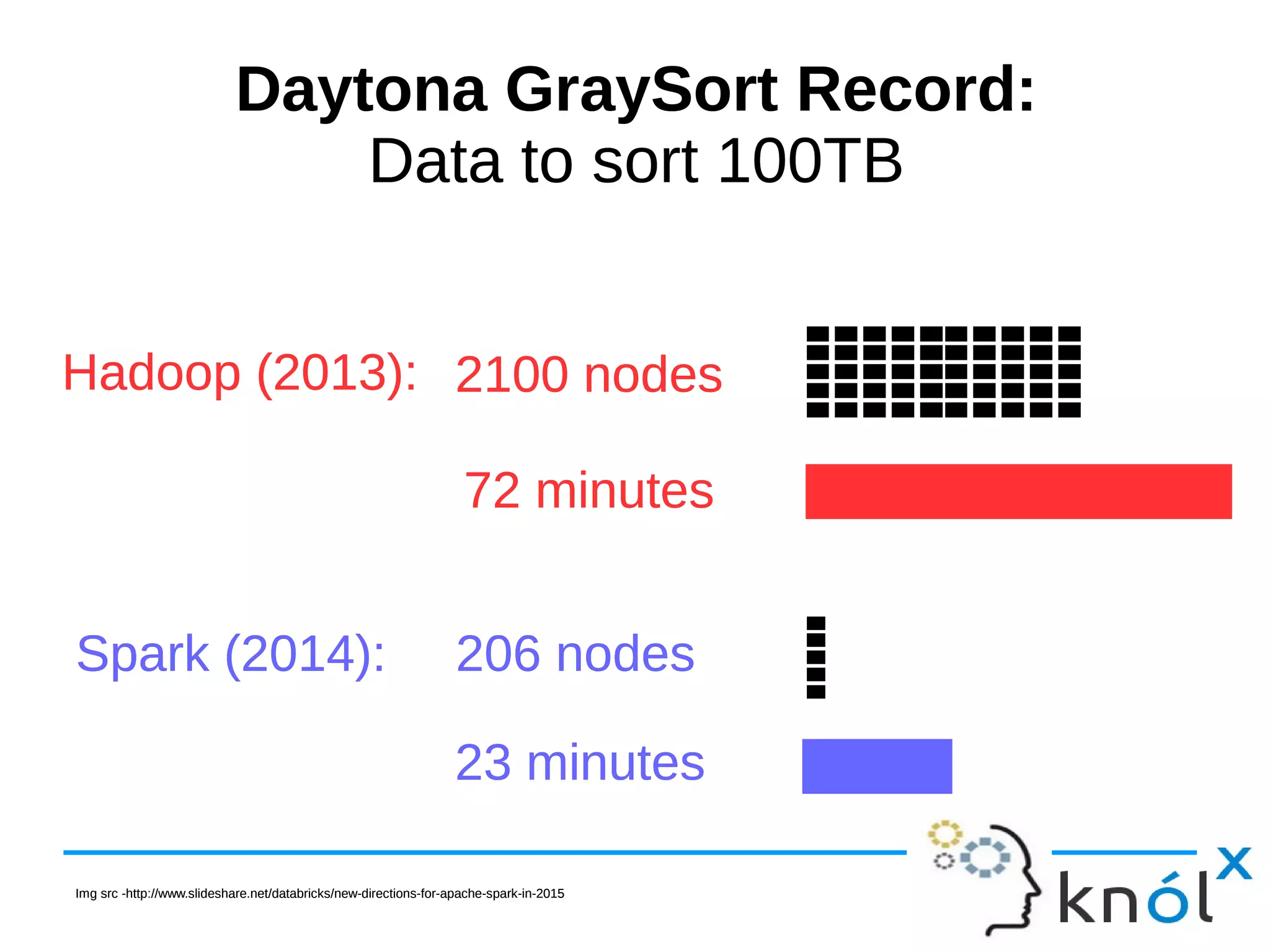
The document is a presentation on Apache Spark using Scala, outlining its significance as a fast and general engine for large-scale data processing. It introduces core concepts such as RDDs (Resilient Distributed Datasets) and Spark Streaming, providing installation steps and examples of code usage. The document also highlights Spark's evolution and its popularity in the field of data analytics.



































































