Downloaded 40 times























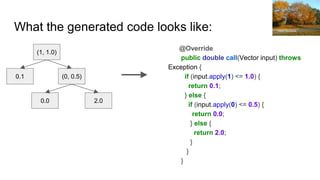





This document provides tips and tricks for scaling Apache Spark jobs. It discusses techniques for reusing RDDs through caching and checkpointing. It explains best practices for working with key-value data, including how to avoid problems from key skew with groupByKey. The document also covers using Spark accumulators for validation and when Spark SQL can improve performance. Additional resources on Spark are provided at the end.










































































