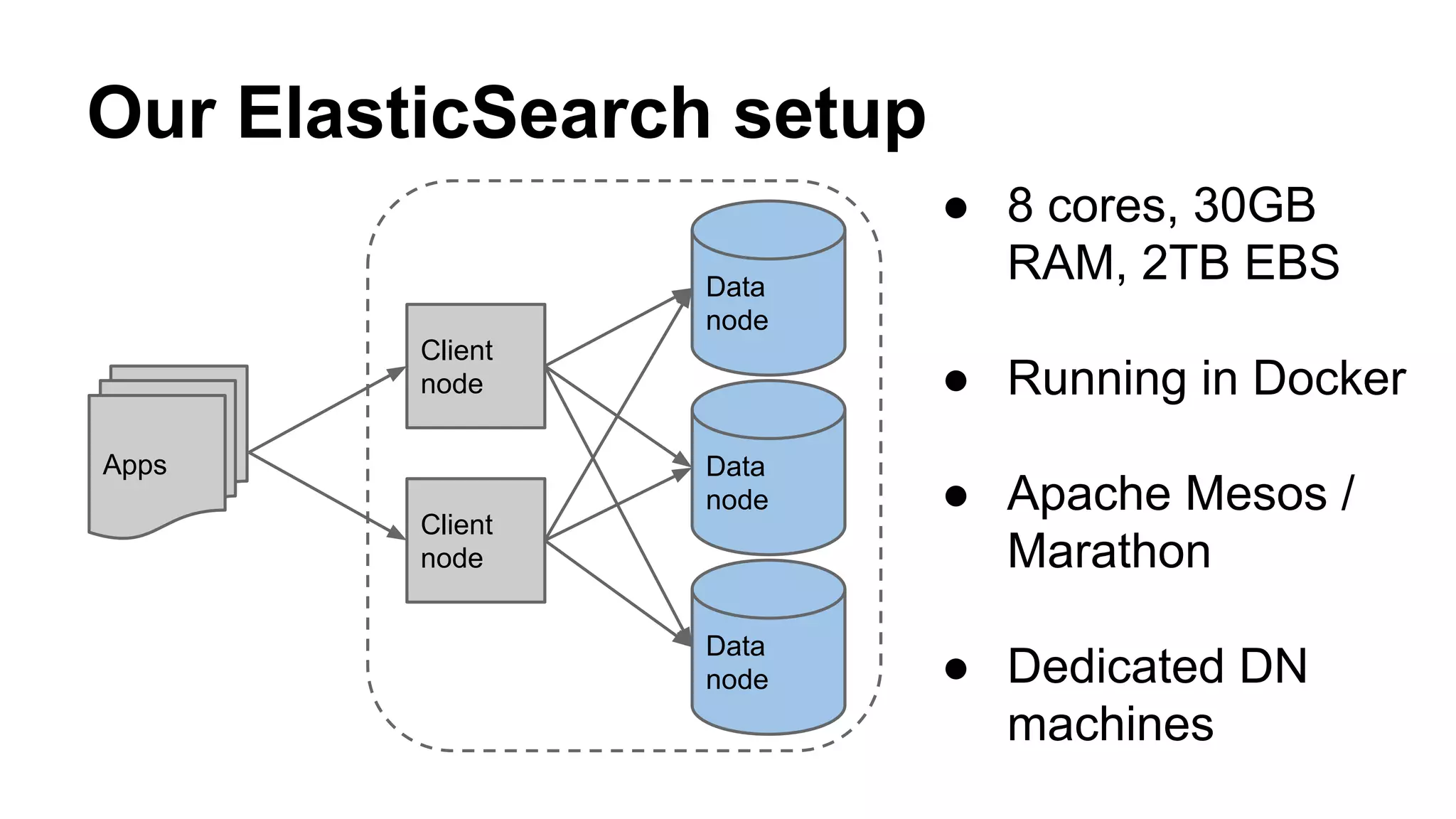
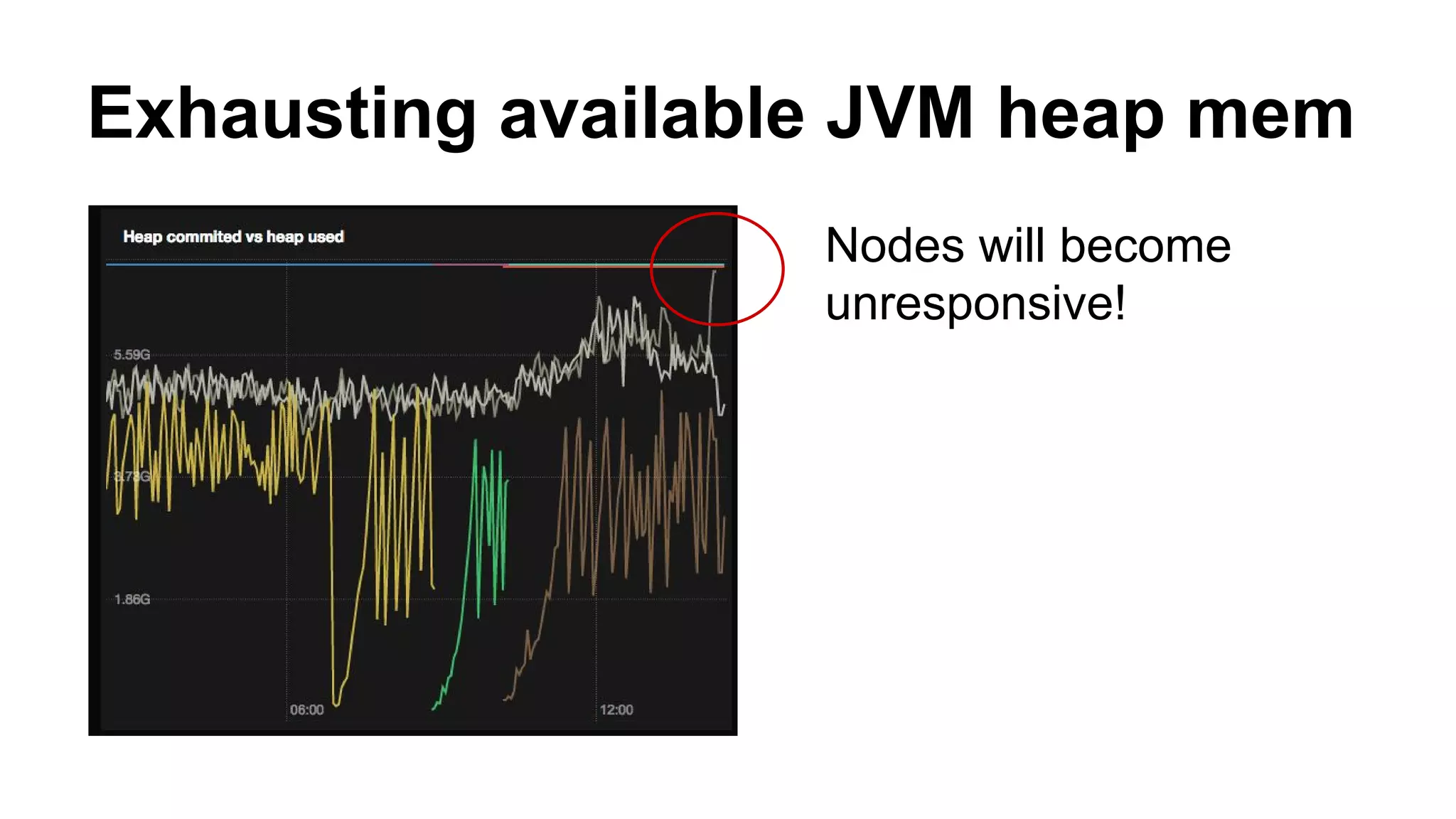
Elasticsearch 101 provides an overview of setting up, configuring, and tuning an Elasticsearch cluster. It discusses hardware requirements including memory, avoiding high cardinality fields, indexing and querying data, and tooling. The document also covers potential issues like data loss during network partitions and exhausting available Java heap memory.
























































![[2D1]Elasticsearch 성능 최적화](https://cdn.slidesharecdn.com/ss_thumbnails/2d1elasticsearch-140929192211-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)






































![Coded Agents – with UiPath SDK + LangGraph [Virtual Hands-on Workshop]](https://cdn.slidesharecdn.com/ss_thumbnails/codedagentsdeck-251215155422-5497c599-thumbnail.jpg?width=640&height=640&fit=bounds)
