Download as PDF, PPTX






![Analysis and Analyzers
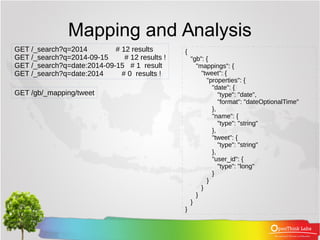
Testing Analyzers
GET /_analyze
{
"analyzer": "standard",
"text": "Text to analyze"
}
{
"tokens": [
{
"token":
"text",
"start_offset": 0,
"end_offset": 4,
"type":
"<ALPHANUM>",
"position": 1
},
{
"token": "to",
"start_offset": 5,
"end_offset": 7,
"type":
"<ALPHANUM>",
"position": 2
},
{
"token":
"analyze",
"start_offset": 8,
"end_offset": 15,
"type":
"<ALPHANUM>",
"position": 3
}
]
}](https://image.slidesharecdn.com/06mappingandanalysis-161024141453/85/06-ElasticSearch-Mapping-and-Analysis-7-320.jpg)





![Complex Core Field Types
● Besides the simple scalar datatypes that we
have mentioned, JSON also has null values,
arrays, and objects, all of which are supported
by Elasticsearch.
{ "tag": [ "search", "nosql" ]}
Multivalue Fields
"null_value": null,
"empty_array": [],
"array_with_null_value": [ null ]
Empty Fields](https://image.slidesharecdn.com/06mappingandanalysis-161024141453/85/06-ElasticSearch-Mapping-and-Analysis-15-320.jpg)


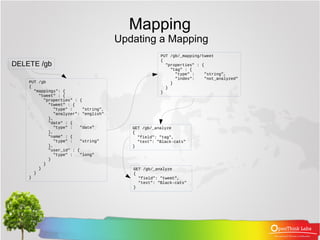
![Complex Core Field Types
How Inner Objects are Indexed
● Lucene doesn’t understand inner objects. A Lucene
document consists of a flat list of key-value pairs. In order
for Elasticsearch to index inner objects usefully, it converts
our document into something like this:
{
"tweet": [elasticsearch, flexible, very],
"user.id": [@johnsmith],
"user.gender": [male],
"user.age": [26],
"user.name.full": [john, smith],
"user.name.first": [john],
"user.name.last": [smith]
}](https://image.slidesharecdn.com/06mappingandanalysis-161024141453/85/06-ElasticSearch-Mapping-and-Analysis-18-320.jpg)
![Complex Core Field Types
Arrays of Inner Objects
● Finally, consider how an array containing inner objects would be
indexed. Let’s say we have a followers array that looks like this:
{
"followers": [
{ "age": 35, "name": "Mary White"},
{ "age": 26, "name": "Alex Jones"},
{ "age": 19, "name": "Lisa Smith"}
]
}
● This document will be flattened as we described previously, but
the result will look like this:
{
"followers.age": [19, 26, 35],
"followers.name": [alex, jones, lisa, smith, mary, white]
}](https://image.slidesharecdn.com/06mappingandanalysis-161024141453/85/06-ElasticSearch-Mapping-and-Analysis-19-320.jpg)


This document discusses mapping and analysis in ElasticSearch. It explains that mapping defines how documents are indexed and stored, including specifying field types and custom analyzers. Different analyzers, like standard, simple, and language-specific analyzers, tokenize and normalize text differently. Inner objects and arrays in documents are flattened during indexing for search. The document provides examples of mapping definitions and using the _analyze API to test analyzers.

































































































