Downloaded 864 times



![Index a document - Elasticsearch
1. Setup an index/collection
2. Define fields and types
3. Index content (using Marvel sense):
POST /test1/hello
{
"msg": "Happy birthday",
"names": ["Alex", "Mark"],
"when": "2014-11-01T10:09:08"
}
Alternative:
PUT /test1/hello/id1
{
"msg": "Happy birthday",
"names": ["Alex", "Mark"],
"when": "2014-11-01T10:09:08"
}
An index, type and definitions are created automatically
So, where is our document:
GET /test1/hello/_search
{
"took": 1,
"timed_out": false,
"_shards": {
"total": 5,
"successful": 5,
"failed": 0
},
"hits": {
"total": 1,
"max_score": 1,
"hits": [
{
"_index": "test1",
"_type": "hello",
"_id": "AUmIk4LDF4XvfpxnVJ2g",
"_score": 1,
"_source": {
"msg": "Happy birthday",
"names": [
"Alex",
"Mark"
],
"when": "2014-11-01T10:09:08"
}}
]
}}](https://image.slidesharecdn.com/lw14revolution-rafalovitch-presentation-notes-141115170557-conversion-gate02/85/Solr-vs-Elasticsearch-Case-by-Case-7-320.jpg)
![Behind the scenes
GET /test1/hello/_search
…..
{
"_index": "test1",
"_type": "hello",
"_id": "AUmIk4LDF4XvfpxnVJ2g",
"_score": 1,
"_source": {
"msg": "Happy birthday",
"names": [
"Alex",
"Mark"
],
"when": "2014-11-01T10:09:08"
}
….
GET /test1/hello/_mapping
{
"test1": {
"mappings": {
"hello": {
"properties": {
"msg": {
"type": "string"
},
"names": {
"type": "string"
},
"when": {
"type": "date",
"format": "dateOptionalTime"
}}}}}}](https://image.slidesharecdn.com/lw14revolution-rafalovitch-presentation-notes-141115170557-conversion-gate02/85/Solr-vs-Elasticsearch-Case-by-Case-8-320.jpg)
![Basic search in Elasticsearch
GET /test1/hello/_search
…..
{
"_index": "test1",
"_type": "hello",
"_id": "AUmIk4LDF4XvfpxnVJ2g",
"_score": 1,
"_source": {
"msg": "Happy birthday",
"names": [
"Alex",
"Mark"
],
"when": "2014-11-01T10:09:08"
}
….
• GET /test1/hello/_search?q=foobar – no results
• GET /test1/hello/_search?q=Alex – YES on names?
• GET /test1/hello/_search?q=alex – YES lower case
• GET /test1/hello/_search?q=happy – YES on msg?
• GET /test1/hello/_search?q=2014 – YES???
• GET /test1/hello/_search?q="birthday alex" – YES
• GET /test1/hello/_search?q="birthday mark" – NO
Issues:
1. Where are we actually searching?
2. Why are lower-case searches work?
3. What's so special about Alex?](https://image.slidesharecdn.com/lw14revolution-rafalovitch-presentation-notes-141115170557-conversion-gate02/85/Solr-vs-Elasticsearch-Case-by-Case-9-320.jpg)

![Can Solr do the same kind of magic?
• curl 'http://localhost:8983/solr/collection1/update/json/docs' -H 'Content-type:
application/json' -d @msg.json
curl 'http://localhost:8983/solr/collection1/select'
{
"responseHeader":{
"status":0,
"QTime":18,
"params":{}},
"response":{"numFound":1,"start":0,"docs":[
{
"msg":["Happy birthday"],
"names":["Alex", "Mark"],
"when":["2014-11-01T10:09:08Z"],
"_id":"e9af682d-e775-42f2-90a5-c932b5fbb691",
"_version_":1484096406012559360}]
}}
curl 'http://localhost:8983/solr/collection1/schema/fields'
{
"responseHeader":{
"status":0,
"QTime":1},
"fields":[
{"name":"_all", "type":"es_string",
"multiValued":true,
"indexed":true, "stored":false},
{"name":"_id", "type":"string",
"multiValued":false,
"indexed":true, "required":true,
"stored":true, "uniqueKey":true},
{"name":"_version_", "type":"long",
"indexed":true, "stored":true},
{"name":"msg", "type":"es_string"},
{"name":"names", "type":"es_string"},
{"name":"w • Output slightly re-formated hen", "type":"tdates"}]}](https://image.slidesharecdn.com/lw14revolution-rafalovitch-presentation-notes-141115170557-conversion-gate02/85/Solr-vs-Elasticsearch-Case-by-Case-11-320.jpg)

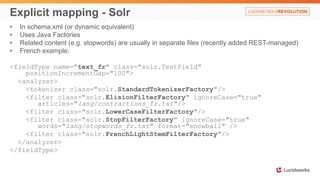
![Explicit mapping - Elasticsearch
• Created through PUT command
• Also can be stored in config/default-mapping.json or
config/mappings/[index_name]
• Mappings for all types in one index should be compatible to avoid problems
• Usually uses predefined mapping names. Has many names, including for
languages
• Explicit mapping is through named cross-references, rather than duplicated in-place
stack (like Solr)
• Related content is usually also in the definition. Sometimes in file (e.g.
stopwords_path – needs to be on all nodes)
• French example (next slide):](https://image.slidesharecdn.com/lw14revolution-rafalovitch-presentation-notes-141115170557-conversion-gate02/85/Solr-vs-Elasticsearch-Case-by-Case-14-320.jpg)
![Explicit mapping – Elasticsearch - French
{
"settings": {
"analysis": {
"filter": {
"french_elision": {
"type": "elision",
"articles": [ "l", "m", "t", "qu",
"n", "s", "j", "d", "c", "jusqu", "quoiqu",
"lorsqu", "puisqu"
]
},
"french_stop": {
"type": "stop",
"stopwords": "_french_"
},
"french_keywords": {
"type": "keyword_marker",
"keywords": []
},
"french_stemmer": {
"type": "stemmer",
"language": "light_french"
}
},
….
"analyzer": {
"french": {
"tokenizer": "standard",
"filter": [
"french_elision",
"lowercase",
"french_stop",
"french_keywords",
"french_stemmer"
]
}
}
}
}
}](https://image.slidesharecdn.com/lw14revolution-rafalovitch-presentation-notes-141115170557-conversion-gate02/85/Solr-vs-Elasticsearch-Case-by-Case-15-320.jpg)

![Index many documents – Elasticsearch
POST /test3/entries/_bulk
{ "index": {"_id": "1" } }
{"msg": "Hello", "names": ["Jack", "Jill"]}
{ "index": {"_id": "2" } }
{"msg": "Goodbye", "names": "Jason"}
{ "delete" : {"_id" : "3" } }
NOTE: Rivers (similar to DIH) MAY be deprecated.
Use Logstash instead (180Mb on disk, including 2 jRuby runtimes !!!)](https://image.slidesharecdn.com/lw14revolution-rafalovitch-presentation-notes-141115170557-conversion-gate02/85/Solr-vs-Elasticsearch-Case-by-Case-17-320.jpg)
![Index many documents - Solr
JSON - simple
[
{
"_id": "1",
"msg": "Hello",
"names": ["Jack", "Jill"]
},
{
"_id": "2",
"msg": "Goodbye",
"names": "Jason"
}
]
JSON – with commands
{
"add": { "doc": {
"_id": "1",
"msg": "Hello",
"names": ["Jack", "Jill"]
} },
"add": { "doc": {
"_id": "2",
"msg": "Goodbye",
"names": "Jason"
} },
"delete": { "_id":3 }
}
Also:
• CSV
• XML
• XML+XSLT
• JSON+transform (4.10)
• DataImportHandler
• Map-Reduce
External tools
• Logstash (owned by ES)](https://image.slidesharecdn.com/lw14revolution-rafalovitch-presentation-notes-141115170557-conversion-gate02/85/Solr-vs-Elasticsearch-Case-by-Case-18-320.jpg)

![Search compared – Simple searches
{
"msg": "Happy birthday",
"names": ["Alex", "Mark"],
"when": "2014-11-01T10:09:08"
}
{
"msg": "Happy New Year",
"names": ["Jack", "Jill"],
"when": "2015-01-01T00:00:01"
}
{
"msg": "Goodbye",
"names": ["Jack", "Jason"],
"when": "2015-06-01T00:00:00"
}
Elasticsearch (Marvel Sense GET):
• /test1/hello/_search – all
• /test1/hello/_search?q=happy birthday Alex– 2
• /test1/hello/_search?q=names:Alex – 1
Solr (GET http://localhost:8983/solr/…):
• /collection1/select – all
• /collection1/select?q=happy birthday Alex – 2
• /test1/hello/_search?q=names:Alex – 1](https://image.slidesharecdn.com/lw14revolution-rafalovitch-presentation-notes-141115170557-conversion-gate02/85/Solr-vs-Elasticsearch-Case-by-Case-20-320.jpg)
![Search Compared – Query DSL
Elasticsearch
GET /test1/hello/_search
{
"query": {
"query_string": {
"fields": ["msg^5", "names"],
"query": "happy birthday Alex",
"minimum_should_match": "100%"
}
}
}
Solr
…/collection1/select
?q=happy birthday Alex
&defType=dismax
&qf=msg^5 names
&mm=100%](https://image.slidesharecdn.com/lw14revolution-rafalovitch-presentation-notes-141115170557-conversion-gate02/85/Solr-vs-Elasticsearch-Case-by-Case-21-320.jpg)
![Search Compared – Query DSL - combo
Search future entries about Jack. Return only the best one.
Elasticsearch
GET /test1/hello/_search
{
"size" : 1,
"query": {
"filtered": {
"query": {
"query_string": {
"query": "jack"
}},
"filter": {
"range": {
"when": {
"gte": "now"
}}}}}}
Solr
…/collection1/select
?q=jack
&fq=when:[NOW TO *]
&rows=1](https://image.slidesharecdn.com/lw14revolution-rafalovitch-presentation-notes-141115170557-conversion-gate02/85/Solr-vs-Elasticsearch-Case-by-Case-22-320.jpg)
![Parent/Child structures
Inner objects
• Mapping: Object
• Dynamic mapping (default)
• NOT separate Lucene docs
• Map to flattened
multivalued fields
• Search matches against
value from ANY of inner
objects
{
"followers.age": [19, 26],
"followers.name":
[alex, lisa]
}
Elasticsearch
Nested objects
• Mapping: nested
• Explicit mapping
• Lucene block storage
• Inner documents are hidden
• Cannot return inner docs only
• Can do nested & inner
Parent and Child
• Mapping: _parent
• Explicit references
• Separate documents
• In-memory join
• SLOW
Solr
Nested objects
• Lucene block storage
• All documents are visible
• Child JSON is less natural](https://image.slidesharecdn.com/lw14revolution-rafalovitch-presentation-notes-141115170557-conversion-gate02/85/Solr-vs-Elasticsearch-Case-by-Case-23-320.jpg)






The document compares Solr and Elasticsearch, highlighting their similarities and differences, including aspects like full-text search capabilities, configuration methods, and plugin usage. It discusses specific technical details about their setups, indexing processes, and search functionalities, illustrating the strengths and weaknesses of both systems. Additionally, it covers topics such as nested documents, cloud deployment strategies, and explicit versus dynamic mapping in each tool.










































































