Downloaded 31 times










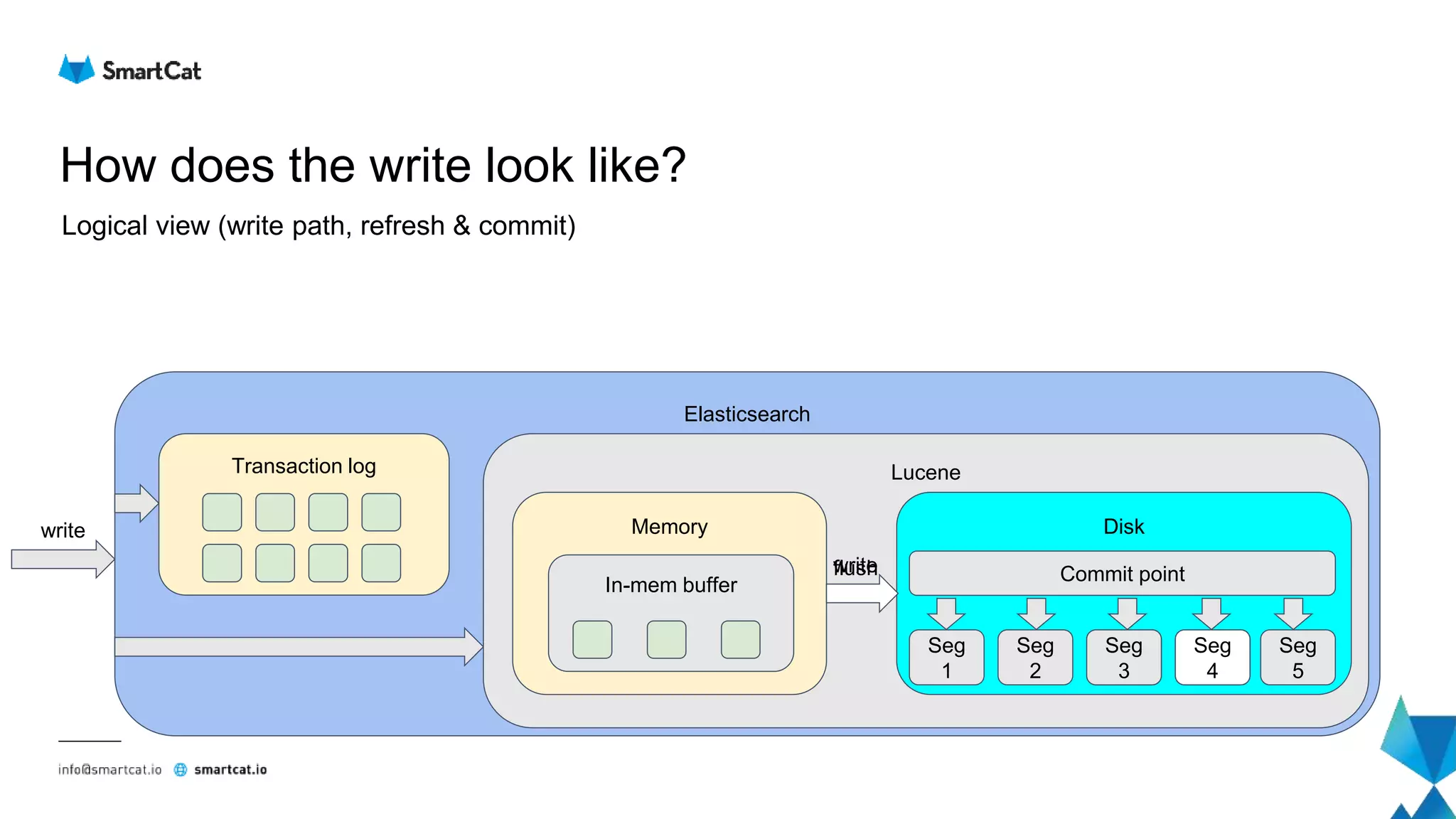
![How is write processed?
● Standard tokenizer
● Keyword tokenizer
● Letter tokenizer
● Lowercase tokenizer
● N gram tokenizer
● Edge n gram tokenizer
● Regular expression pattern tokenizer
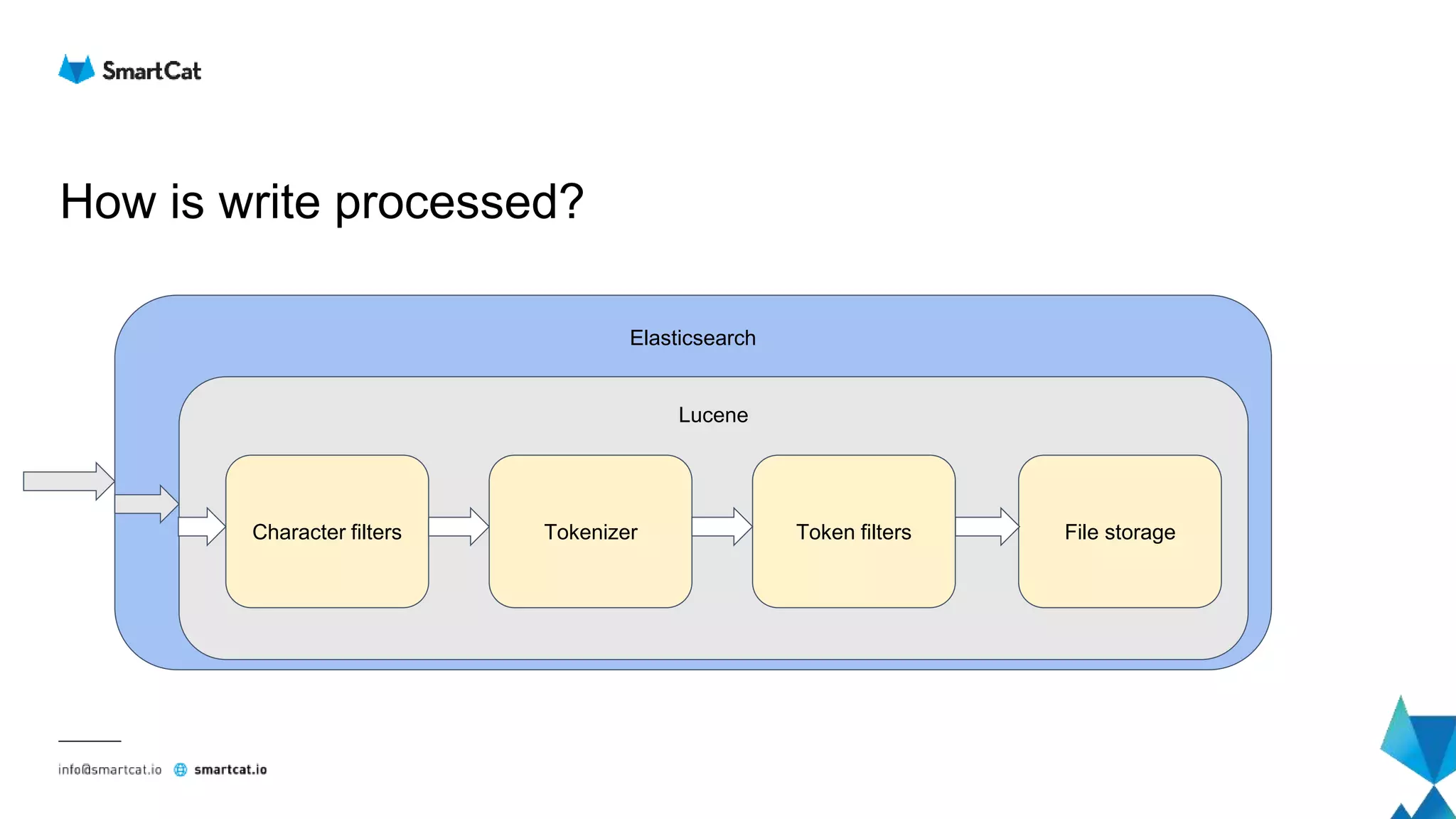
Tokenizer
Creates an instance of ObjectGenerator
based on provided configuration.
Resulting ObjectGenerator will try to
convert configured output to specified
objectType.
[Creates, an, instance, of, ObjectGenerator,
based, on, provided, configuration,
Resulting, ObjectGenerator, will, try, to,
convert, configured, output, to, specified,
objectType]](https://image.slidesharecdn.com/elasticsearch-underthehood-180910075357/75/Elasticsearch-under-the-hood-34-2048.jpg)
![How is write processed?
● Lower case filter
● English possessive filter
● Stop filter
● Synonym filter
● Reversed wildcard filter
● English minimal stem filter
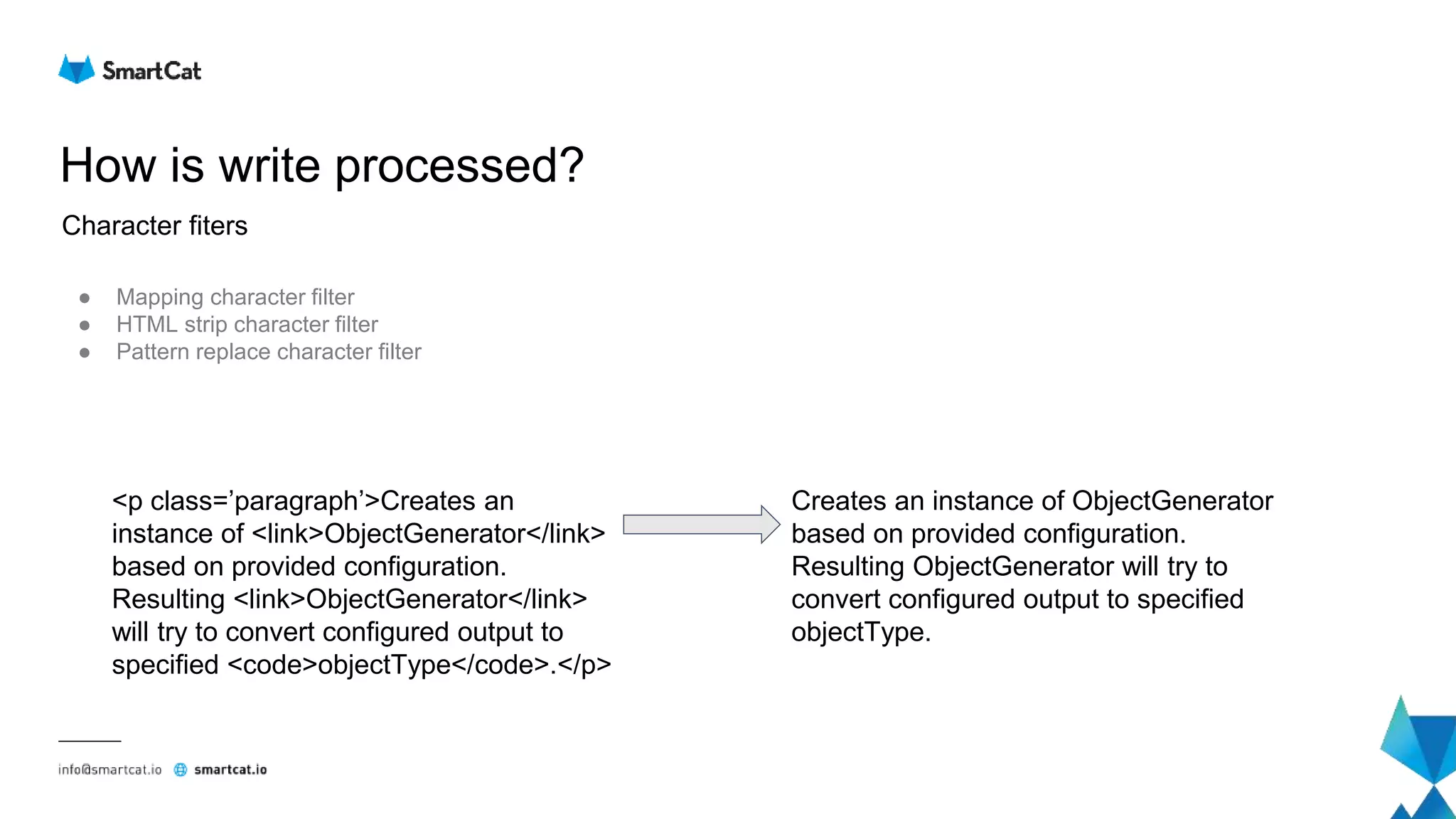
Token filters
[Creates, an, instance, of, ObjectGenerator,
based, on, provided, configuration,
Resulting, ObjectGenerator, will, try, to,
convert, configured, output, to, specified,
objectType]
[creates, instance, ObjectGenerator,
based, provided, configuration, resulting,
try, convert, configured, output,
specified, objectType]](https://image.slidesharecdn.com/elasticsearch-underthehood-180910075357/75/Elasticsearch-under-the-hood-35-2048.jpg)


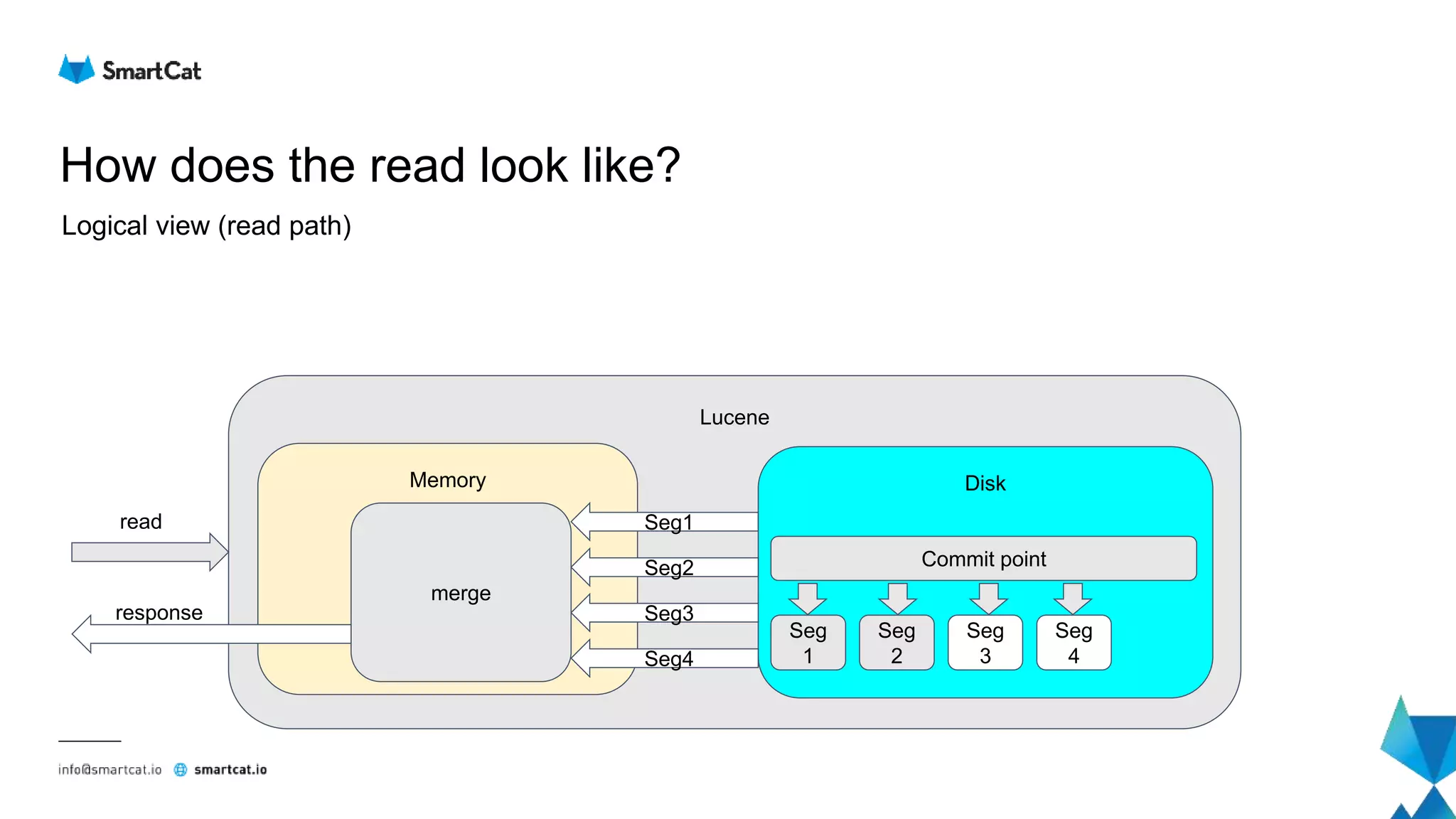
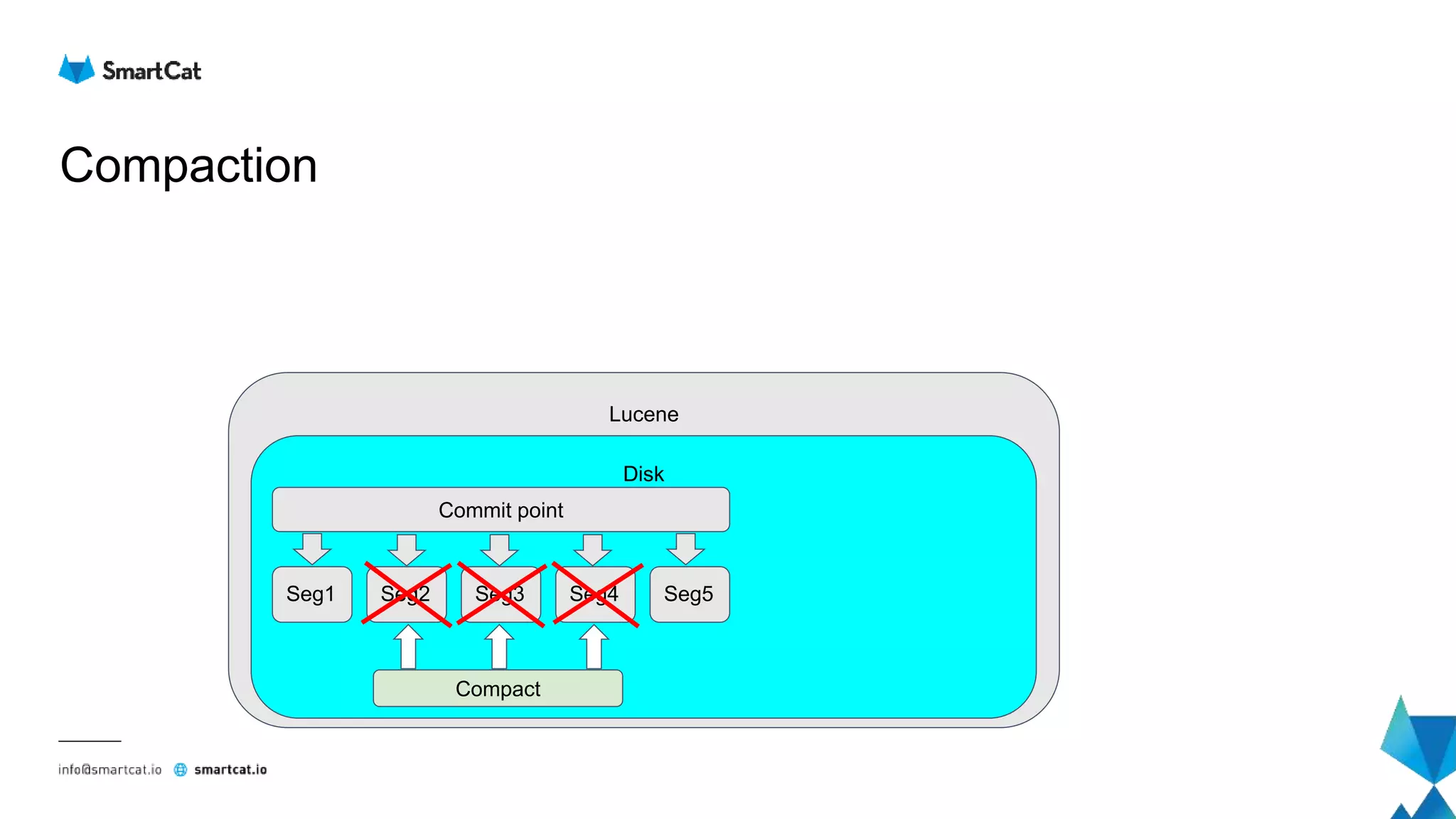




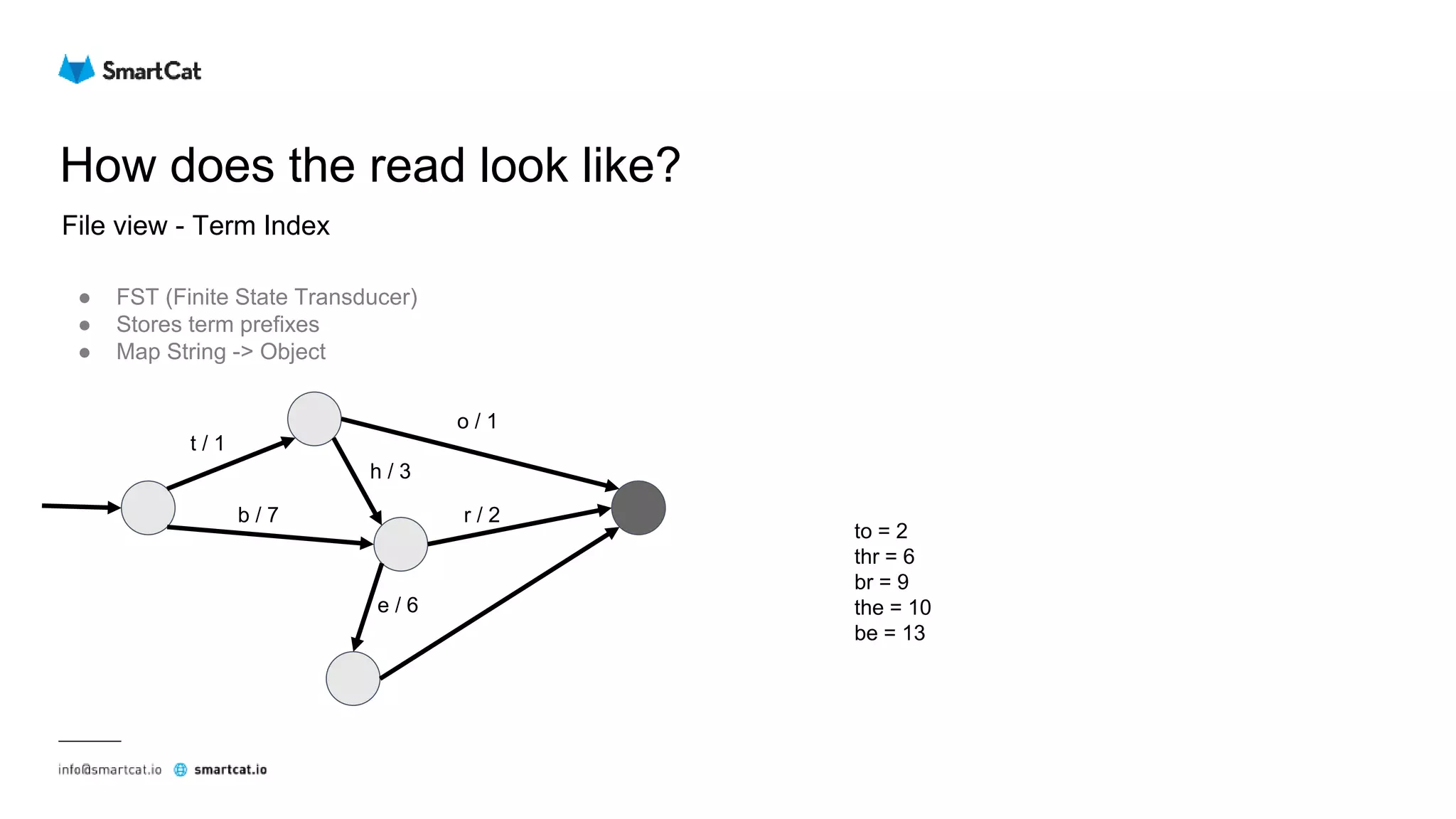
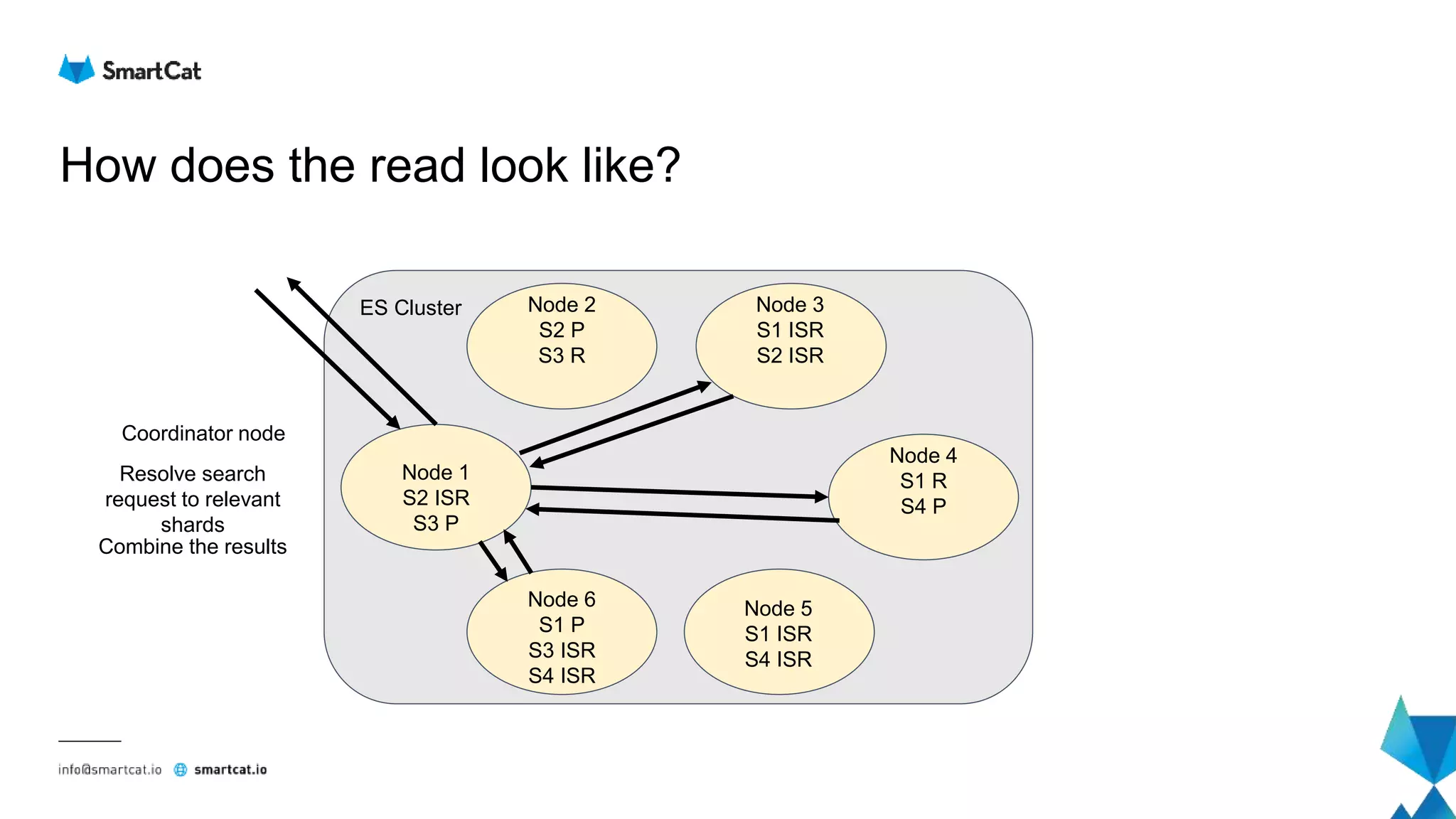
![How does the read look like?
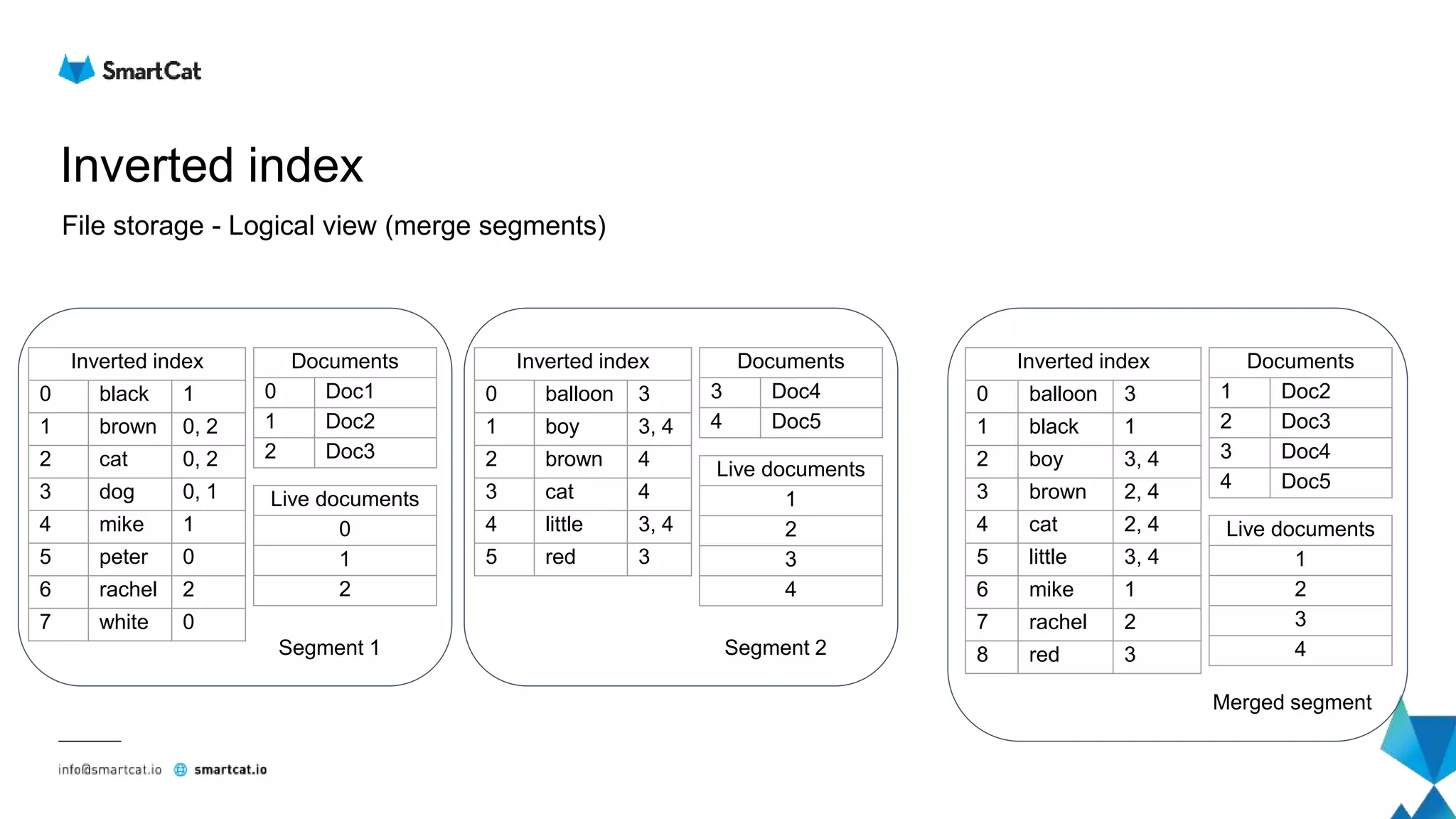
File view - Term Dictionary
● Jump to the given block (offset)
● Number of items within the block (25 - 48)
... ... ...
[Prefix = to]
Suffix Frequency Offset
ad 1 102
ast 1 135
aster 2 167
day 7 211
e 2 233
ilette 3 251
mato 8 287
nic 5 309
oth 3 355
Jump here
Not found
Not found
Not found
Not found
Not found
Not found
Found](https://image.slidesharecdn.com/elasticsearch-underthehood-180910075357/75/Elasticsearch-under-the-hood-48-2048.jpg)
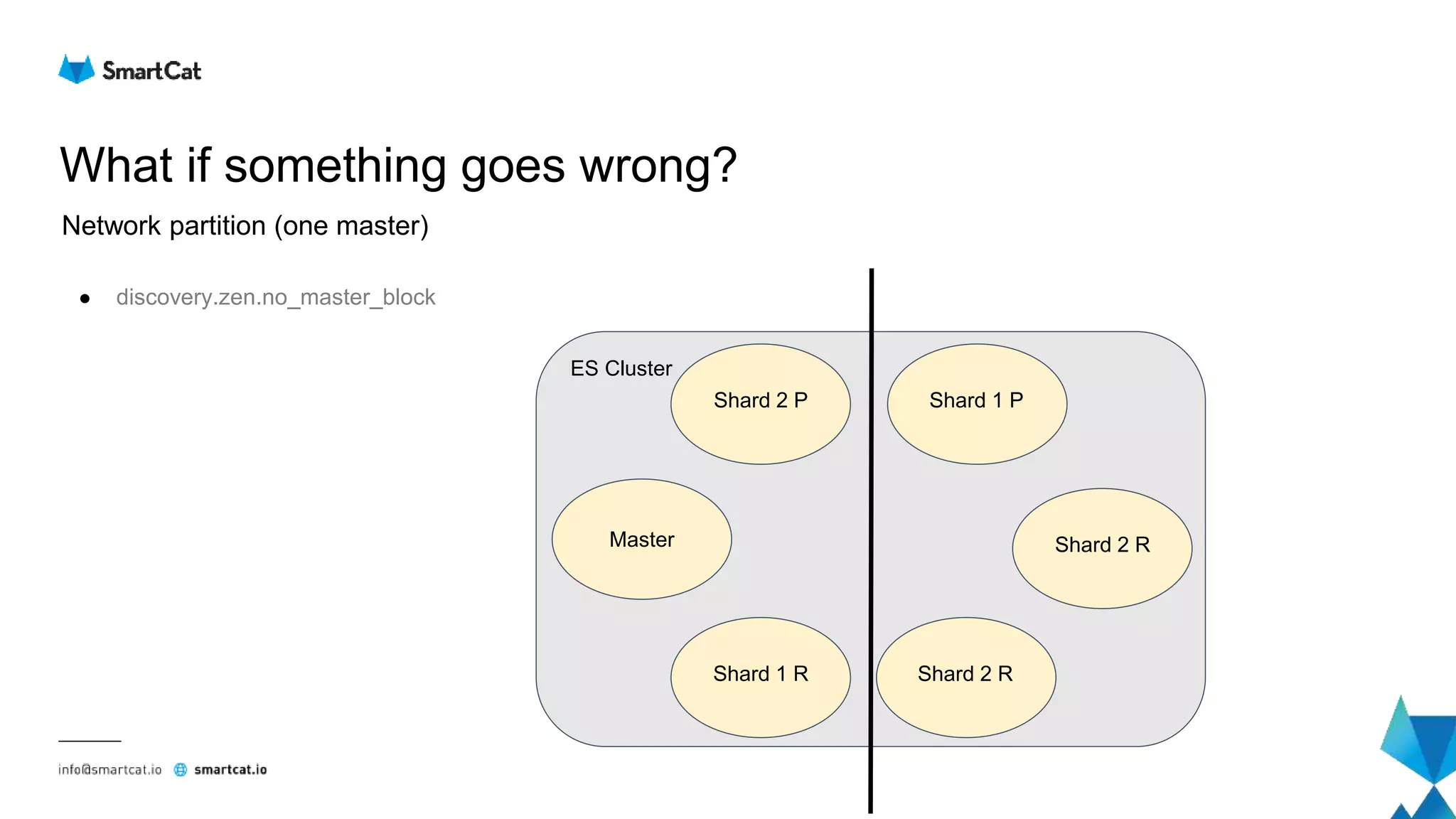
![How does the read look like?
File view - Postings lists
● Jump to the given offset in the postings list
● Encoded using modified FOR (Frame of Reference) delta
○ delta-encode
○ split into blocks of N = 128 values
○ bit packing per block
○ if remaining, encode with vInt
Example with N = 4
Offset Document ids
... ...
287 1, 3, 4, 6, 8, 20, 22, 26, 30, 31
... ...
Delta encode: 1, 2, 1, 2, 2, 12, 2, 4, 4, 1
Split to blocks: [1, 2, 1, 2] [2, 12, 2, 4] 4, 1
2 bits per value
total: 1 byte
4 bits per value
total: 2 bytes
vInt encoded
1 byte per value
total: 2 bytes
Uncompressed: 40 (10 * 4) bytes
Compressed: 5 (1 + 2 + 2) bytes](https://image.slidesharecdn.com/elasticsearch-underthehood-180910075357/75/Elasticsearch-under-the-hood-49-2048.jpg)
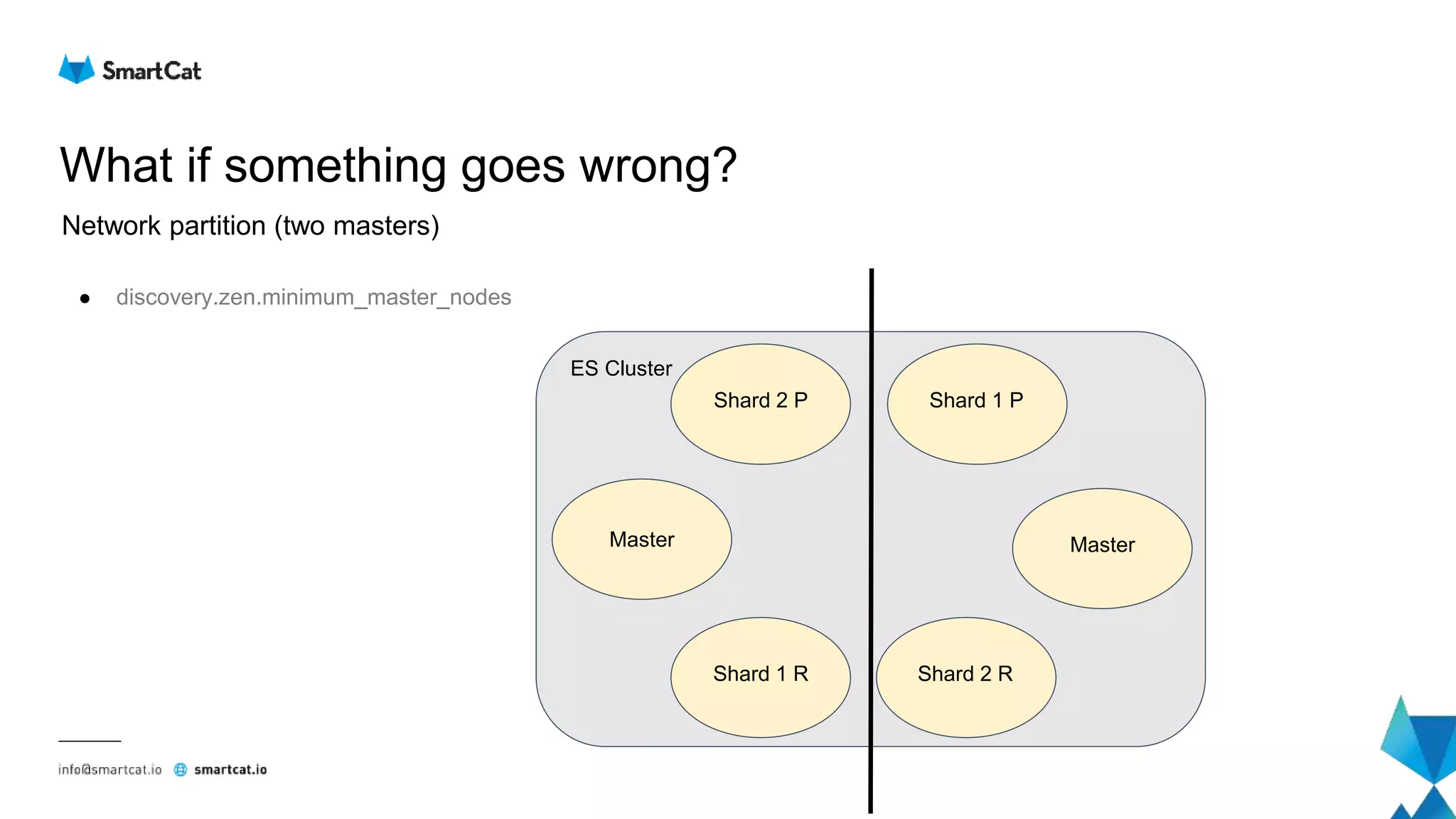
![How does the read look like?
File view - Field Index & Field Data
● Stored sequentially
● Compressed using LZ4 in 16+KB blocks
Starting Doc id Offset
0 33
4 188
5 312
7 423
12 605
13 811
20 934
25 1084
Field Index
Field Data
[Offset = 33]
Doc 0
Doc 1
Doc 2
Doc 3
[Offset = 188]
Doc 4
[Offset = 312]
Doc 5
Doc 6
[Offset = 423]
Doc 7
...
16KB
16KB
16KB
16KB](https://image.slidesharecdn.com/elasticsearch-underthehood-180910075357/75/Elasticsearch-under-the-hood-50-2048.jpg)



The document provides an in-depth overview of Elasticsearch and its underlying technology, Lucene, focusing on features like full-text search, scalability, and document management through various APIs. It covers cluster architecture, scaling operations, read and write processes, and how Elasticsearch handles failures and performance optimization at both cluster and Lucene level. Additionally, it delves into how data is processed and stored using indexes, including details on character filters, tokenizers, and field data management.










































































