Download as PDF, PPTX












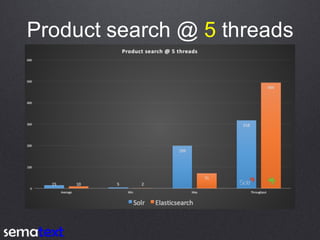

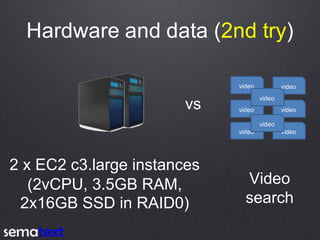
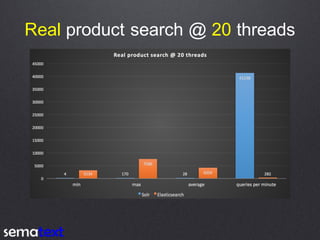







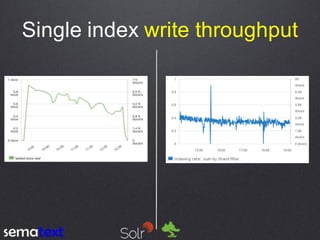
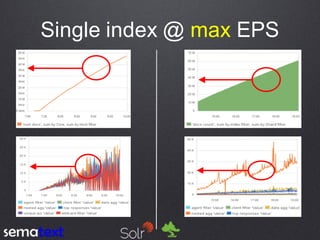
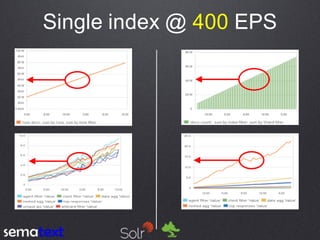


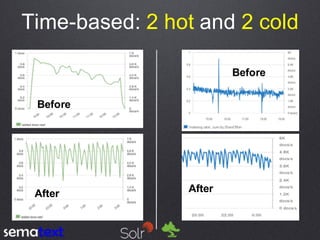
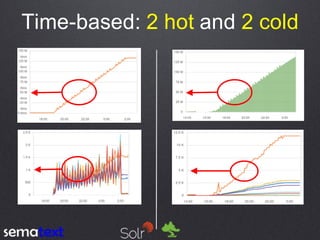
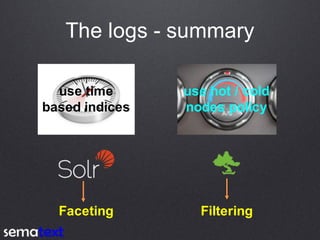




This document compares the performance and scalability of Elasticsearch and Solr for two use cases: product search and log analytics. For product search, both products performed well at high query volumes, but Elasticsearch handled the larger video dataset faster. For logs, Elasticsearch performed better by using time-based indices across hot and cold nodes to isolate newer and older data. In general, configuration was found to impact performance more than differences between the products. Proper testing with one's own data is recommended before making conclusions.



































































