The document summarizes the Rubin causal model and key assumptions and methods for causal inference using observational data, including linear regression models.
It introduces the Rubin model for causal effects, noting the need for a good counterfactual to estimate causal parameters. It then covers simple linear regression models (SLRM) and assumptions needed for causal interpretation, including the zero conditional mean assumption.
Finally, it discusses multivariate linear regression models (MLRM), outlining additional assumptions required like no multicollinearity between covariates and the independence of errors from covariates. It also introduces ordinary least squares estimation and the Frisch-Waugh theorem for interpreting slope estimates from MLRM.


![Recap :
.
Rubin Model :
6 =
0 + { E [ Yio 1 Ti =
1 ] -
E [ Yiolti =
0 ] }
T PaFamete#
estimator
selection effect
Assume E [ Yio IT ,
= 1 ] =
E [ Y ; o I Ti =
0 ]
↳ need good counterfactual
§ = E [ Yi 11 Ti =
1 ] -
E [ Yio 1 Ti =
0 ] if selection term = 0
Estimating a parameter ( o )
§ =
I-
I
estimator is rule](https://image.slidesharecdn.com/econometrics-190820213737/85/Econometrics-Notes-2-320.jpg)
![Simple Linear Regression Model ( SLRM )
y ;
= Bo + 131 Xi + Ui
Bo E B 1 are parameters
U is the error term
↳
captures influence of third
party factors
$ x ; = 1 or 0
E [ Yi I X ; ] =
E [ Bo +
131 Xi +
U ; I Xi ]
=
E [ 1301 × ;] + [ [ 131 X ; l X ;] +
E [ U ; l × i ]
=
Bo +
Be [ X ; l X ; ] +
E [ Uil Xi ]
E [ Y ; 1 X ; = 1
] =
Bo + 131 + E [ U ; 1 x i
= 1 ]
-
E [ Yi 1 X ; =
0 ] =
Bo +
E [ Ui 1
X i =
0 ]
B 1 + E [ U i 1 × i =
1 ] -
E [ U ;
1
× i
=
0 ] = 131 + 0
On
average ,
unobservable s are the same
SO ATE =
131 if E [ U ; I Xi =
I ] =
E [ U i l x i
=
0 ]
Key Assumption :
Zero Conditional Mean
E [ U I X ] = 0
I . E [ UIX ] is constant *
2 .
E [ U ] = 0
implies Cov ( U , X ) =
0 ( no linear relationship )
↳ × 's are
randomly assigned
Ordinary Least Squares ( OLS )
Let { ( Xi ,
y i ) :
i =
1 , . . .
,
n } denote a random sample of size n from the
Population
Define sample estimate of the unknown population line as
yn ;
= Bo +
Be Xi
ii =
Yi
-
di and choose Bo and Be to minimize the
average squared
residual
Bone,
th En
,
( yi
-
( Bo +
BI × i ))
2](https://image.slidesharecdn.com/econometrics-190820213737/85/Econometrics-Notes-3-320.jpg)



![Black vs .
White name resumes experiment
Model :
.
1 .
Callback ; = Bo + 13 .
black name ;
+
U ; ( DGP )
t
1
dummy variable ( 0 or 1 )
E [ it callback 1
black name = 1 ] =
Bo + 13 , [ black name
1
black name = 1 ] +
E [ Ul black name =L ]
=
Bo + 13 ,
+
Et Ul black name = 1 ]
t
z
Unobservable Conditional on black.name = I
E [
'
1. Callback I black name =
0 ] =
Bo +
B , E [ black name lblackname =
0 ] +
E[ Ul black name = 0 ]
=
130 + E [ U I black name = 0 ]
1 -
2 =
13 ,
+
E [ Ulblk = I ] -
E [ Ulbl 1<=0 ]
randomized experiment → left with 13 ,
13 ,
=
gap between difference in it Call back
Bo = % call back for white names
Bo + B ,
=
.
1 .
Call back for black names
Are LS estimators any good ?
.
SLR .
1 Pop . Relationship is Yi = Bo + B , Xi +
Ui
.
SLR . 2 Random Sample of × and Y from pop .
is LR . 3 There is variation in ×
-
Language :
"
our estimate of B is identified off the Variation in ×
-
denominator of B, cannot be 0
.
As SLR .
4 E [ UIX =
0 ] →
ETU ] =
0 and Cov ( U ,
X ) = 0
-
variation in × provides unbiased proxy for Counterfactual
-
produces an unbiased estimate of the causal effect E [ B, ] =
13 ,
↳
§ E [ × ;] =
M
Estimate of pop . mean =
In
E [ In ] .
-
E [ th El,
X ;] =
th E EE,
× ;] = th ¥,
E [ xi ] =
the ,
M =
M
Showed sample mean for pop .
mean is unbiased
-
will not need to replicate
Y ; =
Bo +
B , Xi +
Ui
I =
Bo +
B , I + I
Y ;
-
I = B , ( × ;
-
I ) + ( Ui -
I ) biased up or down ?
ph =
ht Et ( B ,
( Xi # ) +
( ni -5 ) ) ( × ;
-
I ) q
→ see textbook is Cov + or
-
?
's §,
( x ;
-
I ) ( x i
-
I )
T
E [ B, ] =
B ,
+
coal
bids term
→
If ZCM holds
var ( × )
then E [ B, ] =
13 ,](https://image.slidesharecdn.com/econometrics-190820213737/85/Econometrics-Notes-7-320.jpg)
![.
SLR .
S Var ( U 1 X ) =
Constant = 02
-
homos kedasti City
Prediction
.
sometimes care about ability of × to predict y
.
r ( correlation ) and its
square ,
R 2
r =
COV ( × , y ) / [ S × Sy ]
Unit free
.
s -
standard error of regression ( MSE =
sz )](https://image.slidesharecdn.com/econometrics-190820213737/85/Econometrics-Notes-8-320.jpg)
![Motivations for Multivariate Model
-
interested in effects of more than one variable on an outcome
.
refine predictions
.
If SLR .
4 is violated -
reducing committed variables bias
.
allow for some kinds of non -
linear relationships
SLRM : Yi =
Bo + B , Xi +
Ui
MLRM : Yi = Bo + B , X I ;
+
Bz Xzi +
133×3 it . . .
+
BK Xki +
Ui
k :
# of explanatory variables ( covariates , independent vars )
Yi :
dependent variable ( Outcome )
Ui :
error term ( unobserved determinants of Y )
-
linear in parameters ( B 's )
-
model Can capture non -
linear relationships with X 's
.
MLR . 2 :
simple random sample
.
MLR .
3 :
no X 's are constant ,
and no perfect linear relationship blw X 's
-
no perfect multi -
Col linearity
-
¥ =
13 , ( all else constant )
.
MLR .
4 : E ( Uil Xii ,
. . .
,
Xki ) =
0
-
independence assumption ( critical for causal inference )
-
variation of zero conditional mean assumption
-
implies COV ( Xii ,
Ui ) =
Cov ( Xz ; ,
U ) =
. . .
=
COV ( Xki ,
Ui ) = 0 E E [ U ] =
0
-
as if X 's were randomly assigned
-
If it holds ,
we
say variation in X , . . .
Xk is
good
-
provides an unbiased proxy for counterfactual
Ordinary Least Squares ( OLS )
Estimation of the MLRM
min
Bo
,
B, ,
...
Bk
T i§,
Yi
-
( Bio + B.Xii + . . .
+
Be × ,<
;)
see slides
Force Cov ( a ; ,
Xii ) = 0](https://image.slidesharecdn.com/econometrics-190820213737/85/Econometrics-Notes-9-320.jpg)


![MLRM : Y ;
=
Bo +
B , Xi ;
+
132 Xzi + . . .
+
BKXK ; + U ;
.
Frisch -
Waugh Theorem : The OLS estimator for B, can be written as :
B,
=
COV ( Fii , Yi )
var ( F , ;)
F , ; ? from X , ;
=
do +
£2Xzi
+
£3Xz
;
+ . . .
Fii =
Xii -
Iii
Stata
Open FWL do fill in do fill editor
Open LFS data set in STATA
Desc :
describe
gen age 2 =
ager 2
sum . . .
histogram ...
reg . . .
.
0948038
predict that ,
resid
predict Xb
R squared :O . 1436 → 14.36% of variation in In wage can be explained
by included X 's
Too Many or Too Few Variables
.
include Variables that don't belong
-
no effect on our parameter estimate , OLS remains unbiased
-
lose statistical precision
.
exclude variable that doesn't belong
-
OLS is biased
-
"
omitted variables
"
bias
-
E [ BY ] = B ,
+ Bz
COV ( × ' . xz )
*
V ( X ,
)
¥
can reason about sign of Bz { covariance to estimate error](https://image.slidesharecdn.com/econometrics-190820213737/85/Econometrics-Notes-12-320.jpg)

![On website , suggested
problems E prior midterm
Population Mean Sample Mean
if M is mean In = Tn Fei Xi
of random Variable Xi
Then Et I ] =
M
Yi =
Bo t
B , X , i
t
Bz X z i
t
. . .
t
Ui
In
Bi =
n IE ly i
-
5) ( x i
-
I )
SL RM
th I ,
( x
;
-
I 5
Sample Variance : V Tarts.
)
=
se ( Bj )
Additional Assumptions about error Variation
MLRM Assm # S :
Var( U I X ) = OZ
Homos ked asti city t
no autocorrelation
Cases where assm fails :
.
time series data
.
samples w/
"
Clusters
"
Li .
e.
survey several members of the same family )
Var ( Bj ) =
02
( N -
t ) Var (
Xj
) ( I -
Rj
2
)
Where Rj
2
is the R2 from regressing Xj on all other x 's L first part Of Frisch -
Wa USS
02 is variance ;larger
02 →
larger variance in Bj
N -
I :
need
large N to reduce variance of Bj
Var ( Xj ) :
want variance of Xj to be larger
↳
not all variance in Xj contributes to the variance in Bj because some variation
in Xj may be correlated with other X 's
( I -
Rj
'
) :
what share of variation in Xj is independent correlation
↳ would like low correlation between X 's
Large variance means less precise estimator ,
larger confidence intervals ,
E. less accurate inference](https://image.slidesharecdn.com/econometrics-190820213737/85/Econometrics-Notes-14-320.jpg)







![Asymptotic
Unbiased ? Et B ] =
B
Smallest variance : B is BLUE
U n
N → B ~
N ( B ,
V ( B ) )
-
testing
-
Asymptotic :
Can we still
get good estimators with weaker assms ?
Takeaways
Small Sample Large Sample *
LS estimators are . . .
I
.
Consistency
.
an
'
.
estimator
"
is consistent if
pl im
n → as
B' →
B
If n
gets larger ,
going toward population
-
under Gauss -
Markov as Sms
, Slope estimates are consistent
-
B can be biased for small n and consistent in large samples
Suppose pie = I t th
E I A] =
M t th As n → as
,
ht
goes to O
.
For unbiased ness :
need E EU I X , , Xz ,
X .
T =
O assm to hold in small sample
.
For consistency ,
only need E EU 7=0 and COV ( u ,
X ) =
O](https://image.slidesharecdn.com/econometrics-190820213737/85/Econometrics-Notes-22-320.jpg)

![Readings : Ch 6 ,
7
↳ practice problems at end
Specification Choices
'
ML RM is
"
linear
"
in parameters
-
measuring x 4 y
in
logs
-
data scaling
-
polynomials
-
dummy variables
-
etc .
-
Polynomials for non -
linear ities
Ln L wage ) .
-
Bo t
B ,
yrs ed t
Bz potexpt 133 pote Xp
2
the
pot exp
=
age
-
edu -
6
01h
wage
2 pot exp
=
Bz t
2133 Pote Xp
I t
also captures main 2nd order
effect of aging effect effect
pot exp
.
-
21 →
mean marginal effect =
Bz t
2133 C 21 )
Reaches Max or min slope at potexp =
-
132/2133
↳
Find using Bz t
2133 pot exp
=
O
Stata : fun with dummies
*
main effect :
Holding all else constant E pot exp
= O →
Dummy Variables
-
2 Values only
{ O ,
I }
'
Mean of dummy variable :
X ,
=
I female I =
In II ,
Xi = share of 1 's
0 male
.
Dummy in regression
Yi
= Bo t
So do +
B , Xi t
Ui Where do = I or O
E I y
I
do =
I ] =
( Bo t
So ) t
B , X i
t
E EU I do =
I ]
E I y
I do = I ] =
Bo t
B , Xi t
Et U I do ] =
O
I
Et y
I
do =
I ] =
( Bo t
So ) t
B , X i
t
E EU I do =
I ]
E I y
I do = I ] =
Bo t
B , Xi t
EE U I do ] =
O
So Et y
I do =
I ] -
E t y
I do =
O ] =
So](https://image.slidesharecdn.com/econometrics-190820213737/85/Econometrics-Notes-24-320.jpg)
![I
.
dummy for intercept shifter
2. dummy for Ll 's over time
3 .
dummy for multiple categories
4 .
dummy variable interactions
.
time dummy
A t
'
-
I if year
=
2009
O if
year
=
2008
y t
.
-
I if
unemployed
O if not
DGP :
ye
=
Bo t
ft d t t
Ut
Et ye Idt = I ] =
Bo t
St t
EE Ut Id +
=
I ]
E Eye Idt =
O ] =
Bo t E t Ut I de
=
O ]
Under ZCM : E E Ut Id t
=
IT =
Et Ut Idt =
O ]
E
Eye I d t
=
I ] -
E I
y t
I d t
=
03 =
St
Diff in
unemployment over time
-
Multiple Category Dummy
-
cannot include all
categories ,
must omit base
category
-
constant is
avg y ,
conditional on all other variables being O
Yi =
Bo t
B ,
NE t Bz MW t
Bs Sth t
Ui
Et Yi
I NE =
0 ,
MW =
O ,
Sth =
03 =
Bo . . .
average y for base I omitted cat .
( west )
E Ty i I NE =
O ,
MW = I
,
Sth =
O ] =
Bo t
Bz =
average y for MW = I
( B -
A ) =
B 2
E E
y
I Sth = I
,
MW = O ,
NE =
OT =
Bot Bs
( Sth -
MW ) =
133 -
Bz
Yi =
Bo t
B ,
NE t Bz MW t
Bs Sth t
By
yrs ed t
y i](https://image.slidesharecdn.com/econometrics-190820213737/85/Econometrics-Notes-25-320.jpg)
![Dummies Continued
.
preview
-
include M -
I
categories of dummies
-
fixed effects are another name for dummies
-
interpretation
:
coefficient of
dummy variable is effect in relation to omitted category
-
changing slopes
Yi
=
Bo t
So do t
B , Xi t
U i
y i
=
Bo t
So do
+
B , X i
t
8 ,
do *
X i
t
Ui
E I y i I do =
I ] =
Bo t
So t
B , Xi t
8 ,
X i
=
( Bo t
8 o ) t
( B ,
t 8 ,
) X i
E t y i
I
do =
O ] =
Bo t
B , Xi
y
=
Bo t
Bi NE t Bz MW t 133 Sth t 134 yrs ed t
Bs N E *
yrs ed t
136MW *
yrs ed t 137 Sth *
yrs ed t
U
E [ y
I N E =
O , MW =
O ,
Sth =
OT =
Bo t
134
yrs ed
↳
main effect , slope for committed group
E t y
I NE = I
,
MW =
O ,
Sth =
O ] =
Bo t
Bi t 134
yrs ed t
Bs yrs ed
=
( Bo t Bi ) +434 t
Bs )
yrs ed
E I y
I NE ,
MW ,
Sth =
IT =
Bot 133 t ( B 4
t 137 ) yrs ed
-
EE Y
I NE ,
MW =
I
,
Sth =
I ] =
Bo t
Bz t
( 134 t Be ) yrs ed
( 133 -
Bz ) t
( By -
B 6) yrs ed
.
Diff in returns to edu in NE VS .
Sth
:
B s
-
B >
= -
. 0117
-
.
018
Chow Test
H o
:
B ,
=
132=133 =
Bs =
136 =
By =
O
R ? :
y i
=
Bo t
134 yrs ed t
U
H A
:
not Ho
can use f -
test or Chi squared test L use f -
test here )
( R Ir -
Rim ) 19
~ F
( I -
RE r ) KN -
k -
t )
Will probably fail to reject null in this case
In this sample ,
not significant difference in terms of return to education
.
Interactions of continuous variables
Ln L
wage ) =
Bo t B , yrs ed t
Bzpotexpt Bs pot exp
*
yrs ed t
U
Partial derivative interpretation
:
2 In
wage
2 yrs ed
=
B ,
t
Bs pot exp](https://image.slidesharecdn.com/econometrics-190820213737/85/Econometrics-Notes-26-320.jpg)
![Deviations
!
-
heteros ked asti
city ( HT SC )
V ( U I X ) ¥ 02
-
V ( U I X ) =
02 ( X )
.
Variance of u is different for different values of X
.
ex :
estimating returns to education
-
more variation at
higher levels of education than for high school dropouts
.
other examples
-
If Y data are sample means
I data
Var ( T ) =
' )
=
I
N
If N 's are different for each Sample → HTS C
-
If Y is a
dummy dependent value
.
consequences
-
OLS is still unbiased and consistent
-
standard errors are biased
-
can 't use t
-
statistics ,
f -
statistics ,
or LM -
statistics
-
regular OLS is not efficient
-
weighted least squares is efficient
Ex i
20 ? Exit ? * Don 't have to memorize
Var ( B,
)=fz×py2
→
I Exp ]
'
* use robust in STATA
'
Robust Standard Errors
-
biased in small samples ,
but consistent
-
will not have t .
dist
-
robust se
may
be smaller or
larger than regular se
*
Always use robust !
Might have heteros ked asti
city .
-
HOW do you know it you have heteros ked asti city ?
Ho :
E I U2 I X ] .
-
02 = V L u I X )
HA :
not Ho
I
.
Regress y i on Xi → Ii for all i
^
.
2
2 .
U ,
3 .
Reg is ? on Xi 's →
test ?
↳
test joint
-
significance of all Bs in step 3 using f -
test or LM -
test
Reject ? not homos ked -
Fail to reject ? homos ked .
is ok](https://image.slidesharecdn.com/econometrics-190820213737/85/Econometrics-Notes-27-320.jpg)

![-
classical measurement error :
E Elio ] =
O
And COV Lei o ,
Xi ) =
O
COV ( e ,
-
o , y ;
*
) =
O
-
Implications :
True Model :
y
* =
Bo t
B , X ,
t
Ui
y
* t
Cio =
Bot B , Xi t
L U i t e i o )
What I can
get
:
y i
= Bo t
Bi X ,
t
( Ui te ; o )](https://image.slidesharecdn.com/econometrics-190820213737/85/Econometrics-Notes-29-320.jpg)
![Classical Measurement Error in X
§ Xi =
Xi
*
t
e it
T T T
actual data truth error
C. M .
E .
AsSms ; e is Uncorrelated with Ui and Xi
*
We want :
y ;
=
Bo t
B , Xi
*
t
Ui
← well -
behaved error
we can
get
:
Yi
=
Bo t B ,
( Xi
-
eis ) t
Ui
=
Bo t
B , Xi
-
B ,
e i ,
t
Ui
=
Bo
t
B , Xi t
( Ui
-
Bie it
)
n n
U ;
*
COV ( Xi ,
Vi
*
) ± O
So what ?
Et Bus ] * B but we can derive in what
way it differs
pl im
Big =
COV ( Y ,
× )
=
COV ( Bot B , Xt Ui
*
.
X )
=
B ,
V L x )
+
Cov ( Ui
*
, Xi )
var CX ) Var CX ) V L X ) v ( x )
COV Lui
*
, Xi )
=
COV ( Ui
-
B , ei , Xi
*
t em ) =
CoV ( -
B , Ei ,
ei )
=
-
Bi V Lei ) CME
V ( Xi ) V ( Xi ) V C Xi ) V ( Xi ) ASSMS
Him L B,
) = B , ( o
,⇐?¥z ) Weighting the truth that the estimate is able to tell us
T
MUST be less than I
Always closer to 0 than it Should be
Adding more X 's →
reducing signal signal t
noise
↳
other Slope estimates are biased ,
but not in predictable ways
Can it be fixed ?
'
Using administrative data to find Oe
'
-
see slides](https://image.slidesharecdn.com/econometrics-190820213737/85/Econometrics-Notes-30-320.jpg)

![Panel Data and Methods
'
Differencein difference
-
use interaction of time dummy Variable with another
dummy variable
-
can sometimes help get at causal effects
-
Research question :
What's the impact of more immigrants on native unemployment
rates ?
-
issues w/ cross-sectional data ?
-
sorting of immigrants ( higher unemployment rates in cheap cities )
.
EX :
Mariel boat lift
-
natural developments
-
Apr
-
Oct 1980 :
100,000 Cubans poured into Miami ( 60,000 Stayed )
-
compare changes in unemployment rate 1979 -
1981 in Miami to
changes in
"
comparison
cities
"
Yi =L if
unemployed
O if not
D= unemployment rate
Gg
=
change in
unemployment rate
( y-m.tt ,
-
Tm , t
) -
( Dc ,
t ti
-
5 c
,
t
)
- -
treated Controlled
2 Dummy Variables
Di
Miami
=
{
I Miami
D;
1981
=
{
I after boat lift ( 1981 )
O
comp cities O before boat lift 4979 )
Yi =
Bo t
B ,
D ,
Miami t
y ;
B ,
:
difference between employment rate in Miami and different cities
Yi =
Bo t
B , Dimiamit Bz Dila
' '
t
133 Di
Miami .
Di
1981
t
U ;
Bz :
Change in employment rate from 1979 -
1981 in comparison cities
E [ Yi I Di M =
I ,
Di
' 98 '
= I ] =
Bot B ,
t Bz t Bs
-
Et Yi I Di
M = I
,
Di
'
981=0 ] =
Bot B ,
Bz t
133 If B ,
=
O , helpful
Diff in Whom ploy .
L no diff .
b/w whomp .
btw
btw 81 E 79 in M cities in 1979 )
Et Yi I
Di
M
=
O
,
Di
' 98 '
=
I ] =
Bo t
Bz
-
Et Yi I Di
M -
-
O
,
Di1981=0 ] =
Bo
Bz
Change in vnemptoy .
in
comp .
cities pre to post
( Bz t
Bs ) -
Bz =
133
how much larger was the change in when ploy .
rate in Miami than in comp . Cities](https://image.slidesharecdn.com/econometrics-190820213737/85/Econometrics-Notes-32-320.jpg)



![Review Session :
Sit =
a t
BE Dad deceased ;
*
Be toret
I t
8 I Dad deceased i
] to Before't
'
t
Uit
Treatment :
Dead dad
Control :
Not dead dad
↳
controlling for time effects
EIS it
I
Before = I
,
Dad Dec =D =
Xt Bt 8 t O E IS it
I
134=0 ,
D D= IT =
at 8
-
E I Sit I Before =
I
,
Dad Dec I =
a t
O -
E IS it
I 134=0 ,
D D= 03 =L
B t
8 8
Bt8-8=13
reduced form ,
intent to treat
O
-
-
time effect
include co variates to reduce OV B
↳ da reduce noise in data →
t -
stat
goes up
When correlated w/ interaction term →
se
goes up
robust standard errors L
general fix for any form of heteros ked asti city )
→
only changes se
Siblings
:
issue -
worried about demonstration effect ,
can 't be treated as individuals
↳ Cluster b/c autocorrelation L inference will be wrong )
oh
"
family only changes se
8 MC t
short answers
noise ,
sometimes over I underestimate
Classical measurement error in x :
biased coeff . X i
=
Xi
* t
e i
E Tei I =
O ,
Corr Lei ,
Xi
*
to
attenuation bias toward O
Yi =
Bo t
B. x ;
*
tui
non ass measurement error in X :
biased coeff could
go either way
pn
,
;mI
' Lu -
Beit
If Corr ( e i ,
X
i
*
) 70](https://image.slidesharecdn.com/econometrics-190820213737/85/Econometrics-Notes-36-320.jpg)
![Instrumental Variables Models
.
Assn MLR .
4 LE the IX ] ,
COV EX ,
43=0 )
.
IV methods can deal with OVB ,
Classical measurement error in X , simultaneity ,
etc .
DGP :
Yi
=
Bo t
B , Xi t Ui
Ey
ax
x -2×3 y
← a -Z
U
unrelated to U
.
OVB can be eliminated using instrumental variable z with 2 properties :
I
.
CoV C 2. U 7=0 instrument exogeneity
2. COV ( 2 , X ) # O instrument relevance ALWAYS CHECK
↳
can check WI data
-
2 is
ideally randomly assigned
-
IV
regression uses
"
experimental
"
variation in X
generated by z
.
OLS Est :
Bois =
E ( Yi
-
5) ( Xi
-
I )
or
COV ( y , x )
E ( x ;
-
I ) L Xi
-
I ) COV Lx , x )
'
IV Est :
Bn, ,
=
E L Yi
-
5) C Zi
-
I )
or
COV ( y ,
2 )
E ( Xi
-
I ) ( Zi
-
I ) COV CX ,
2)
.
In STATA :
"
irreg y ( x =
2 ) controls
"
LS :
MOM Etu ]=O ,
EEXU 7=0 =
Cov ( X ,
u )
IV :
MOM Etu ]=O ,
ETZU ] =
COV L 2. U )
.
Ex :
contaminated drug trials
Z :
whether assigned to treatment
group
X :
dosage
y
:
blood pressure
.
Difference in
avg .
drug dose is
experimentally driven even though . . .
B,
=
T treatment
-
Tantra
I treatment
-
I control
.
Yi
=
Bo t Bi Xi t Ui
Rewrite :
Ly i
-
J ) -
B , Lxi
-
F) t
Lui -
T )
Btw =
Elyi -
5) l Zi
-
E ) =
ECB , C Xi -
F) t
Cui -
ut ) ) ( Zi
-
E) = B .
E L Xi
-
I ) ( Zi
-
I ) +
E C Zi
-
E) Lui
-
T )
E Lxi -
II ( zi
-
E ) E ( x ;
-
I ) ( zi
-
I ) E ( x ;
-
I ) ( Zi
-
I ) E ( Xi
-
F) ( Zi
-
I )
ECB w
) = B ,
t
Cova '
u )
→
IV is unbiased
Cov L2 ,
x ) Where OLS is biased](https://image.slidesharecdn.com/econometrics-190820213737/85/Econometrics-Notes-37-320.jpg)
![.
N as rescaling
-
effect on Y
per
unit
change in X
-
ex :
Mariel boat lift
Reduced form : COV Cy , z )
Uhem .
Ct
=
Xo
t
X , Nublmmig et
t
X c
t
8 t
t
Uct →
X
NUM Immigrants ⇐
=
fo t
8 , post
t
82 Miami c
t 83 post +
°
Miami c
t
Ect →
IV
.
IV :
a ratio of 2 Slope coefficients interpretation
E ( y i
-
5) ( z i
-
Z ) E ( Xi
-
I ) ( Zi
-
I )
E ( Zi
-
E) 2
E ( z ;
-
I )
2
-
Drug trial example in 2 steps
-
First step
:
Erie.IE?IIIa:::us's .
} -
miss .
-
a
-
Reduced Form :
y ,
=
To t
IT ,
2 ;
t § ;
I ,
=
y-z= ,
-
5 z = o
= -
16+5 = -
I I
.
Continuous 2
-
IV estimator cannot be written in
'
.
ratio of difference
"
form
-
B , v
=
COV C
y ,
I )
var ( I )
Xi Comes from first
stage where Zi ,
other Xi 'S
predict good
←
predicted value of ×
Variation in Xi
:
first stage
:
regress x on 2-
TWO
Stage least squares second
stage
:
regress y on Ea other x 's
'
heterogenous treatment effects
.
local
average treatment effect ( LATE )
.
Why we need a
strong enough first stage
-
W/ I
exogenous instrument
,
need f -
stat of 10 ( stronger is better )
-
a weak first stage magnifies any bias in IV
E I Bw ] -
-
B ,
t
CoV Luiz )
COV ( X ,
2 )
-
prefer IV if Corr ( 2 ,
U ) I Corr ( 2 , X ) L Corr ( X , U )
-
a weak first stage leads to large standard errors](https://image.slidesharecdn.com/econometrics-190820213737/85/Econometrics-Notes-38-320.jpg)



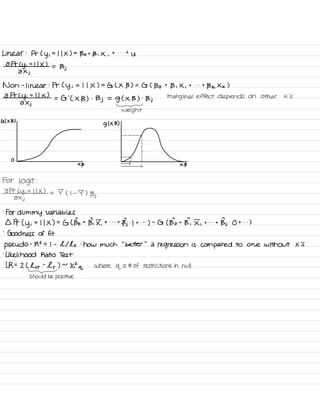
![Non -
linear Models
.
Dummy variables :
X ,
=
O
I
Dummy y
variables :
y i
=
I ex :
unemployed
O not
y ;
=
Bo t
B , Xi t
Bz Xi t
Ui
Et yi
I
Xi ] =
Bo t
B , Xi t
Bz Xi =
Pr C
y
= I I X )
Bj 's =
a Pr ( y i = I I x )
2 Xj
Bj ×
100 →
percentage point change in Pr ly i = I I x )
Pr L
y ;
= I I X ) E to ,
I ]
y i
t
Bo t
B , Xi t
Ui
I .
Ji 7 I or yn i SO is possible
2 .
homoskedasti city is violated
Alternatives to Linear Probability Model
Stats Review
.
A E B :
independent
PLAN B) =
PLA ) .
PCB )
E Ty ] =
Ply = 1) * I t
Ply
=
O ) *
O =p
* I t ( I -
p ) * o =p
Var Ly ) =
Etty-
ElyD2 ]
=p LI -
p )
-
PDF :
g L x ) =
Pr C X =
x )
.
CDF :
G ( 2 ) = SI g Lt ) at
=
Pr ( 2 I z )
Denial
LPM
I -
• • • • 0
Log it , probit MFX will
change with Values of X
o
.
-
÷. . . .
PII ratio](https://image.slidesharecdn.com/econometrics-190820213737/85/Econometrics-Notes-42-320.jpg)
![Et y
I X ] =
Pr ( y
= I I X ) =
X B
Pr L
y
.
-
I I x ) =
G ( X B )
It
Std Normal CDF Logistic
OL GLAD B) L I
-
When Glx B ) is Standard normal
G (2) =
f? • ÷ e
-
' " t
-
d t =
Io L z )
Pr L
y
= I I x ) =
Io L *B) →
probit
'
When G ( 2 ) is
logistic
G (2) = =
11 ( 2 )
Pr L
y
=
I 1×1=11 L X B) →
Logit
Pr ( y
=
I I x ) =
G L X B )
Pr ( y
= 01 X ) = I -
GL X B )
fly I X ) =
G ( X B)
Y
( I -
G L X B ) )
' -
Y
II,
{ G L x ;
B)
Yi
Li -
G Lxi B) I
' -
Yi
}
.
Log likelihood function
l = Eh
, y ; In G L X ; B) t.IE,
LI -
y ; ) It -
In G C Xi B ) ]
ex :
no X 's
What is
probability of smoking ?
SRS :
n smokers
=
310 n
nonsmokers
=
497
D=
#
o ↳
310+497
=
.
38
What is the maximum likelihood estimate of 15 ?
Pr L smoke ) =p Pr C no smoke ) = I -
p
Joint prob
:
p
310 .
( I -
p )
497
In ( p
310
.
( I -
p )
497
) =
310 In p
t 497 In ( I -
p ) =
lo
¥ =
3¥ -
YIP = O
p
=
0.38 Same as OLS
OLS da MLE tend to be same](https://image.slidesharecdn.com/econometrics-190820213737/85/Econometrics-Notes-43-320.jpg)
![Office Hours 2-5
Thurs .
Final 10 MC ,
2 LF
( 60 pts ) ( 70 pts )
Putting It All Together
COV Lbw , baby tilth outcomes ) > O
OV B
{
motmneatth
environmental factors
genetic L Mlf )
.
Twin FE Study
-
everything about mom controlled for
-
variation due to environmental factors
'
hij
=
a t
bwij B t
Xi
'
8 t
a ;
t
Eij
Bols
=
B t
COV ( Xi , b Wsj ) +
COV Lai .
b Wii )
ou B
V L bwij )
V Lbwij )
If driven by Xi Gai ,
need to target X ;
or a i not bwij
.
First -
differencedmodel :
hi I
-
h iz
=
L X e
-
X
z
) t
L b wi I
-
b Wiz ) B t LE is
-
E iz
)
-
Fixed effects : ( his -
hi.
) =
( a .
-
I ) t Lbw is
-
Twi ) B t
( E is
-
E )
F D= FE if there are 2 Obs per group
What assumption gives us a consistent B in FD ?
( OV I ( b Wi I
-
b Wiz ) ,
( E is ,
E iz ) ] =
O
Use :
cluster by mother →
robust .
fixes autocorrelation
↳
otherwise SES are
wrong so inferences
may be incorrect
.
Diff in diff :
IT t
-
IIc
.
control :
acts as counterfactual
.
Regression model :
Duration it
=
Bo
t
B ,
POST go
t
Bz HIGH it133 HIGH *
POST go
t
Uit
-
test in KY 4 MI b/c labor markets are very different
↳
TO what extent can findings from one state be extrapolated TO another
↳
could have heterogeneous treatment effects
'
Key feature of diff -
in -
diff :
don't necessarily have to include extra X 'S b/c won 't bias
HIGH coefficient
↳ however ,
could include them to be more precise ( linked to R2 )
.
EX :
239.09
-
151.08 =
88.01
118 .
26
-
118 .
58 = - -
0.32
88 .
33](https://image.slidesharecdn.com/econometrics-190820213737/85/Econometrics-Notes-45-320.jpg)

![Review
.
simple Linear Regression Model
Yi =
Bo t
B ,
X i
t
Ui
.
zero Conditional Mean Assumption :
E EU ] =
O ,
E EU IX ] is constant
↳
implies Cov Cu ,
X ) =
O C no linear relationship )
.
Ordinary Least Squares
↳
minimize average squared residual
.
Omitted Variables Bias :
E I BT ] =
B ,
t
Bz
COV ( Xii .
X iz )
Var L Xii )
.
t -
test
a
t n =
Bj
Bj se C BI )
If I t Bj I ) t c , reject Ho
Confidence interval :
( Bj -
t c
.
Se C Bj ) ,
Bj t
to .
Se C Bj ) )
.
f -
test
F =
C RE r
-
RZ ) lol
q
= # of X
'
s
you are testing
( I -
RE r
) I ( n
-
k -
t )
k =
# of × is in ur
regression
Reject Ho at Sig level a if F > C
.
Lagrange Multiplier Statistic
use if
large sample Cn 7100 )
I .
Estimate restricted model
2 .
Take residuals it E regress them on all variables
3 .
LM =
n RE where R } is from the second regression
.
polynomials for non -
linear ites
can use
squared Variables if effect isn't constant
TO find marginal effect ,
take partial derivative
.
Dummy variables
-
To interpret dummy coefficients : examine expected value
If D= O → E I
y
I X ; D= OT =
Bo t Bi X
If D= I →
Et y
I X ; d = IT =
Bo t
So t
Bi X
.
time period dummy in regression
-
coefficient is interpreted as the difference in the dependent variable between that
period and the excluded period
'
Using dummy variables for multiple categories
-
include all but one category in
regression
-
coefficient interpreted as difference in
average y between included and
excluded groups](https://image.slidesharecdn.com/econometrics-190820213737/85/Econometrics-Notes-47-320.jpg)



![.
limited dependent variables
-
dummy dependent variables
-
interpretation :
change in the probability of being in the
"
I
' '
category
-
linear probability model
-
issues
-
predicted values outside of O da I
-
heteros ked asti city
-
Probit Model
-
standard normal Cumulative distribution
-
E L y I X ) =
Prey =
I I X ) =
Io ( X B )
-
use maximum likelihood
-
Logit Model
-
logistic function
-
Maximum likelihood
-
Pr L
y
= I I X ) = G ( X B ) →
fly I × ) = G L X B ) Y 51 -
G L X B ) ]
' -
Y
Pr Cy =
O I X ) = I -
G L X B )
-
pick B to maximize the chance we would
get the dataset we observe
-
Log likelihood
-
Marginal Effect
-
LI ) ( I -
I ) Bj
-
Likelihood ratio test
-
LR =
2 ( lur -
l r ) ~
XZ a](https://image.slidesharecdn.com/econometrics-190820213737/85/Econometrics-Notes-51-320.jpg)























































































