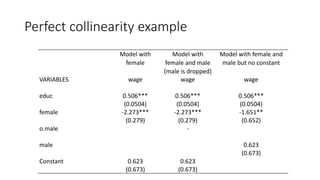
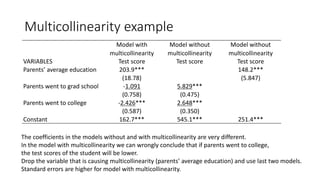
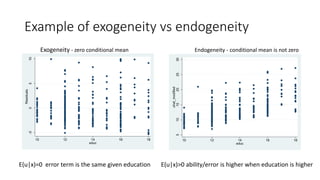
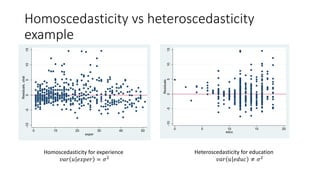
Multiple linear regression models relationships between an outcome variable and multiple explanatory variables. It assumes a linear relationship between the variables and estimates coefficients that represent the effect of each explanatory variable on the outcome, holding other variables fixed. Ordinary least squares estimation minimizes the sum of squared residuals to estimate the coefficients, resulting in unbiased, best linear unbiased estimators under the assumptions of linearity, random sampling, no perfect collinearity, zero conditional mean of errors, and homoscedasticity. The estimated coefficients can be interpreted as the partial effect of changes in each explanatory variable on the outcome.









![OLS in matrix form
Unbiasedness follows from
E[β̂|X] = E[(X0
X)−1
X0
(Xβ + u)|X] = β + (X0
X)−1
X0
E[u|X] = β
under H1 to H4
From H5, the variance of the estimator is given by:
V [β̂|X] = E[(β̂ − β)(β̂ − β)0
]
= E[(X0
X)−1
X0
uu0
X(X0
X)−1
]
= (X0
X)−1
X0
E[uu0
|X]X(X0
X)−1
= (X0
X)−1
X0
σ2
IX(X0
X)−1
= σ2
(X0
X)−1](https://image.slidesharecdn.com/multipleregressionmodel-240126060217-8e7647af/85/Multiple-Regression-Model-pdf-9-320.jpg)

![OLS is BLUE
Gauss-Markov Theorem
Under assumption H1 to H5, β̂ is the best linear unbiased estimator
(BLUE) of β
B Best = smallest variance
L Linear = β̂ is a linear combination of y
U Unbiased = E[β̂|X] = β
E Estimator](https://image.slidesharecdn.com/multipleregressionmodel-240126060217-8e7647af/85/Multiple-Regression-Model-pdf-11-320.jpg)






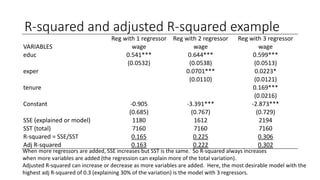
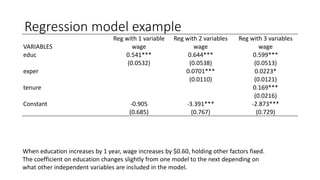
![Stata output for multiple regression
_cons -2.872735 .7289643 -3.94 0.000 -4.304799 -1.440671
tenure .1692687 .0216446 7.82 0.000 .1267474 .2117899
exper .0223395 .0120568 1.85 0.064 -.0013464 .0460254
educ .5989651 .0512835 11.68 0.000 .4982176 .6997126
wage Coef. Std. Err. t P>|t| [95% Conf. Interval]
Total 7160.41431 525 13.6388844 Root MSE = 3.0845
Adj R-squared = 0.3024
Residual 4966.30269 522 9.51398982 R-squared = 0.3064
Model 2194.11162 3 731.370541 Prob > F = 0.0000
F(3, 522) = 76.87
Source SS df MS Number of obs = 526
. regress wage educ exper tenure
The coefficients are estimated with the Stata program.](https://image.slidesharecdn.com/multipleregressionmodel-240126060217-8e7647af/85/Multiple-Regression-Model-pdf-18-320.jpg)




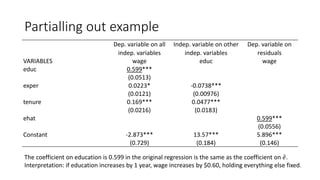


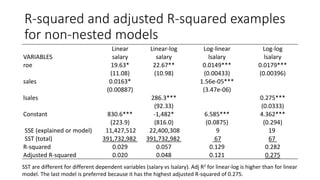
![Adjusted R-squared calculation
R-squared = SS Model /SS Total = 2194 / 7160 = 1 – SSR/SST = 1 – 4966/7160 = 0.306
Adj R-squared = 1 – [SSR/(n-k-1)] / [SST/(n-1)] = 1 – (4966/522)/ (7160/525) = 0.302
30% of the variation in wage is explained by the regression and the rest is due to error.
_cons -2.872735 .7289643 -3.94 0.000 -4.304799 -1.440671
tenure .1692687 .0216446 7.82 0.000 .1267474 .2117899
exper .0223395 .0120568 1.85 0.064 -.0013464 .0460254
educ .5989651 .0512835 11.68 0.000 .4982176 .6997126
wage Coef. Std. Err. t P>|t| [95% Conf. Interval]
Total 7160.41431 525 13.6388844 Root MSE = 3.0845
Adj R-squared = 0.3024
Residual 4966.30269 522 9.51398982 R-squared = 0.3064
Model 2194.11162 3 731.370541 Prob > F = 0.0000
F(3, 522) = 76.87
Source SS df MS Number of obs = 526](https://image.slidesharecdn.com/multipleregressionmodel-240126060217-8e7647af/85/Multiple-Regression-Model-pdf-27-320.jpg)