Downloaded 10 times




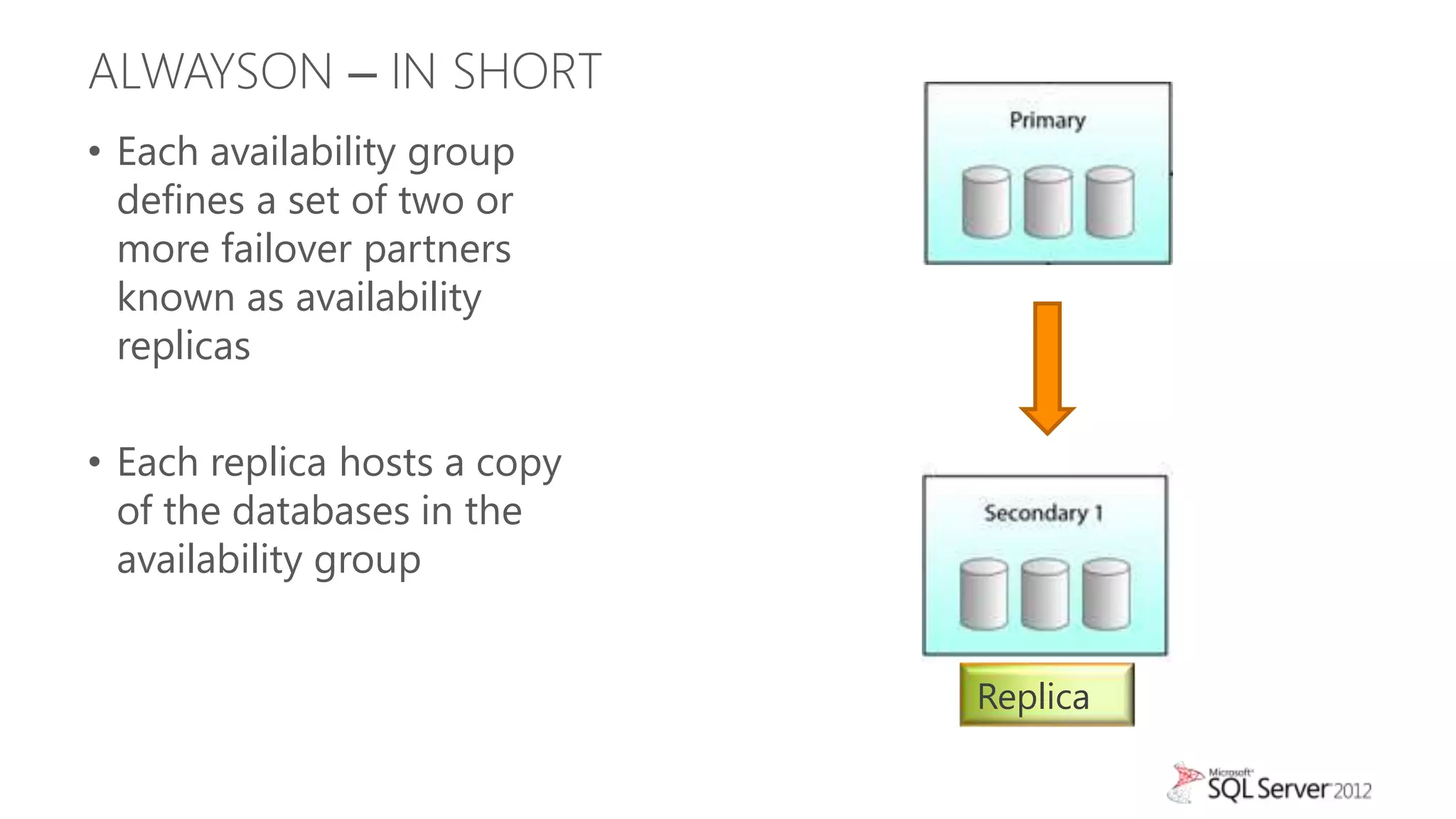
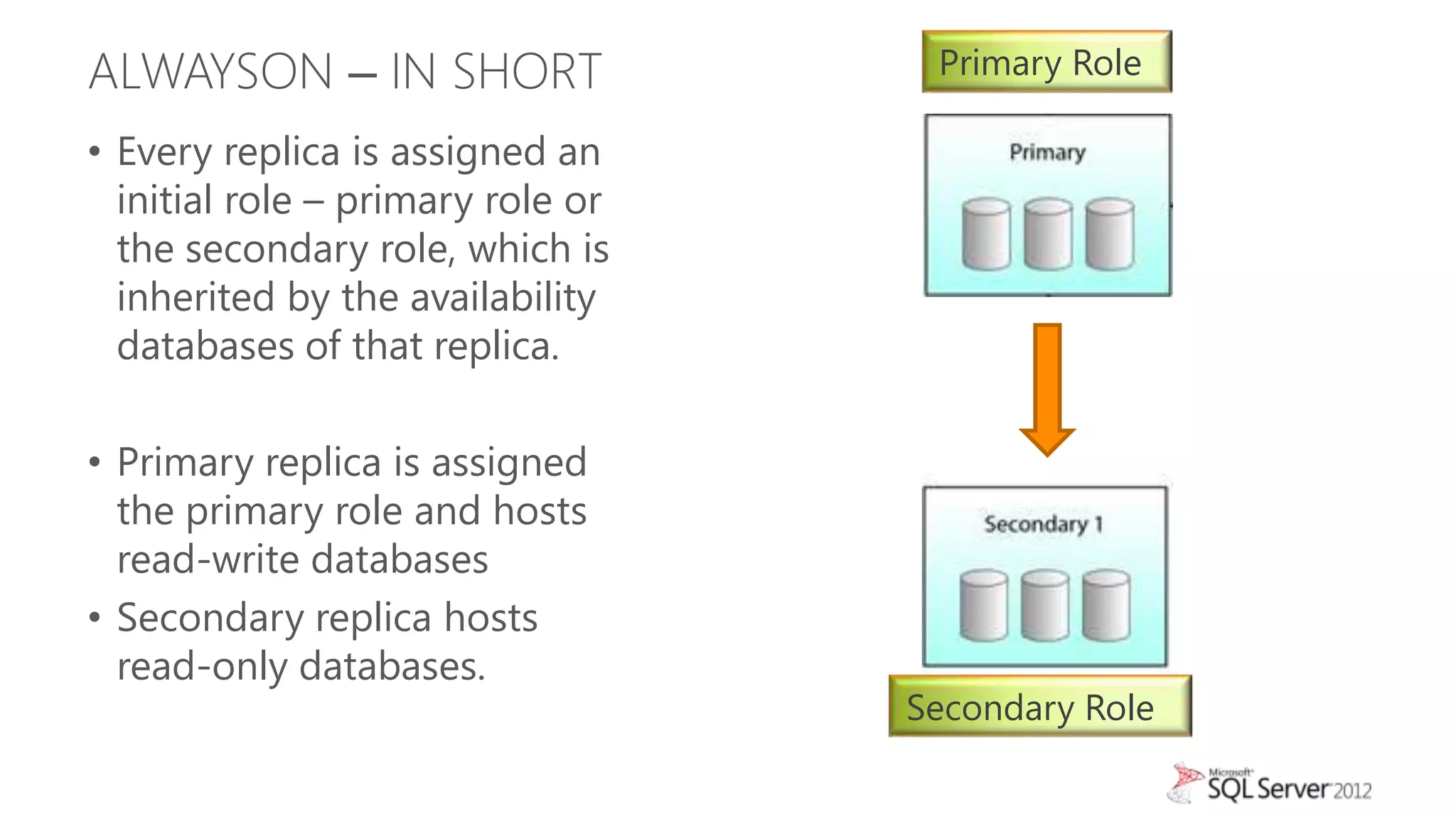
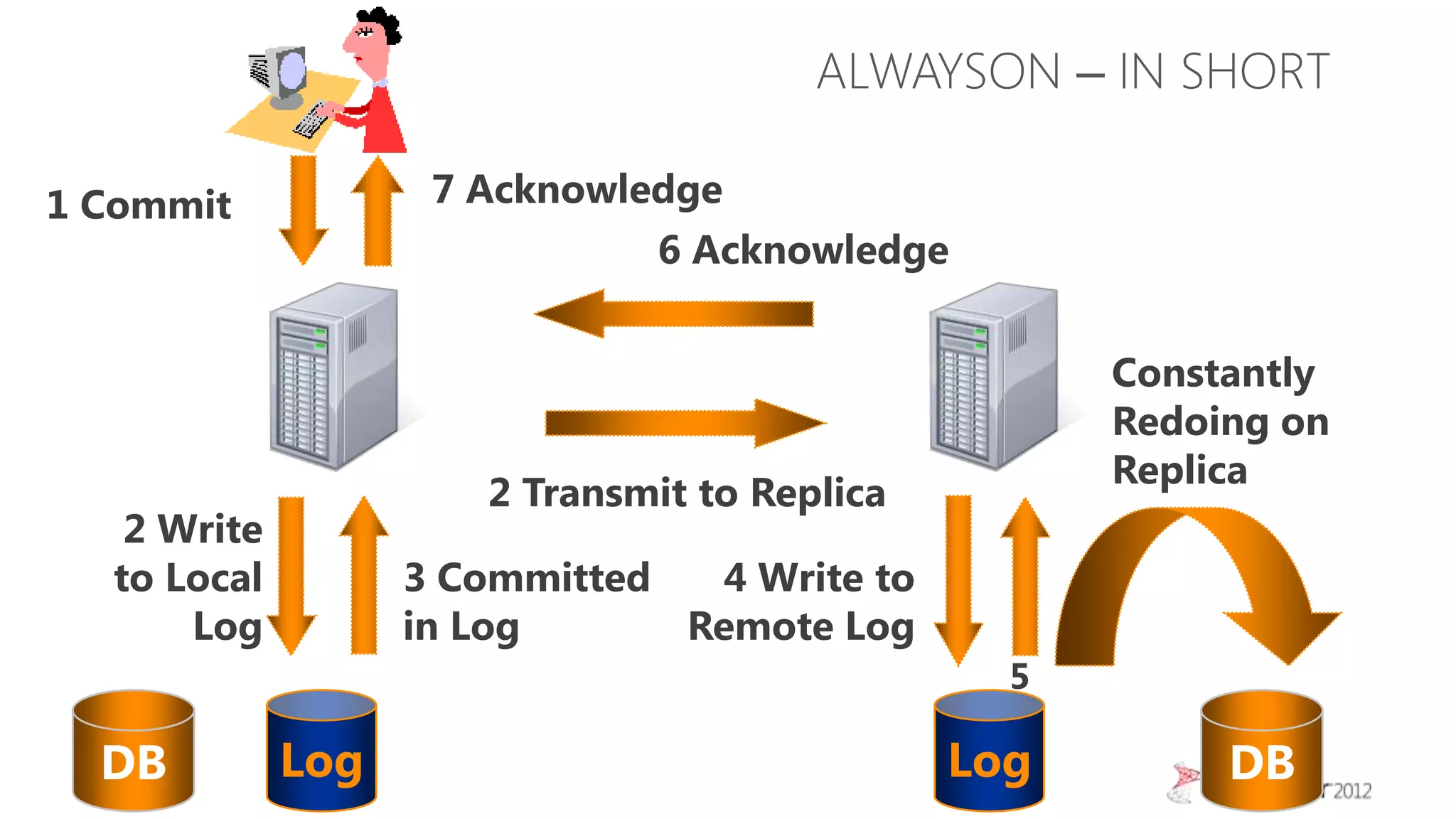






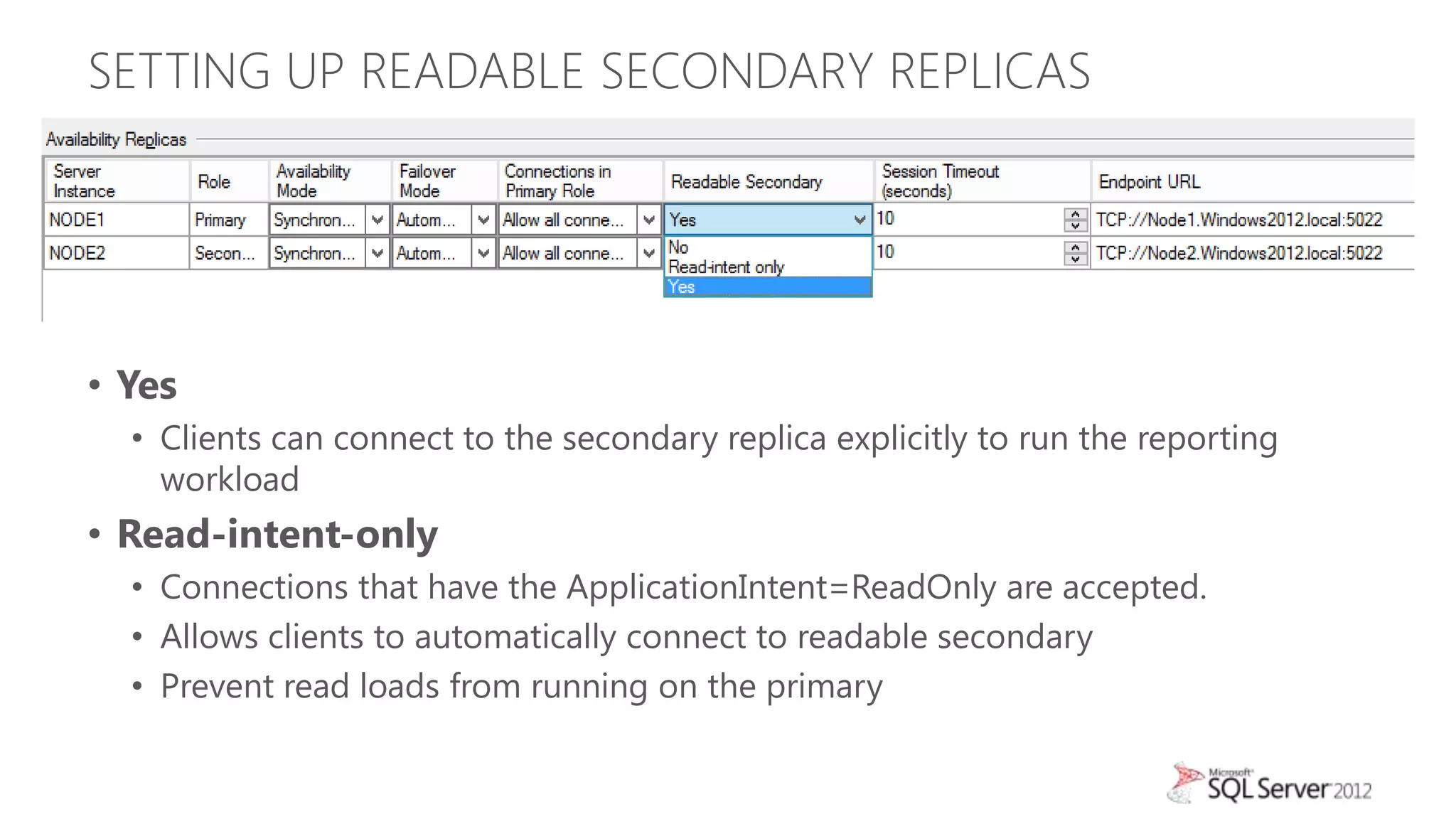

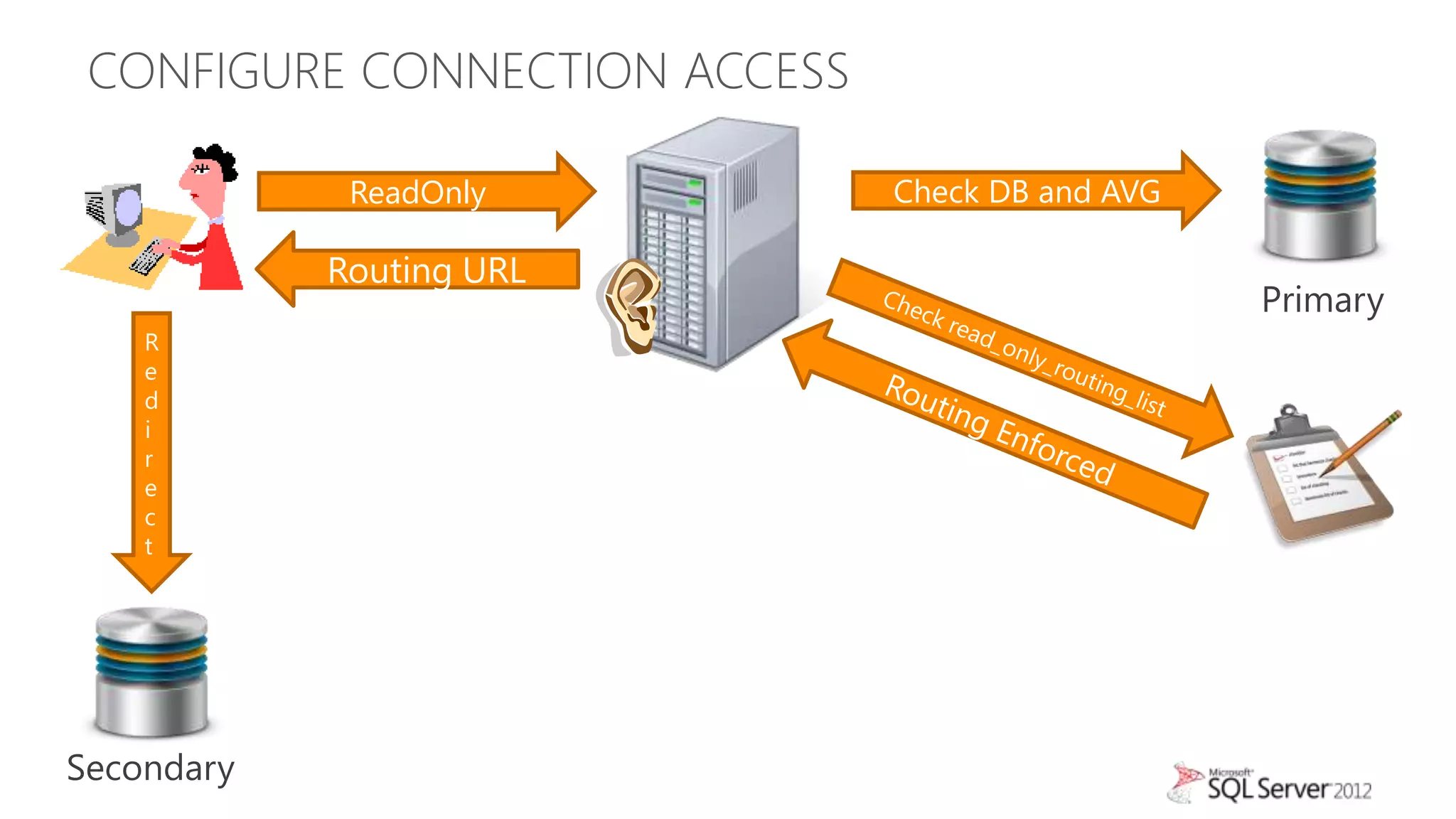









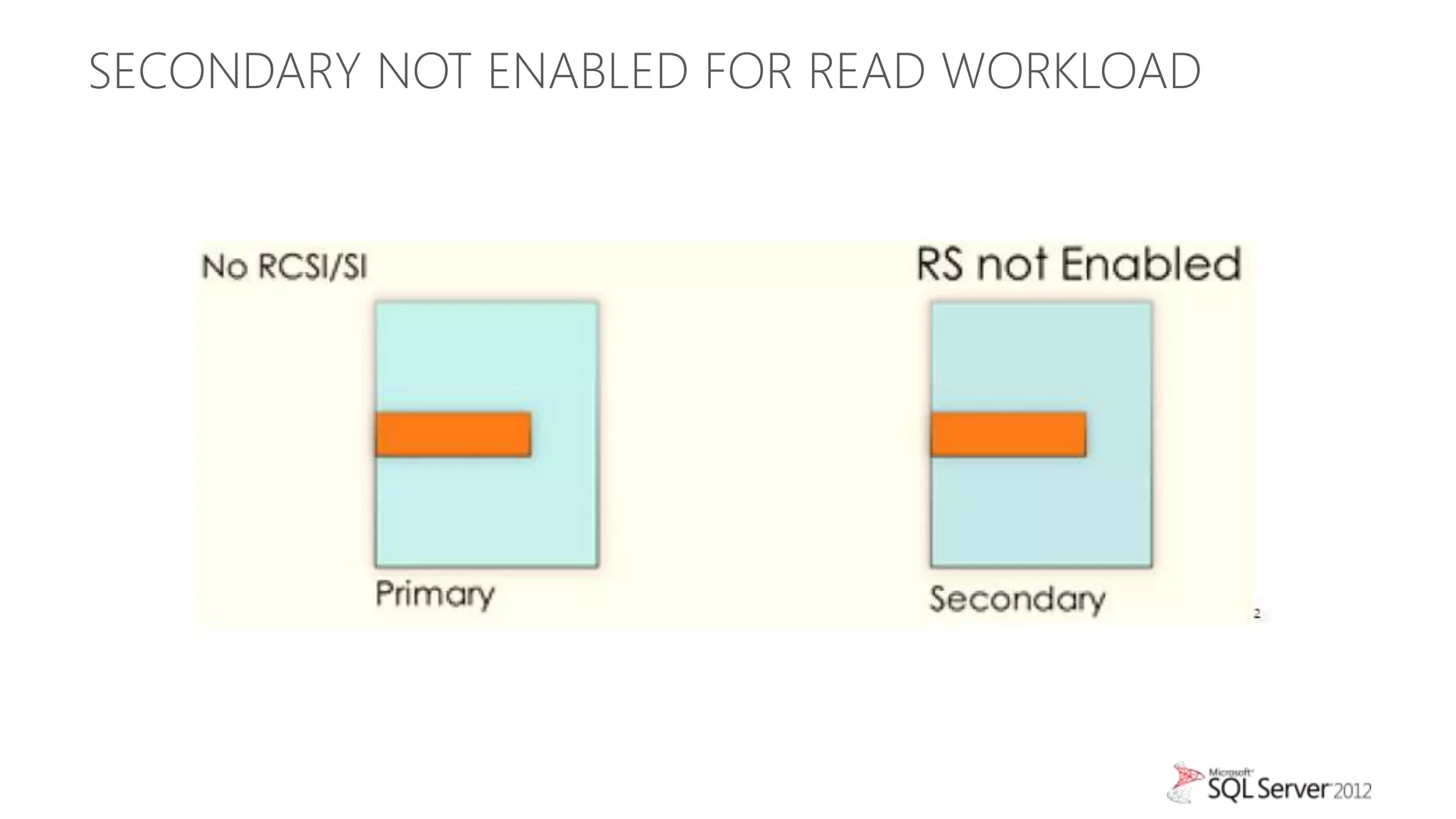
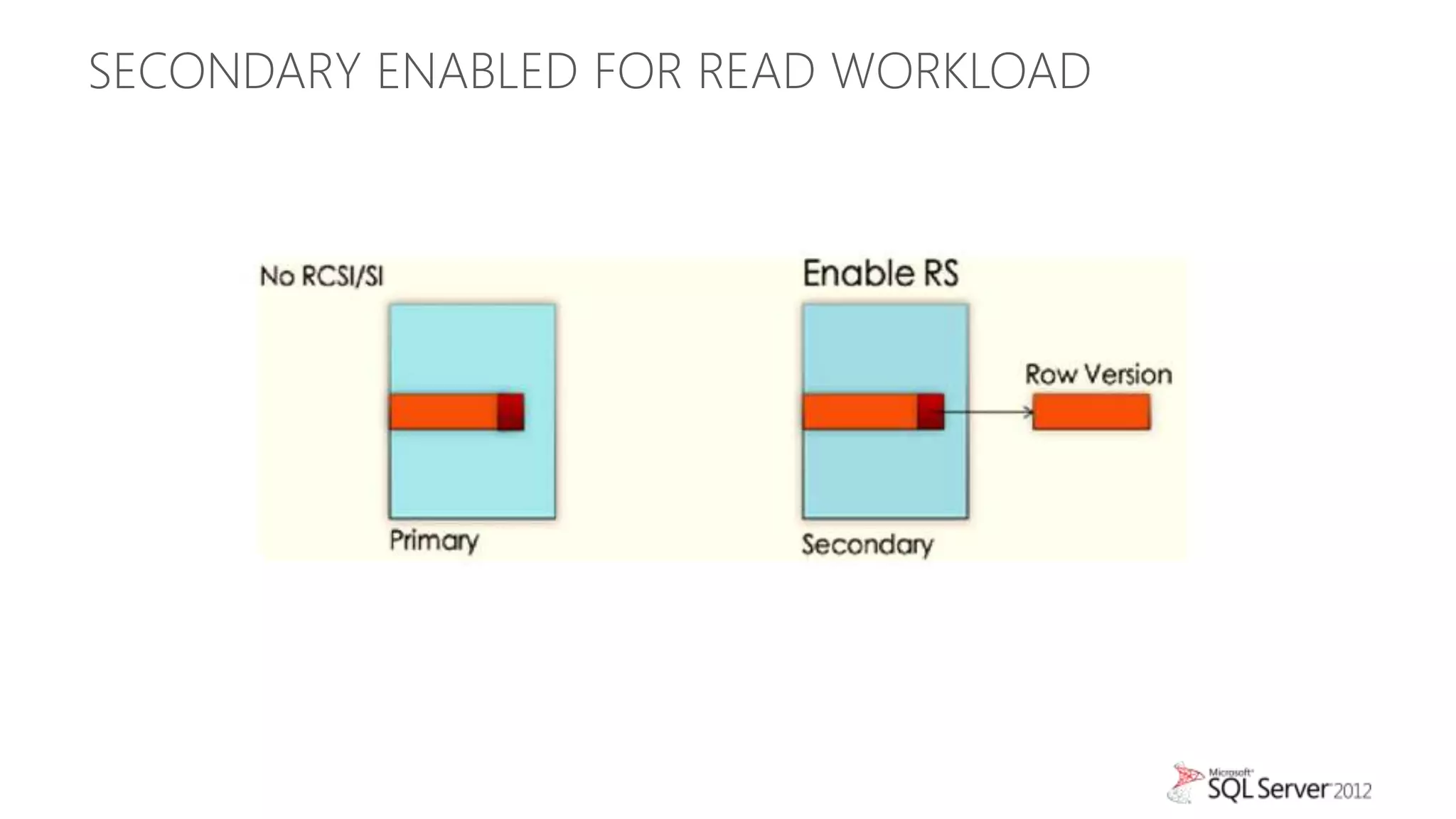
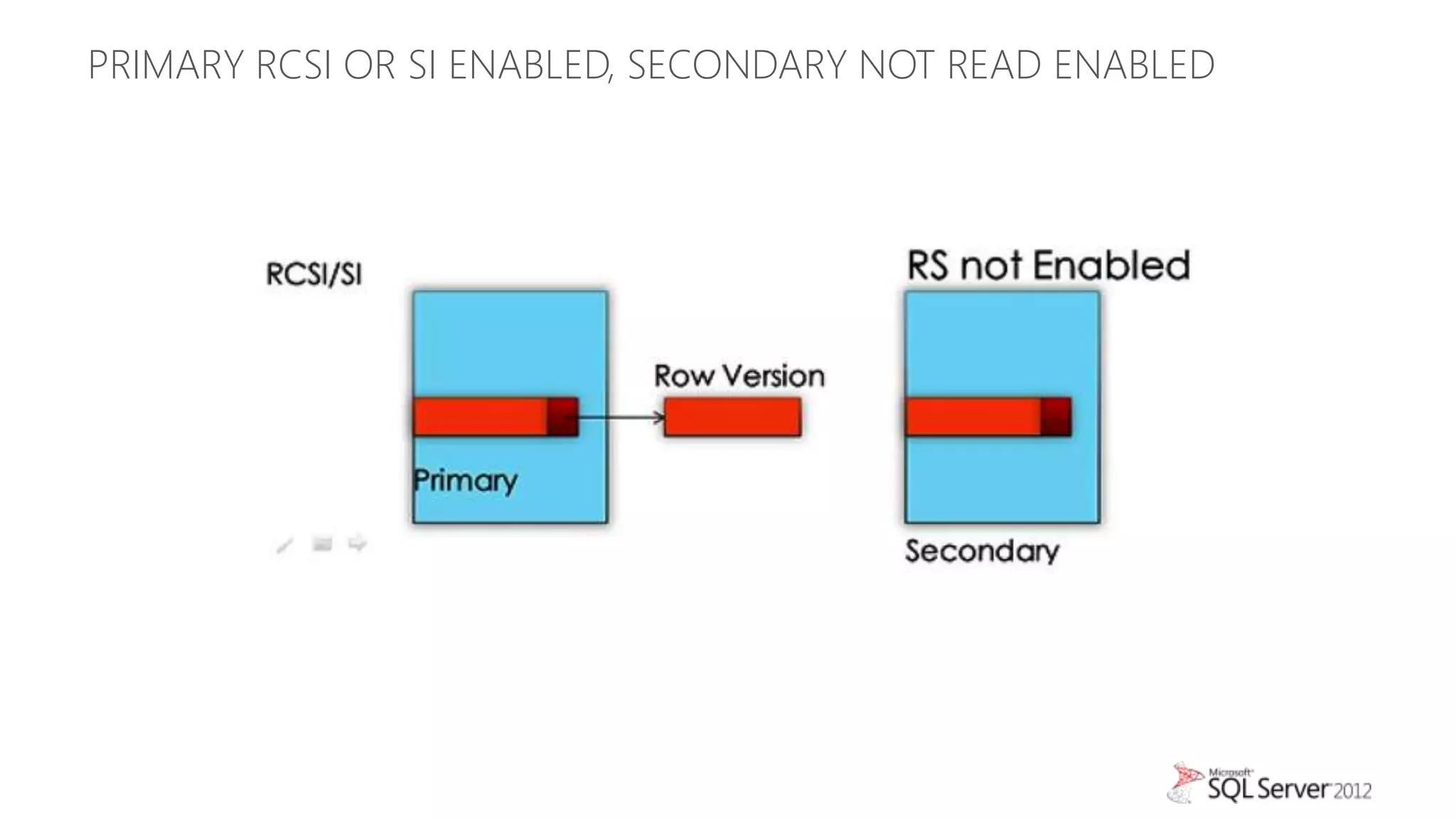
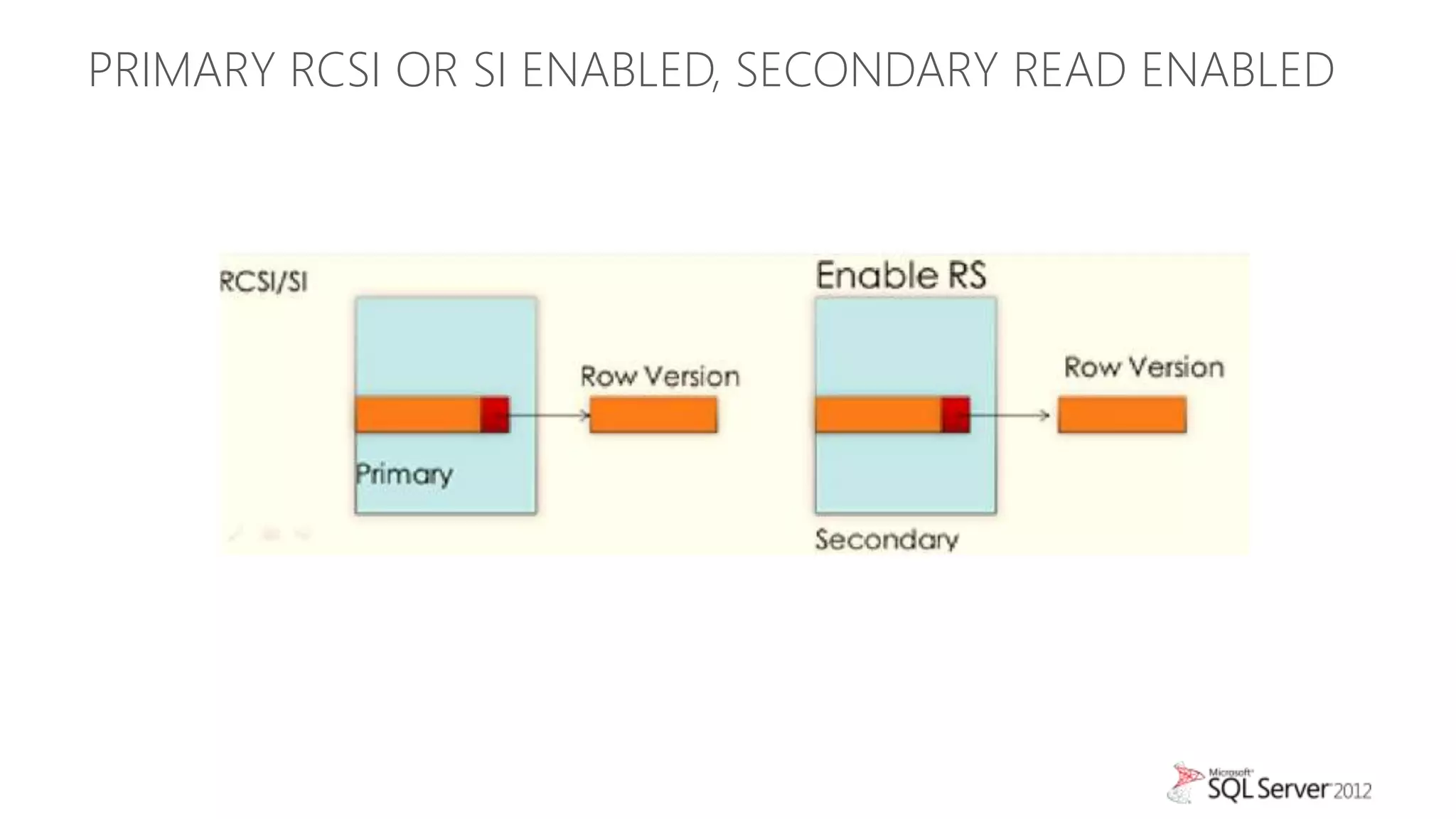
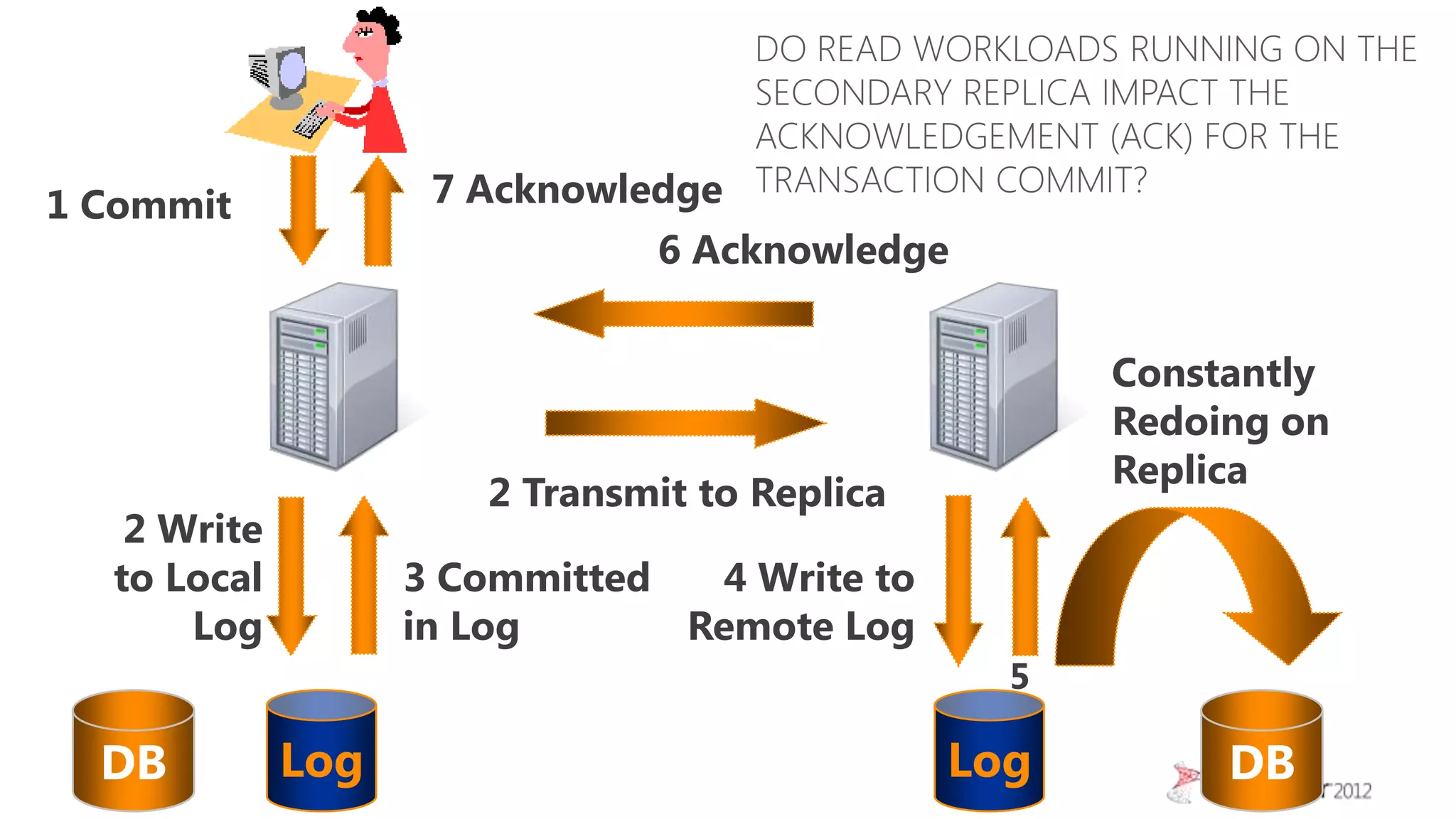




This document summarizes an agenda for a TechNet Live meeting about using SQL Server AlwaysOn availability groups to offload reporting workloads from production servers. The agenda includes an introduction to AlwaysOn, setting up readable secondary replicas, configuring connection access, performing backups on secondary replicas, and discussing the impact of workloads on high availability, primary servers, and query plans.




























































![[db tech showcase Tokyo 2015] D25:The difference between logical and physical...](https://cdn.slidesharecdn.com/ss_thumbnails/dbts-tokyo-2015d25oracledbvisit-software-150619090737-lva1-app6891-thumbnail.jpg?width=640&height=640&fit=bounds)