Downloaded 184 times








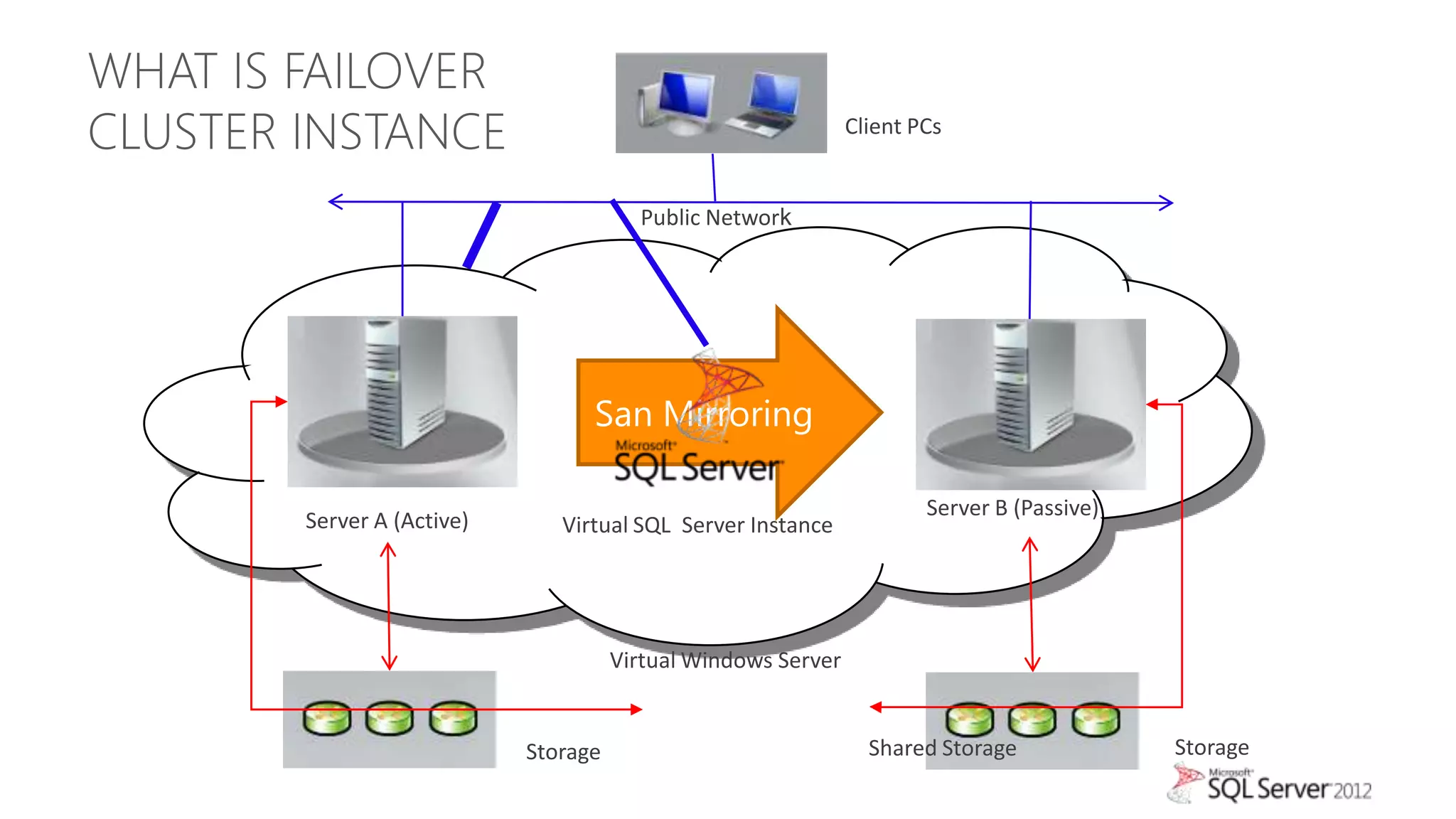
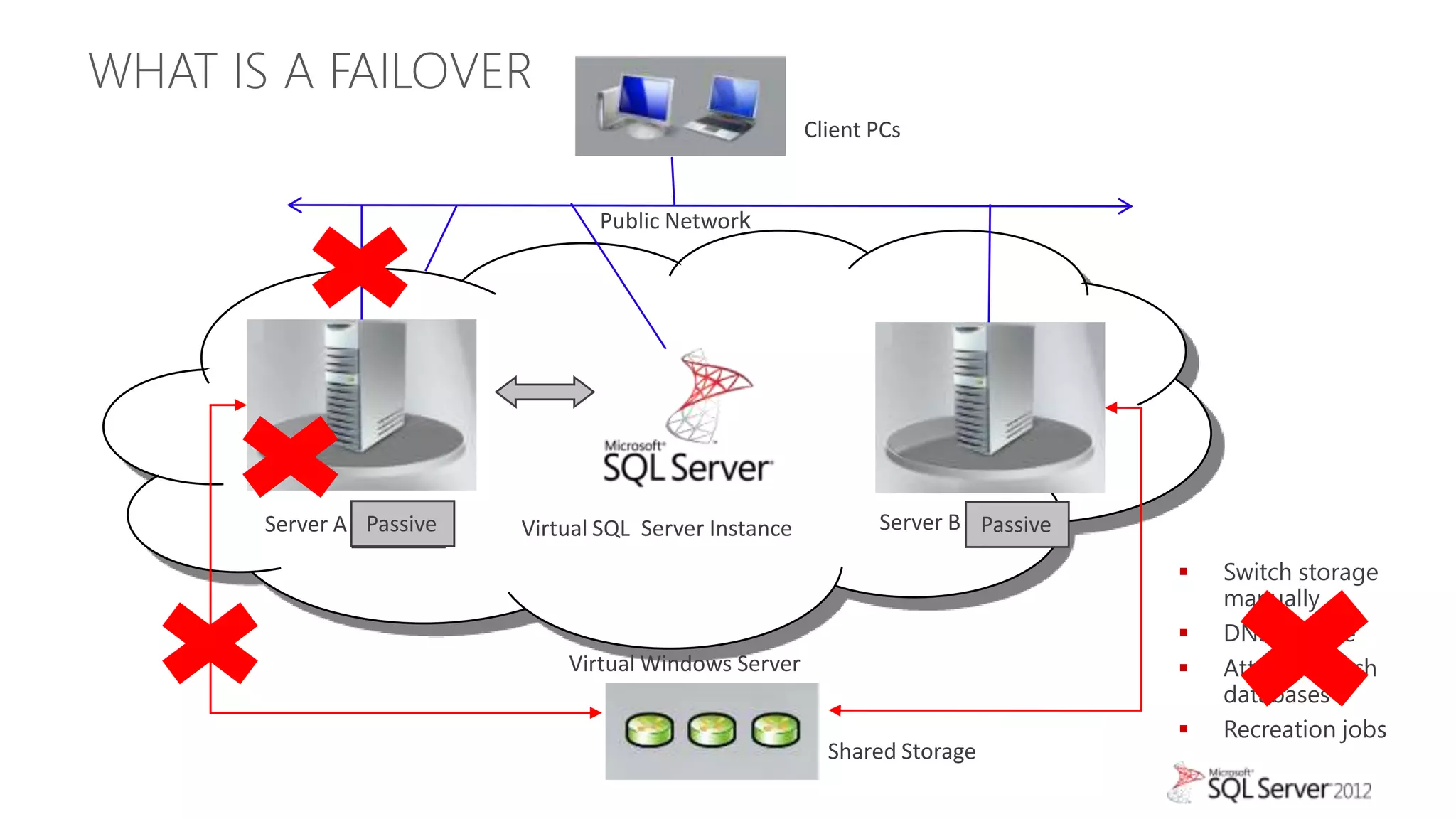
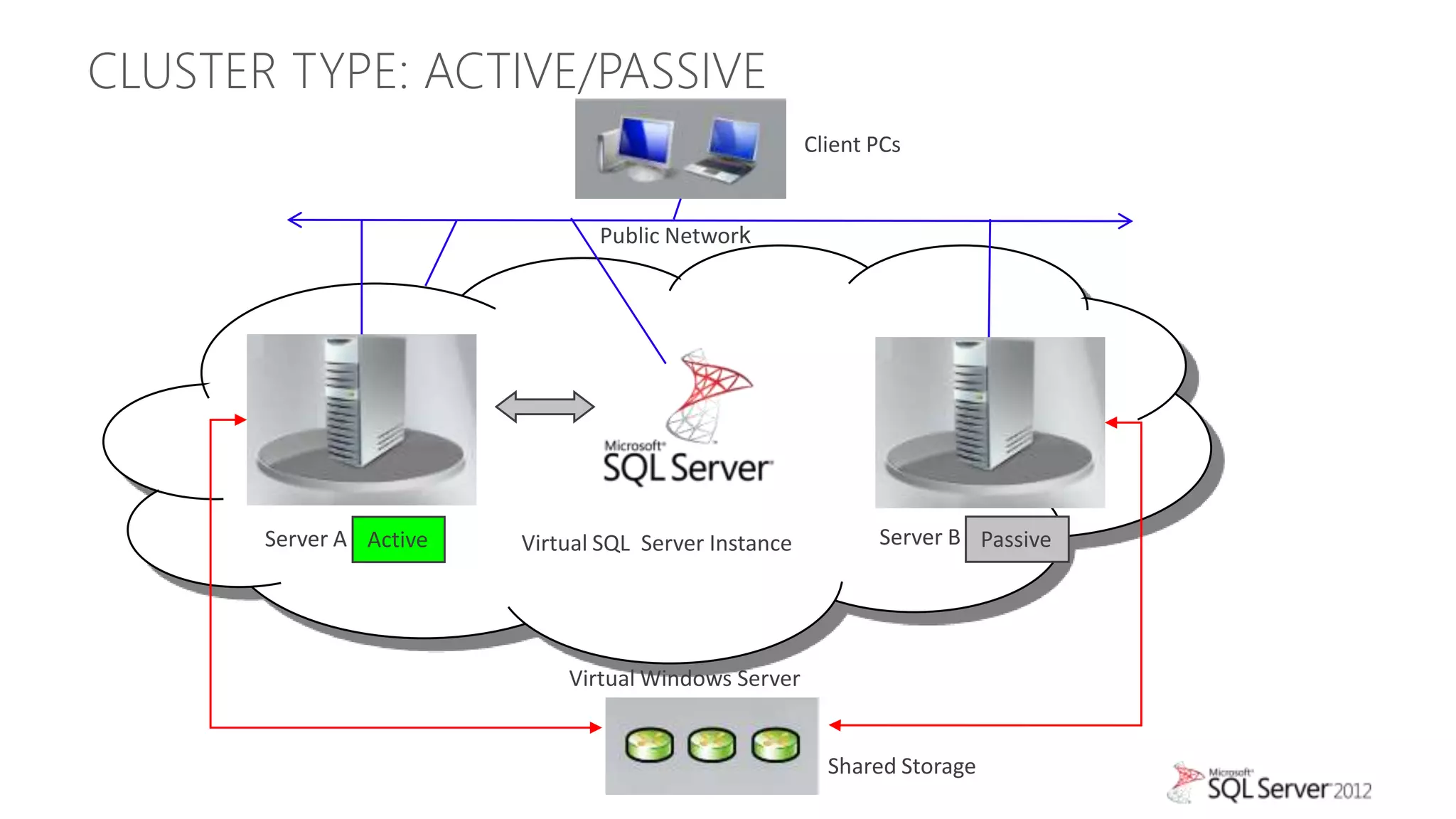
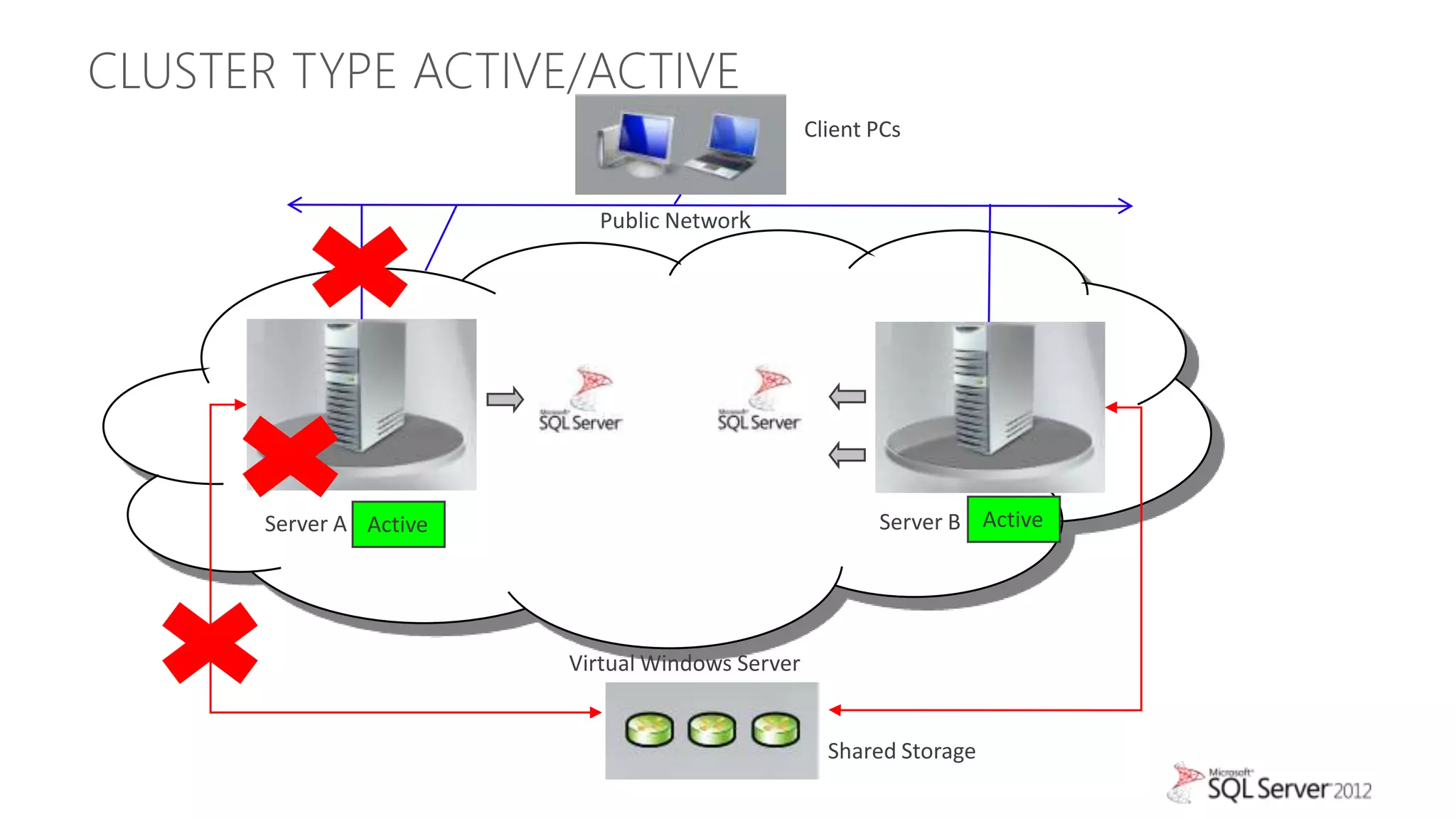
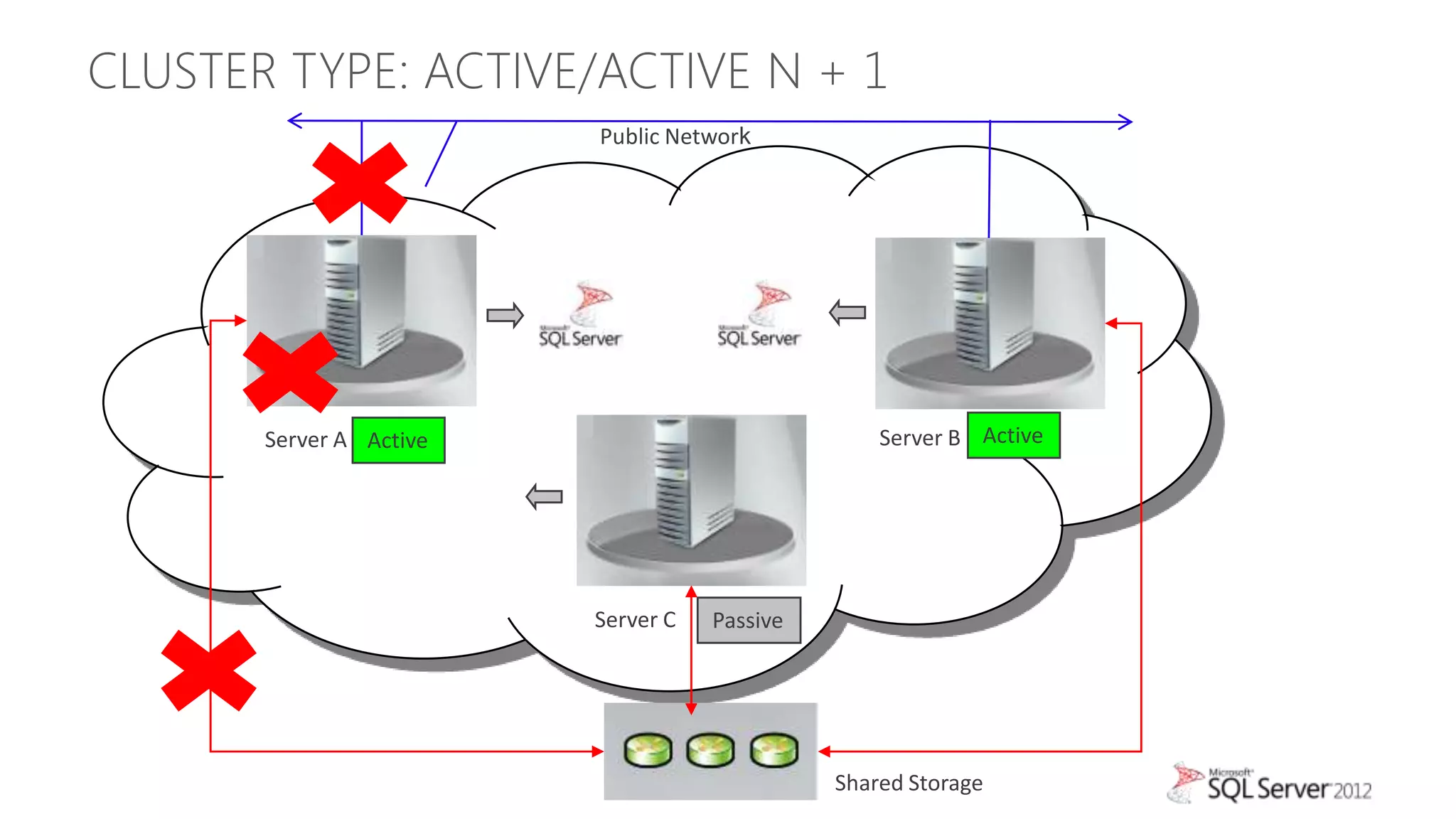




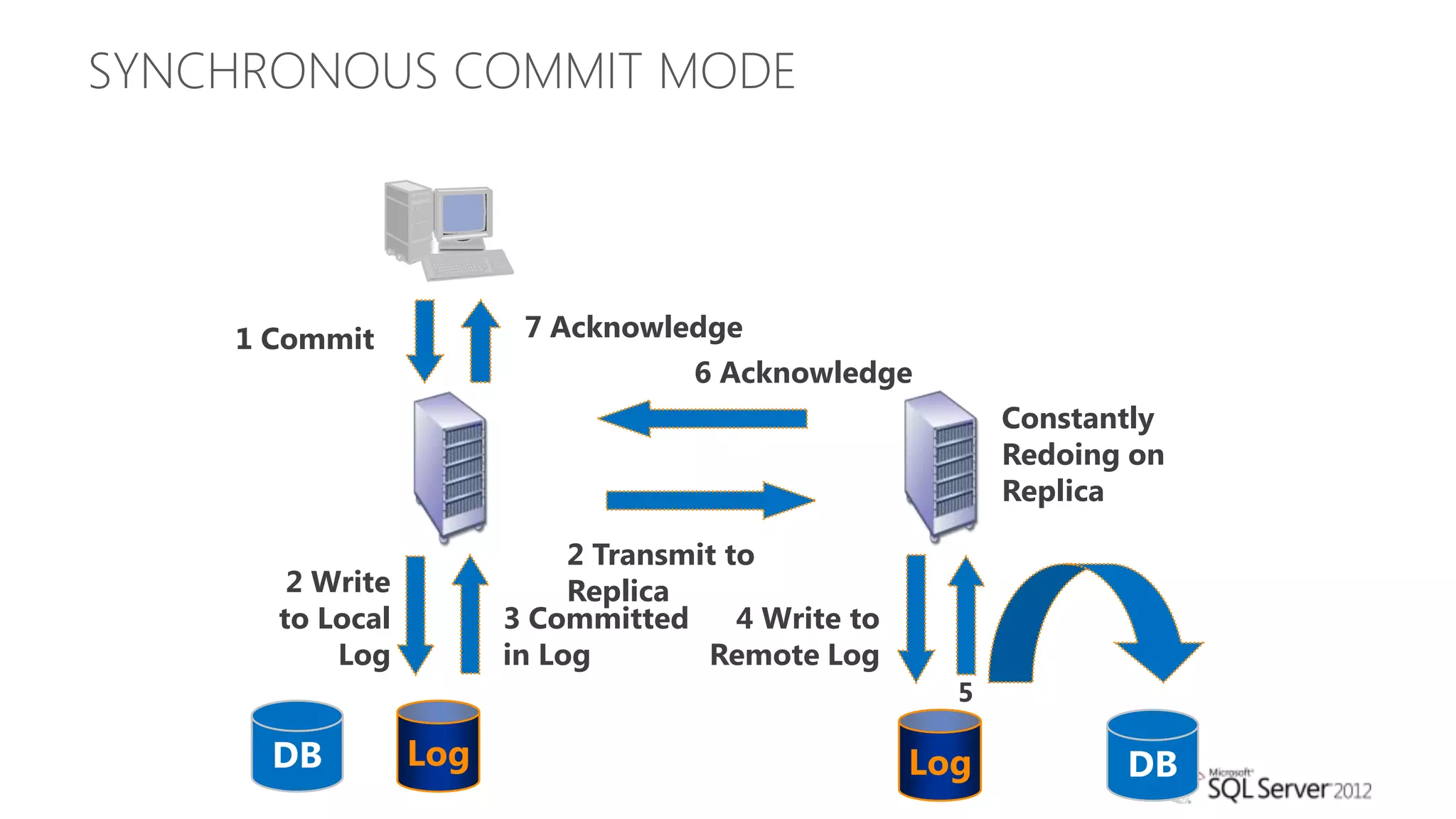
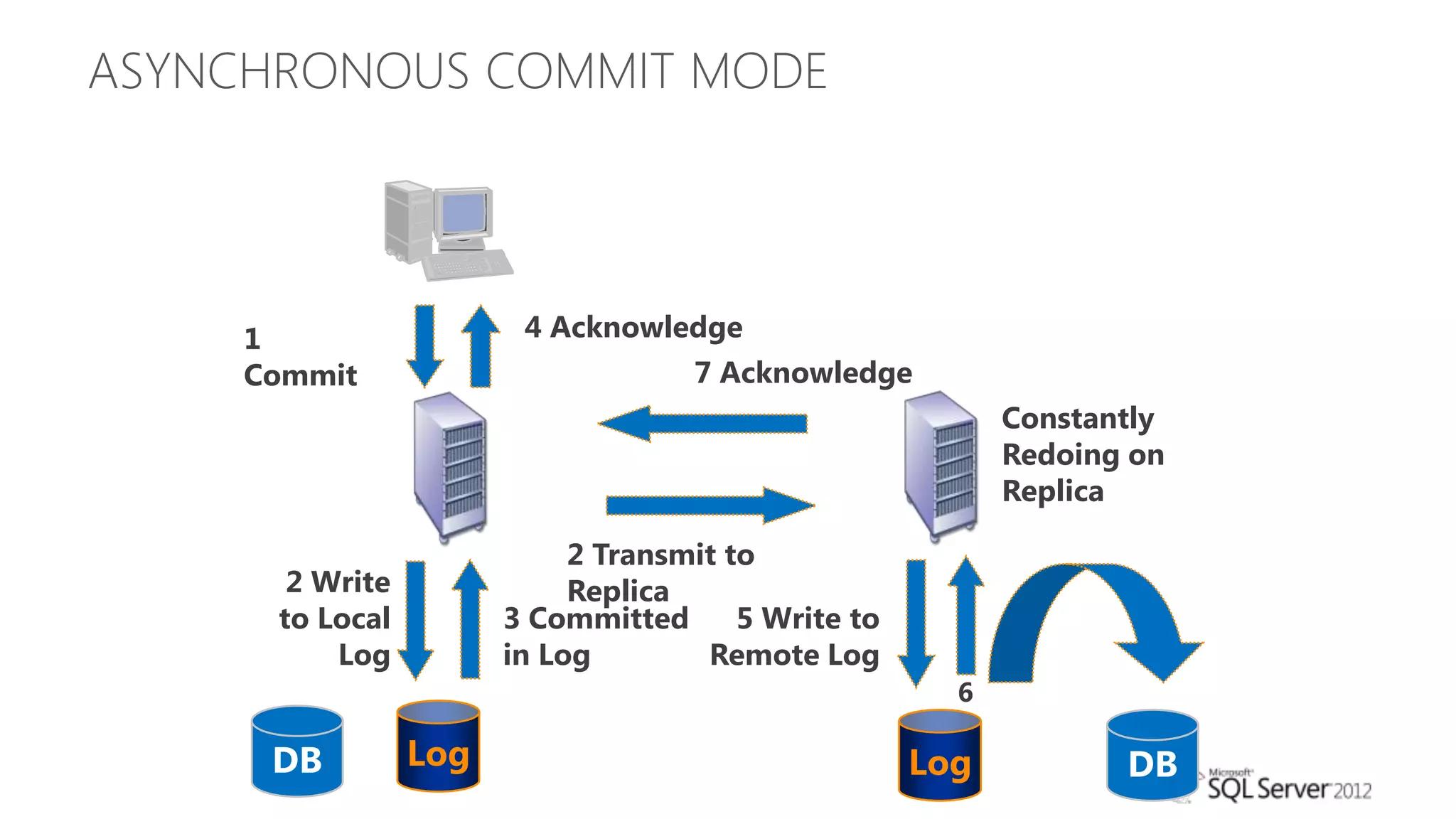
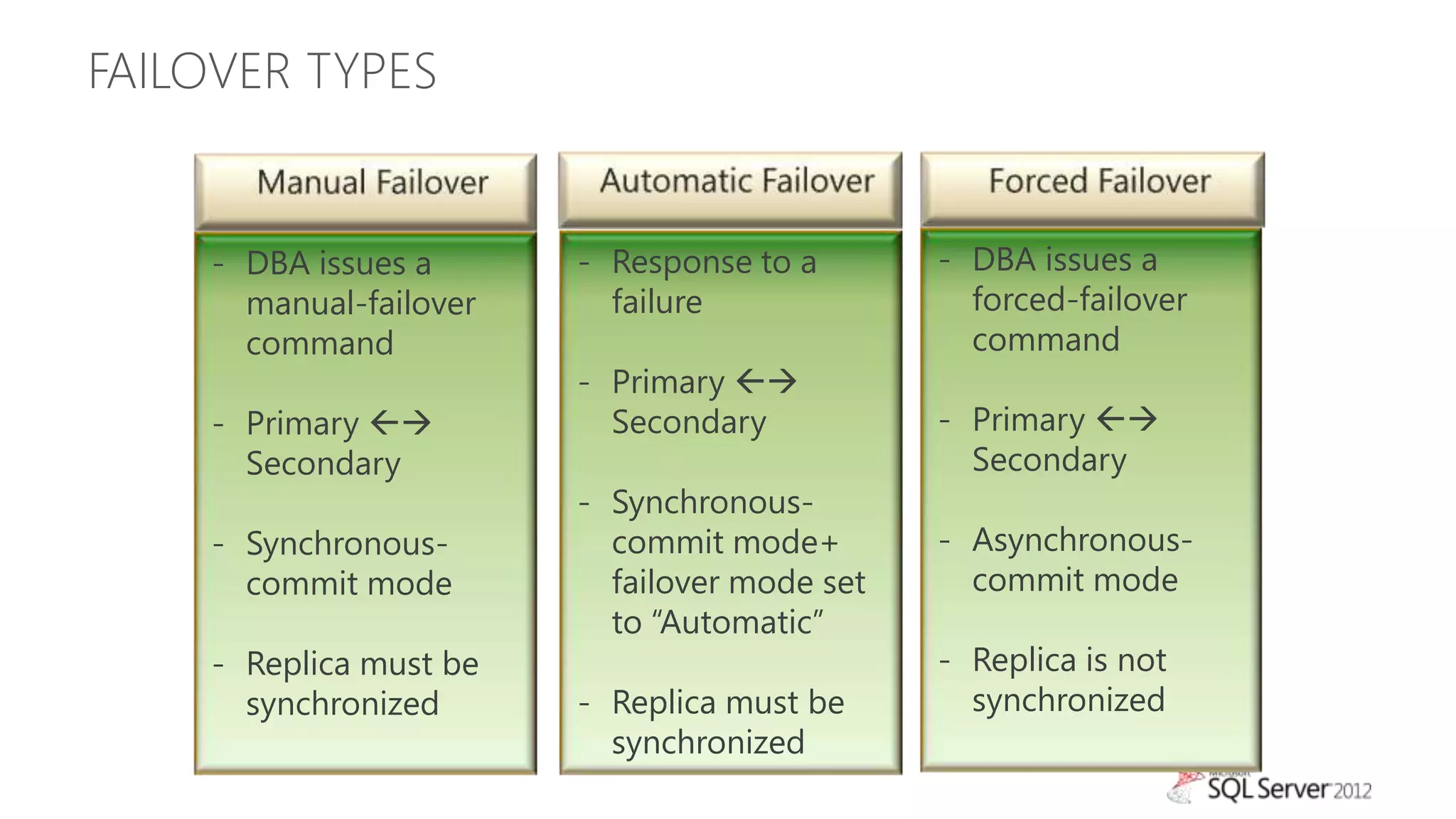

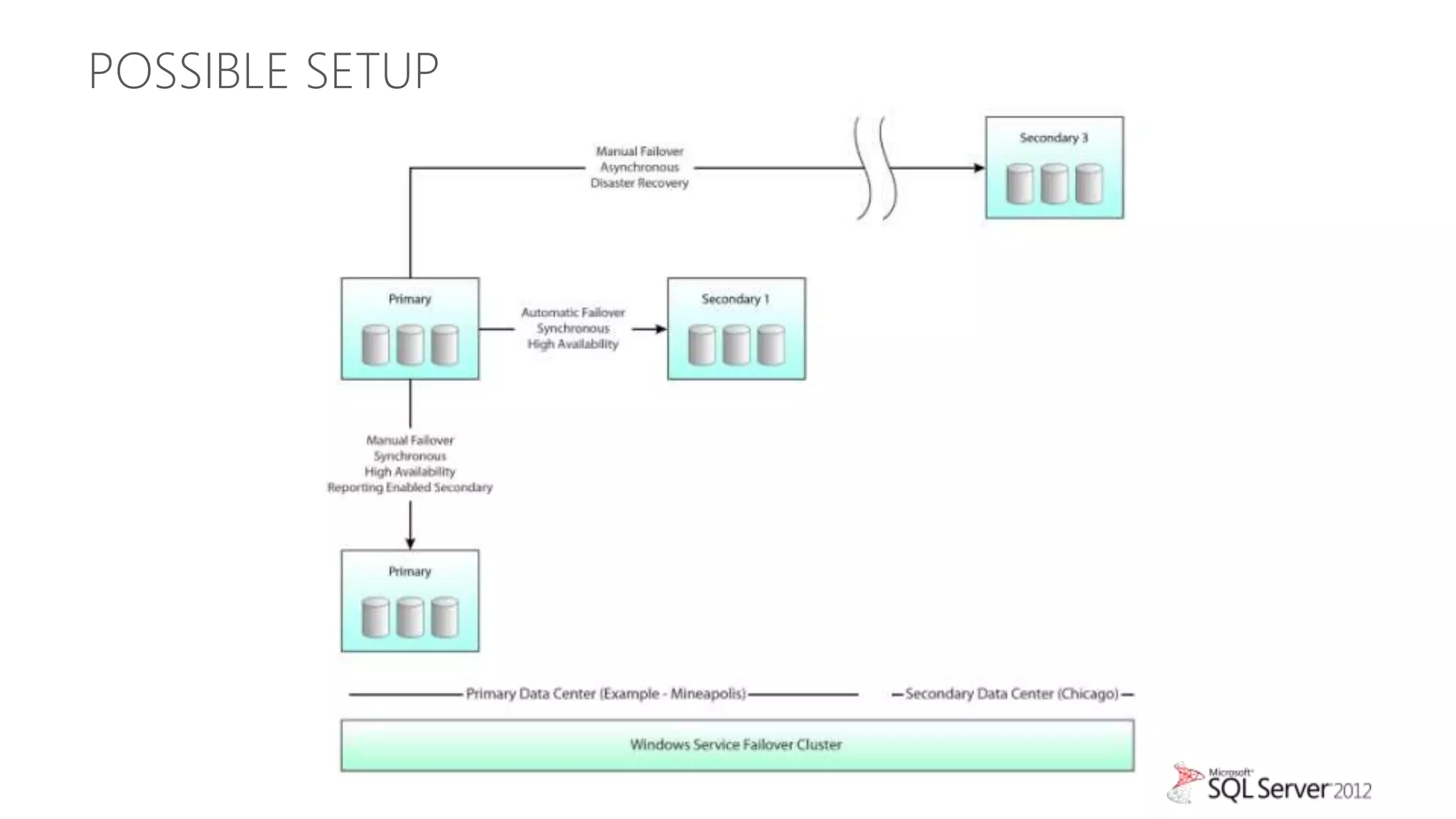














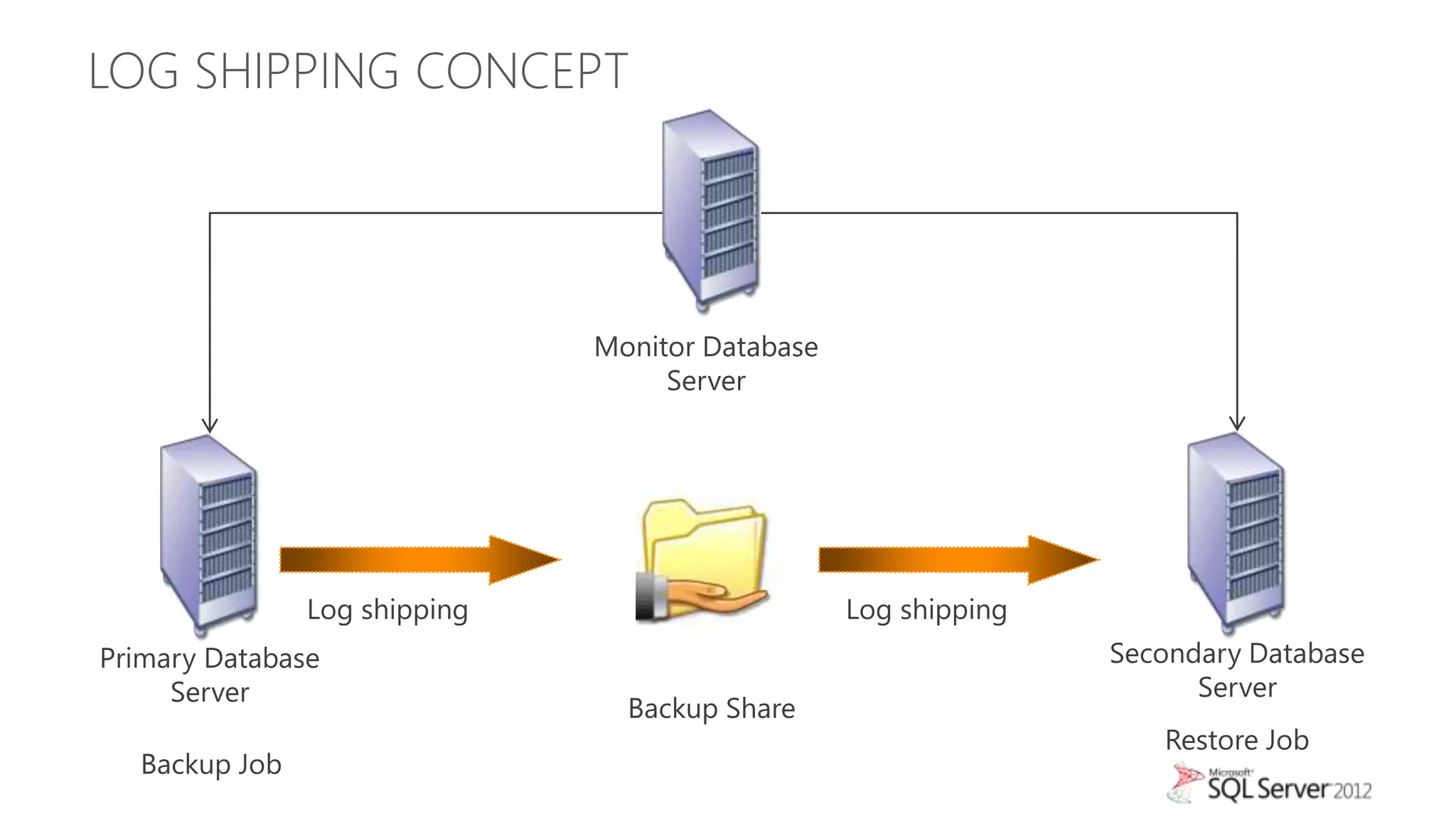


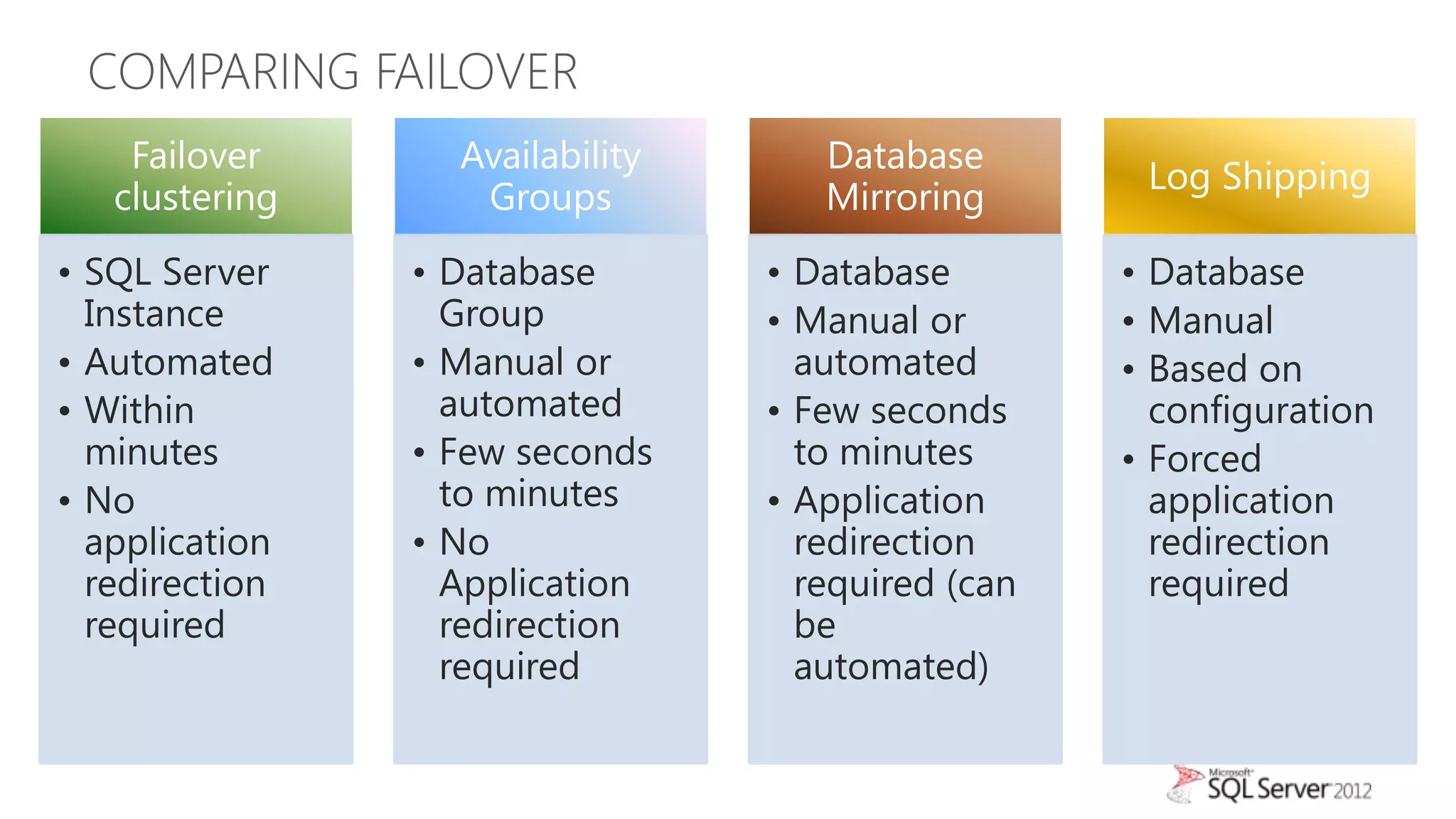

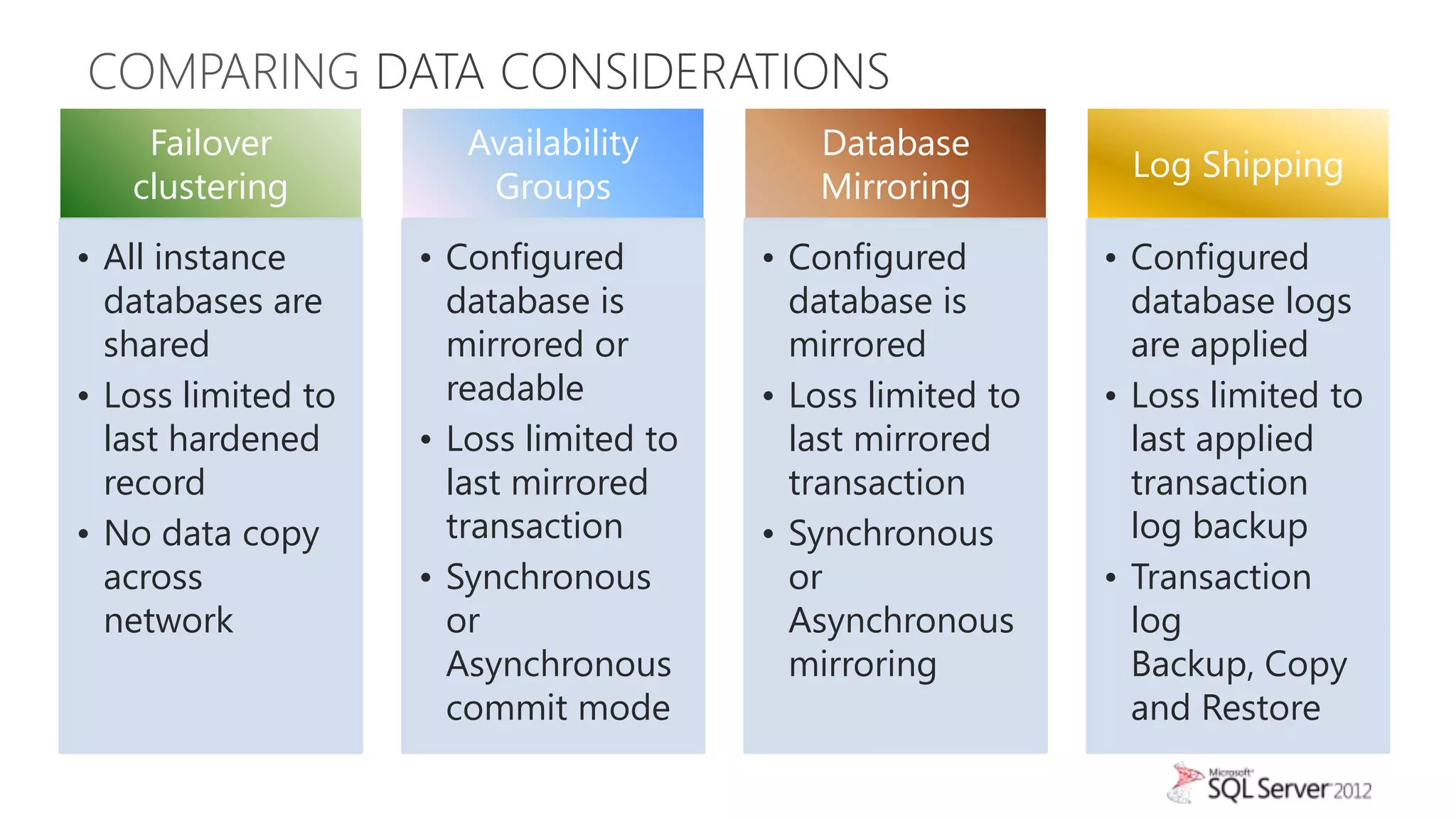
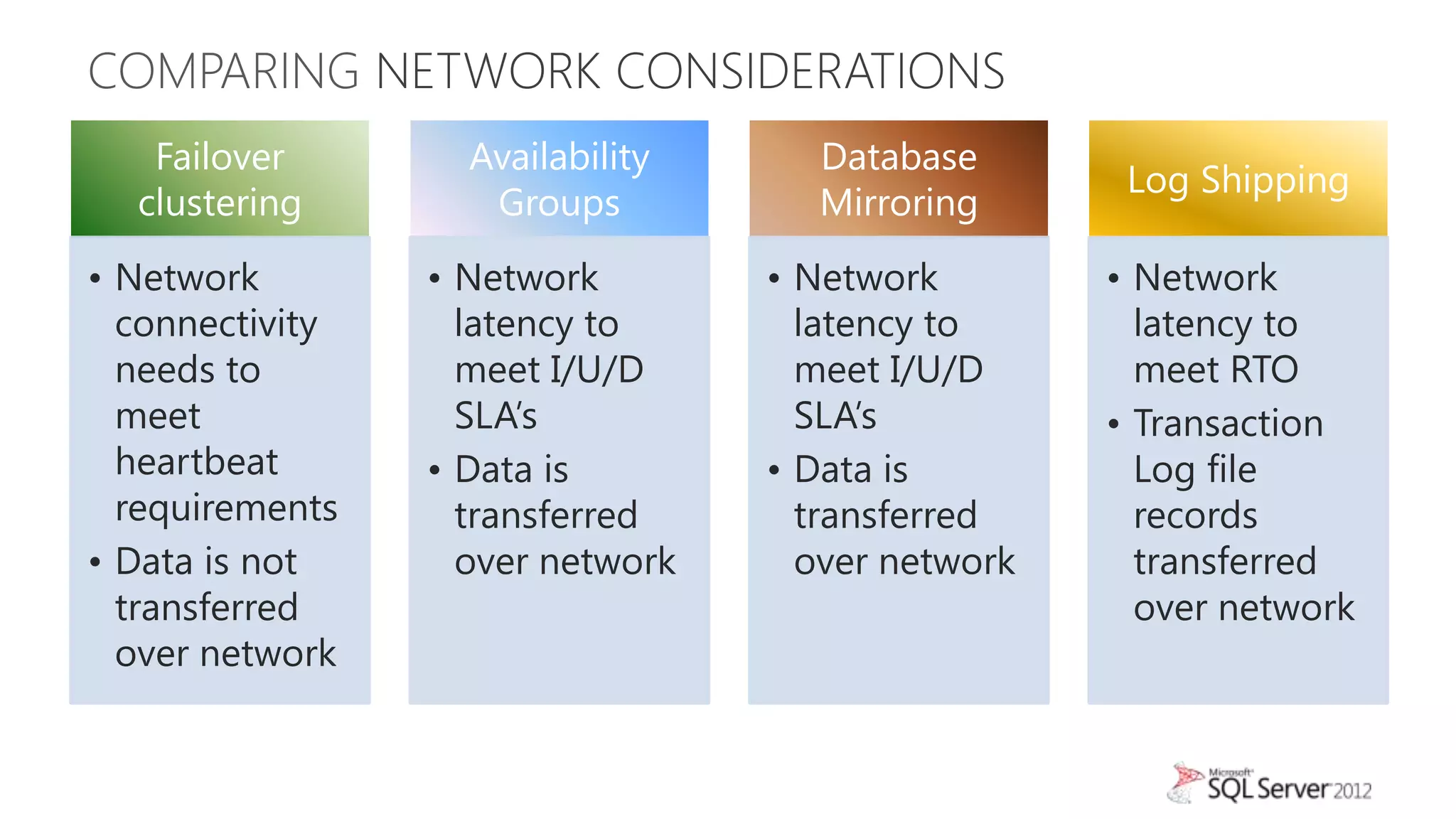



The document summarizes different high availability solutions in SQL Server 2012, including AlwaysOn Failover Cluster Instances, AlwaysOn Availability Groups, and Database Mirroring. It defines key terms like primary/secondary databases and replicas. It also describes the benefits of each solution, such as automatic failover, read-only access on secondaries, and support for different storage options.











































































































