Downloaded 37 times






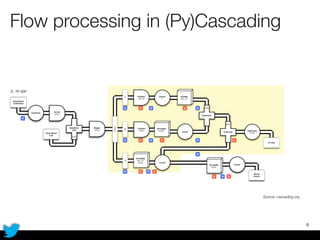
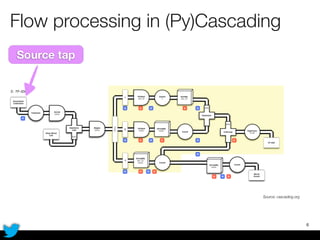
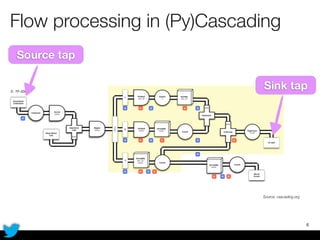
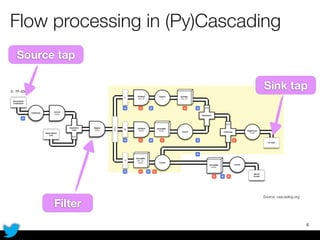
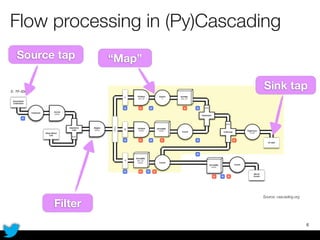
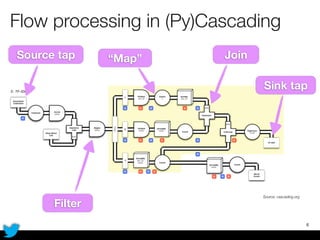
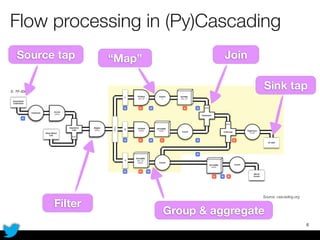

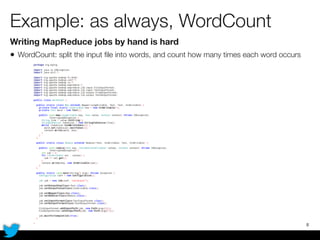
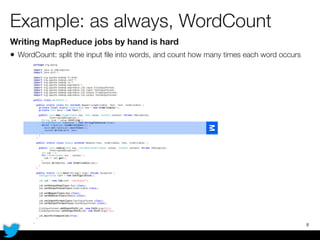
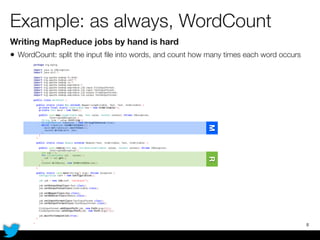
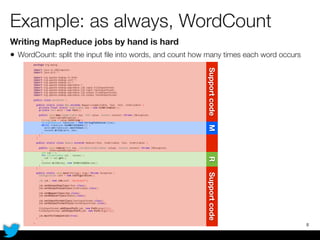

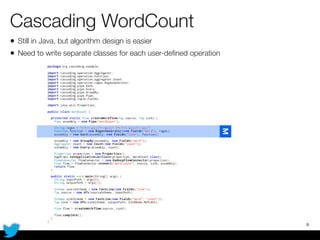
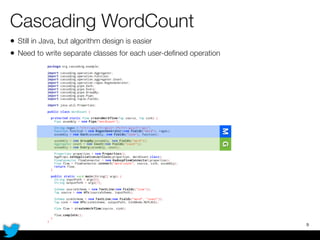










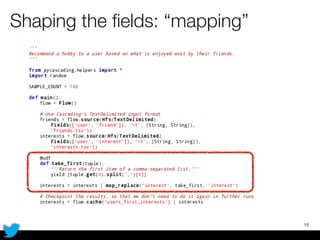
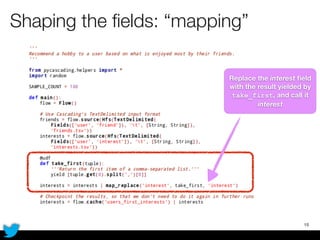
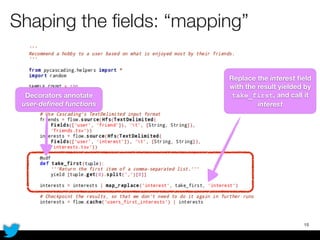
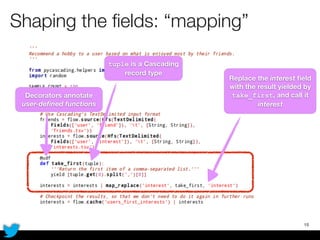
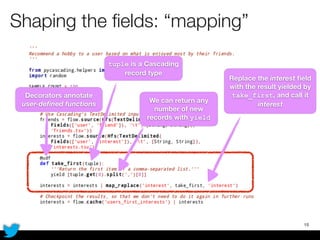

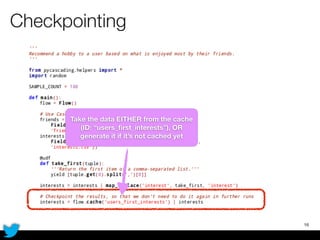















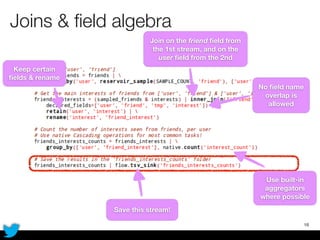








PyCascading provides a Python API for the Cascading framework to process data flows on Hadoop. It allows defining data flows as Python functions and operations instead of Java code. The document discusses Hadoop concepts, shows how to define a WordCount workflow in PyCascading with fewer lines of code than Java, and walks through a full example of finding friends' most common interests. Key advantages are using Python instead of Java and leveraging any Python libraries, though performance-critical parts require Java.






















































































