Downloaded 119 times













![Apache Pig – Elements
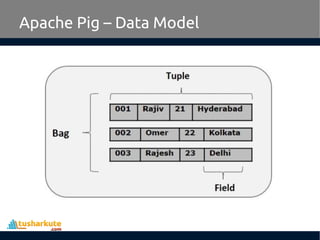
• Relation
– A relation is a bag of tuples. The relations in Pig
Latin are unordered (there is no guarantee that
tuples are processed in any particular order).
• Map
– A map (or data map) is a set of key-value pairs.
The key needs to be of type chararray and should
be unique. The value might be of any type. It is
represented by ‘[]’
– Example: [name#Raja, age#30]](https://image.slidesharecdn.com/pigabigdataprocessor-160306072146/85/Apache-Pig-A-big-data-processor-17-320.jpg)





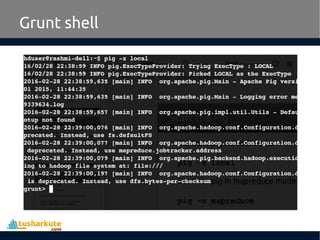


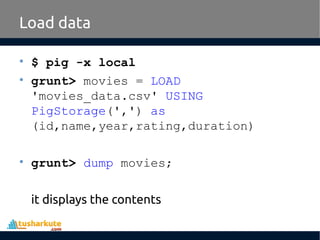

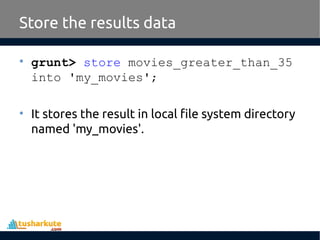








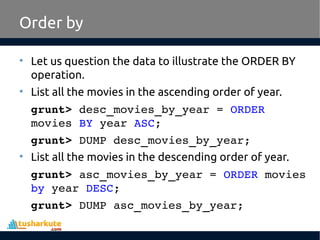




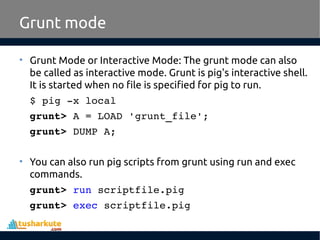


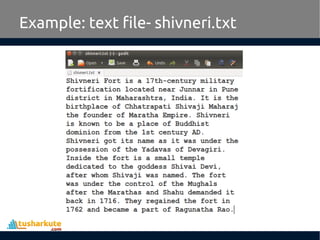

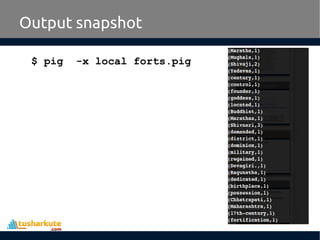



Apache Pig is a high-level platform for analyzing large data sets by providing an abstraction over MapReduce through a scripting language called Pig Latin. It simplifies data manipulation tasks, offers built-in operators for operations like joins and filters, and supports both structured and unstructured data. Developed at Yahoo in 2006 and open-sourced in 2007, Apache Pig has become a vital tool for processing large data sources efficiently.































































![Unit-5 [Pig] working and architecture.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/unit-5pig-240605082042-8125c633-thumbnail.jpg?width=640&height=640&fit=bounds)











































