Downloaded 52 times











![Now let’s sort
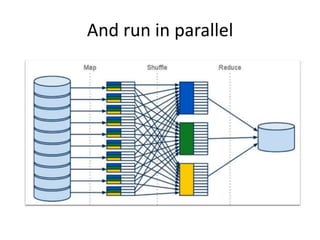
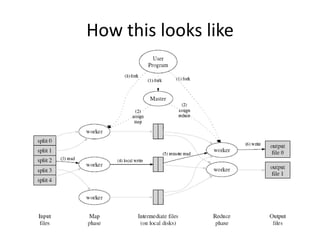
• MapReduce steps can be chained together
• Built-in sort by key is actively exploited
• First example output was sorted by candidate
name, voice count is the value
• Let’s re-sort by voice count and see the leader
– Map(candidate, count)
{Emit(concat(count,candidate), null)}
– Partition(key)
{return get_count(key) div reducers_count;}
– Reduce(key,values[]) { Emit(null) }](https://image.slidesharecdn.com/mapreduceparadigmexplained-131028040300-phpapp02/85/Map-reduce-paradigm-explained-13-320.jpg)

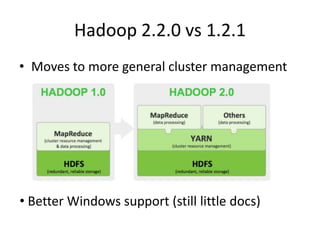





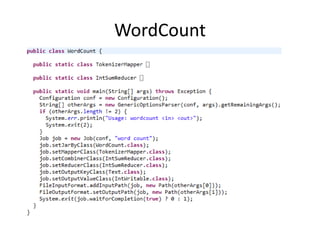





The document provides an overview of MapReduce and how it addresses the problem of processing large datasets in a distributed computing environment. It explains how MapReduce inspired by functional programming works by splitting data, mapping functions to pieces in parallel, and then reducing the results. Examples are given of word count and sorting word counts to find the most frequent word. Finally, it discusses how Hadoop popularized MapReduce by providing an open-source implementation and ecosystem.


































































