Download free for 30 days
Sign in
Upload
Language (EN)
Support
Business
Mobile
Social Media
Marketing
Technology
Art & Photos
Career
Design
Education
Presentations & Public Speaking
Government & Nonprofit
Healthcare
Internet
Law
Leadership & Management
Automotive
Engineering
Software
Recruiting & HR
Retail
Sales
Services
Science
Small Business & Entrepreneurship
Food
Environment
Economy & Finance
Data & Analytics
Investor Relations
Sports
Spiritual
News & Politics
Travel
Self Improvement
Real Estate
Entertainment & Humor
Health & Medicine
Devices & Hardware
Lifestyle
Change Language
Language
English
Español
Português
Français
Deutsche
Cancel
Save
Submit search
EN
Uploaded by
Deep Learning JP
PPTX, PDF
2,066 views
[DL輪読会]モデルベース強化学習とEnergy Based Model
2019/11/29 Deep Learning JP: http://deeplearning.jp/seminar-2/
Technology
◦
Related topics:
Deep Learning
•
Read more
0
Save
Share
Embed
Embed presentation
Download
Downloaded 15 times
1
/ 27
2
/ 27
Most read
3
/ 27
4
/ 27
5
/ 27
6
/ 27
7
/ 27
8
/ 27
9
/ 27
10
/ 27
11
/ 27
12
/ 27
13
/ 27
14
/ 27
15
/ 27
16
/ 27
17
/ 27
18
/ 27
19
/ 27
20
/ 27
21
/ 27
22
/ 27
23
/ 27
24
/ 27
25
/ 27
26
/ 27
27
/ 27
More Related Content
PPTX
【DL輪読会】Transformers are Sample Efficient World Models
by
Deep Learning JP
PPTX
報酬設計と逆強化学習
by
Yusuke Nakata
PPTX
【DL輪読会】ViT + Self Supervised Learningまとめ
by
Deep Learning JP
PDF
[DL輪読会]近年のエネルギーベースモデルの進展
by
Deep Learning JP
PPTX
【DL輪読会】論文解説:Offline Reinforcement Learning as One Big Sequence Modeling Problem
by
Deep Learning JP
PDF
PRML学習者から入る深層生成モデル入門
by
tmtm otm
PDF
[DL輪読会]`強化学習のための状態表現学習 -より良い「世界モデル」の獲得に向けて-
by
Deep Learning JP
PDF
【DL輪読会】Mastering Diverse Domains through World Models
by
Deep Learning JP
【DL輪読会】Transformers are Sample Efficient World Models
by
Deep Learning JP
報酬設計と逆強化学習
by
Yusuke Nakata
【DL輪読会】ViT + Self Supervised Learningまとめ
by
Deep Learning JP
[DL輪読会]近年のエネルギーベースモデルの進展
by
Deep Learning JP
【DL輪読会】論文解説:Offline Reinforcement Learning as One Big Sequence Modeling Problem
by
Deep Learning JP
PRML学習者から入る深層生成モデル入門
by
tmtm otm
[DL輪読会]`強化学習のための状態表現学習 -より良い「世界モデル」の獲得に向けて-
by
Deep Learning JP
【DL輪読会】Mastering Diverse Domains through World Models
by
Deep Learning JP
What's hot
PDF
HiPPO/S4解説
by
Morpho, Inc.
PDF
Transformerを多層にする際の勾配消失問題と解決法について
by
Sho Takase
PPTX
[DL輪読会]Learning Latent Dynamics for Planning from Pixels
by
Deep Learning JP
PDF
強化学習と逆強化学習を組み合わせた模倣学習
by
Eiji Uchibe
PDF
[DL輪読会]Model soups: averaging weights of multiple fine-tuned models improves ...
by
Deep Learning JP
PDF
[DL輪読会]近年のオフライン強化学習のまとめ —Offline Reinforcement Learning: Tutorial, Review, an...
by
Deep Learning JP
PPTX
[DL輪読会]“SimPLe”,“Improved Dynamics Model”,“PlaNet” 近年のVAEベース系列モデルの進展とそのモデルベース...
by
Deep Learning JP
PDF
[DL輪読会]Learning Transferable Visual Models From Natural Language Supervision
by
Deep Learning JP
PPTX
[DL輪読会]World Models
by
Deep Learning JP
PDF
[DL輪読会]NeRF: Representing Scenes as Neural Radiance Fields for View Synthesis
by
Deep Learning JP
PDF
最近強化学習の良記事がたくさん出てきたので勉強しながらまとめた
by
Katsuya Ito
PPTX
【DL輪読会】DiffRF: Rendering-guided 3D Radiance Field Diffusion [N. Muller+ CVPR2...
by
Deep Learning JP
PPTX
[DL輪読会]相互情報量最大化による表現学習
by
Deep Learning JP
PDF
Active Learning 入門
by
Shuyo Nakatani
PPTX
[DL輪読会]Swin Transformer: Hierarchical Vision Transformer using Shifted Windows
by
Deep Learning JP
PDF
方策勾配型強化学習の基礎と応用
by
Ryo Iwaki
PPTX
近年のHierarchical Vision Transformer
by
Yusuke Uchida
PPTX
【DL輪読会】Efficiently Modeling Long Sequences with Structured State Spaces
by
Deep Learning JP
PDF
Domain Adaptation 発展と動向まとめ(サーベイ資料)
by
Yamato OKAMOTO
PPTX
【LT資料】 Neural Network 素人なんだけど何とかご機嫌取りをしたい
by
Takuji Tahara
HiPPO/S4解説
by
Morpho, Inc.
Transformerを多層にする際の勾配消失問題と解決法について
by
Sho Takase
[DL輪読会]Learning Latent Dynamics for Planning from Pixels
by
Deep Learning JP
強化学習と逆強化学習を組み合わせた模倣学習
by
Eiji Uchibe
[DL輪読会]Model soups: averaging weights of multiple fine-tuned models improves ...
by
Deep Learning JP
[DL輪読会]近年のオフライン強化学習のまとめ —Offline Reinforcement Learning: Tutorial, Review, an...
by
Deep Learning JP
[DL輪読会]“SimPLe”,“Improved Dynamics Model”,“PlaNet” 近年のVAEベース系列モデルの進展とそのモデルベース...
by
Deep Learning JP
[DL輪読会]Learning Transferable Visual Models From Natural Language Supervision
by
Deep Learning JP
[DL輪読会]World Models
by
Deep Learning JP
[DL輪読会]NeRF: Representing Scenes as Neural Radiance Fields for View Synthesis
by
Deep Learning JP
最近強化学習の良記事がたくさん出てきたので勉強しながらまとめた
by
Katsuya Ito
【DL輪読会】DiffRF: Rendering-guided 3D Radiance Field Diffusion [N. Muller+ CVPR2...
by
Deep Learning JP
[DL輪読会]相互情報量最大化による表現学習
by
Deep Learning JP
Active Learning 入門
by
Shuyo Nakatani
[DL輪読会]Swin Transformer: Hierarchical Vision Transformer using Shifted Windows
by
Deep Learning JP
方策勾配型強化学習の基礎と応用
by
Ryo Iwaki
近年のHierarchical Vision Transformer
by
Yusuke Uchida
【DL輪読会】Efficiently Modeling Long Sequences with Structured State Spaces
by
Deep Learning JP
Domain Adaptation 発展と動向まとめ(サーベイ資料)
by
Yamato OKAMOTO
【LT資料】 Neural Network 素人なんだけど何とかご機嫌取りをしたい
by
Takuji Tahara
Similar to [DL輪読会]モデルベース強化学習とEnergy Based Model
PPTX
[DL輪読会]Learning to Adapt: Meta-Learning for Model-Based Control
by
Deep Learning JP
PDF
深層学習(講談社)のまとめ(1章~2章)
by
okku apot
PDF
深層学習(岡本孝之 著) - Deep Learning chap.1 and 2
by
Masayoshi Kondo
PPTX
[DL輪読会]Model-Based Reinforcement Learning via Meta-Policy Optimization
by
Deep Learning JP
PDF
Deep directed generative models with energy-based probability estimation
by
Daisuke Yoneoka
PDF
深層強化学習 Pydata.Okinawa Meetup #22
by
Naoto Yoshida
PPTX
強化学習5章
by
hiroki yamaoka
PPTX
深層学習の基礎と導入
by
Kazuki Motohashi
PPTX
miru2020-200727021915200727021915200727021915200727021915.pptx
by
RajSharma11707
PPTX
[DL輪読会]SOLAR: Deep Structured Representations for Model-Based Reinforcement L...
by
Deep Learning JP
PPTX
[DL輪読会]Meta Reinforcement Learning
by
Deep Learning JP
PDF
東大大学院 電子情報学特論講義資料「深層学習概論と理論解析の課題」大野健太
by
Preferred Networks
PDF
[DL輪読会]Energy-based generative adversarial networks
by
Deep Learning JP
PPTX
「機械学習とは?」から始める Deep learning実践入門
by
Hideto Masuoka
DOCX
レポート深層学習Day4
by
ssuser9d95b3
PDF
Jubatusにおける大規模分散オンライン機械学習
by
Preferred Networks
PDF
強化学習@PyData.Tokyo
by
Naoto Yoshida
PDF
Deep learning実装の基礎と実践
by
Seiya Tokui
PPTX
1028 TECH & BRIDGE MEETING
by
健司 亀本
PPTX
[DL輪読会]Deep Dynamics Models for Learning Dexterous Manipulation
by
Deep Learning JP
[DL輪読会]Learning to Adapt: Meta-Learning for Model-Based Control
by
Deep Learning JP
深層学習(講談社)のまとめ(1章~2章)
by
okku apot
深層学習(岡本孝之 著) - Deep Learning chap.1 and 2
by
Masayoshi Kondo
[DL輪読会]Model-Based Reinforcement Learning via Meta-Policy Optimization
by
Deep Learning JP
Deep directed generative models with energy-based probability estimation
by
Daisuke Yoneoka
深層強化学習 Pydata.Okinawa Meetup #22
by
Naoto Yoshida
強化学習5章
by
hiroki yamaoka
深層学習の基礎と導入
by
Kazuki Motohashi
miru2020-200727021915200727021915200727021915200727021915.pptx
by
RajSharma11707
[DL輪読会]SOLAR: Deep Structured Representations for Model-Based Reinforcement L...
by
Deep Learning JP
[DL輪読会]Meta Reinforcement Learning
by
Deep Learning JP
東大大学院 電子情報学特論講義資料「深層学習概論と理論解析の課題」大野健太
by
Preferred Networks
[DL輪読会]Energy-based generative adversarial networks
by
Deep Learning JP
「機械学習とは?」から始める Deep learning実践入門
by
Hideto Masuoka
レポート深層学習Day4
by
ssuser9d95b3
Jubatusにおける大規模分散オンライン機械学習
by
Preferred Networks
強化学習@PyData.Tokyo
by
Naoto Yoshida
Deep learning実装の基礎と実践
by
Seiya Tokui
1028 TECH & BRIDGE MEETING
by
健司 亀本
[DL輪読会]Deep Dynamics Models for Learning Dexterous Manipulation
by
Deep Learning JP
More from Deep Learning JP
PPTX
【DL輪読会】AdaptDiffuser: Diffusion Models as Adaptive Self-evolving Planners
by
Deep Learning JP
PPTX
【DL輪読会】事前学習用データセットについて
by
Deep Learning JP
PPTX
【DL輪読会】 "Learning to render novel views from wide-baseline stereo pairs." CVP...
by
Deep Learning JP
PPTX
【DL輪読会】Zero-Shot Dual-Lens Super-Resolution
by
Deep Learning JP
PPTX
【DL輪読会】BloombergGPT: A Large Language Model for Finance arxiv
by
Deep Learning JP
PPTX
【DL輪読会】マルチモーダル LLM
by
Deep Learning JP
PDF
【 DL輪読会】ToolLLM: Facilitating Large Language Models to Master 16000+ Real-wo...
by
Deep Learning JP
PPTX
【DL輪読会】AnyLoc: Towards Universal Visual Place Recognition
by
Deep Learning JP
PDF
【DL輪読会】Can Neural Network Memorization Be Localized?
by
Deep Learning JP
PPTX
【DL輪読会】Hopfield network 関連研究について
by
Deep Learning JP
PPTX
【DL輪読会】SimPer: Simple self-supervised learning of periodic targets( ICLR 2023 )
by
Deep Learning JP
PDF
【DL輪読会】RLCD: Reinforcement Learning from Contrast Distillation for Language M...
by
Deep Learning JP
PDF
【DL輪読会】"Secrets of RLHF in Large Language Models Part I: PPO"
by
Deep Learning JP
PPTX
【DL輪読会】"Language Instructed Reinforcement Learning for Human-AI Coordination "
by
Deep Learning JP
PPTX
【DL輪読会】Llama 2: Open Foundation and Fine-Tuned Chat Models
by
Deep Learning JP
PDF
【DL輪読会】"Learning Fine-Grained Bimanual Manipulation with Low-Cost Hardware"
by
Deep Learning JP
PPTX
【DL輪読会】Parameter is Not All You Need:Starting from Non-Parametric Networks fo...
by
Deep Learning JP
PDF
【DL輪読会】Drag Your GAN: Interactive Point-based Manipulation on the Generative ...
by
Deep Learning JP
PDF
【DL輪読会】Self-Supervised Learning from Images with a Joint-Embedding Predictive...
by
Deep Learning JP
PPTX
【DL輪読会】Towards Understanding Ensemble, Knowledge Distillation and Self-Distil...
by
Deep Learning JP
【DL輪読会】AdaptDiffuser: Diffusion Models as Adaptive Self-evolving Planners
by
Deep Learning JP
【DL輪読会】事前学習用データセットについて
by
Deep Learning JP
【DL輪読会】 "Learning to render novel views from wide-baseline stereo pairs." CVP...
by
Deep Learning JP
【DL輪読会】Zero-Shot Dual-Lens Super-Resolution
by
Deep Learning JP
【DL輪読会】BloombergGPT: A Large Language Model for Finance arxiv
by
Deep Learning JP
【DL輪読会】マルチモーダル LLM
by
Deep Learning JP
【 DL輪読会】ToolLLM: Facilitating Large Language Models to Master 16000+ Real-wo...
by
Deep Learning JP
【DL輪読会】AnyLoc: Towards Universal Visual Place Recognition
by
Deep Learning JP
【DL輪読会】Can Neural Network Memorization Be Localized?
by
Deep Learning JP
【DL輪読会】Hopfield network 関連研究について
by
Deep Learning JP
【DL輪読会】SimPer: Simple self-supervised learning of periodic targets( ICLR 2023 )
by
Deep Learning JP
【DL輪読会】RLCD: Reinforcement Learning from Contrast Distillation for Language M...
by
Deep Learning JP
【DL輪読会】"Secrets of RLHF in Large Language Models Part I: PPO"
by
Deep Learning JP
【DL輪読会】"Language Instructed Reinforcement Learning for Human-AI Coordination "
by
Deep Learning JP
【DL輪読会】Llama 2: Open Foundation and Fine-Tuned Chat Models
by
Deep Learning JP
【DL輪読会】"Learning Fine-Grained Bimanual Manipulation with Low-Cost Hardware"
by
Deep Learning JP
【DL輪読会】Parameter is Not All You Need:Starting from Non-Parametric Networks fo...
by
Deep Learning JP
【DL輪読会】Drag Your GAN: Interactive Point-based Manipulation on the Generative ...
by
Deep Learning JP
【DL輪読会】Self-Supervised Learning from Images with a Joint-Embedding Predictive...
by
Deep Learning JP
【DL輪読会】Towards Understanding Ensemble, Knowledge Distillation and Self-Distil...
by
Deep Learning JP
Recently uploaded
PDF
安価な ロジック・アナライザを アナライズ(?),Analyze report of some cheap logic analyzers
by
たけおか しょうぞう
PDF
第25回FA設備技術勉強会_自宅で勉強するROS・フィジカルAIアイテム.pdf
by
TomohiroKusu
PDF
基礎から学ぶ PostgreSQL の性能監視 (PostgreSQL Conference Japan 2025 発表資料)
by
NTT DATA Technology & Innovation
PPTX
DrupalCon Nara 2025の記録 .
by
iPride Co., Ltd.
PDF
PCCC25(設立25年記念PCクラスタシンポジウム):東京大学情報基盤センター テーマ1/2/3「Society5.0の実現を目指す『計算・データ・学習...
by
PC Cluster Consortium
PDF
visionOS TC「新しいマイホームで過ごすApple Vision Proとの新生活」
by
Sugiyama Yugo
安価な ロジック・アナライザを アナライズ(?),Analyze report of some cheap logic analyzers
by
たけおか しょうぞう
第25回FA設備技術勉強会_自宅で勉強するROS・フィジカルAIアイテム.pdf
by
TomohiroKusu
基礎から学ぶ PostgreSQL の性能監視 (PostgreSQL Conference Japan 2025 発表資料)
by
NTT DATA Technology & Innovation
DrupalCon Nara 2025の記録 .
by
iPride Co., Ltd.
PCCC25(設立25年記念PCクラスタシンポジウム):東京大学情報基盤センター テーマ1/2/3「Society5.0の実現を目指す『計算・データ・学習...
by
PC Cluster Consortium
visionOS TC「新しいマイホームで過ごすApple Vision Proとの新生活」
by
Sugiyama Yugo
[DL輪読会]モデルベース強化学習とEnergy Based Model
1.
1 DEEP LEARNING JP [DL
Papers] http://deeplearning.jp/ モデルベース強化学習とEnergy Based Model Reiji Hatsugai, DeepX
2.
2 モチベーション • モデルを学習して、それを活かす形で方策を得る、モデルベース強化 学習が最近熱い – PlaNet,
SLAC, MuZeroとか • CoRLの論文を眺めていて、モデルベース強化学習してる論文をいく つか発見 • その中でEnergy Based Modelと絡めて提案していて、Energy Based Modelの使い方が面白い論文が2つあったのでまとめて紹介
3.
書誌情報 • Model-Based Planning
with Energy-Based Models – Yilun Du, Toru Lin, Igor Mordatch, MIT, Google Brain • Regularizing Model-Based Planning with Energy-Based Models – Rinu Boney, Juho Kannala, Alexander Ilin, Aalto Univ • CoRL2019 3
4.
前提知識 • ベーシックな(?)モデルベース強化学習 – モデルの学習 –
モデルの活用方法 • Energy Based Model – 生成モデル 4
5.
モデルの学習 • 状態s_tと行動a_tを受け取り、次状態s_t+1を推定するネットワークの 学習 5
6.
モデルの活用方法:MPC • 行動の系列をランダムにサンプルし、現在の状態からサンプルされた 行動の系列を適用した時にどのような状態系列になるか推定 • 推定された状態系列と、行動系列に対して、報酬関数を適用し、報酬 関数が最大化される行動系列を選択 •
選択された行動系列の最初の一つを実際に起こす行動として選択 6
7.
モデルの活用方法:CEM • MPCの時と同じ目的関数をブラックボックス関数として、Cross Entropy Methodで最適化 –
CEM:行動系列をガウス分布からサンプルし、最適化されるブラックボックス関数の 評価値を取得。取得された値に応じてサンプルする分布を変化させていき、評価値 を向上させる 7
8.
生成モデル • ここでいうエネルギー関数は、正規化されていない対数尤度関数 • 一般に、確率モデルを求める際に、分母の計算は難しい(積分操作を 行なうのが難しい) •
エネルギー関数からサンプルする方法として、MCMCやランジュバン 方程式を使用したものがある 8
9.
Regularizing Model-Based Planning
with Energy-Based Models • モデルベース強化学習の問題:間違ったモデルの推定を元に行動系列 を最適化してしまうことで、現実では全く役に立たない行動を選択し てしまう • この論文では、状態、行動、次状態のトリプレットの対数尤度を報酬 関数に追加 • 報酬関数を最大化しながら、尤度が低い(観測される確率が小さい) モデルの推定を弾くことで、上記問題を解決しようとしている 9
10.
尤度関数からエネルギー関数へ • 対数尤度の分母の項は、行動系列に依存しない値なので、最終的にエ ネルギー関数のみが目的関数の項に残る 10
11.
エネルギー関数の構成方法 • Deep Energy
Estimator Network (DEEN) という手法とDenoising Auto Encoder (DAE) という手法でエネルギー関数の推定を実施 11
12.
実験 • 学習済みモデルを利用したモデル活用方法の比較実験 • モデルの学習を含むゼロからの学習曲線 •
エネルギー関数の効果 12
13.
学習済みモデルを利用したモデル活用方法の比較実験 • PETSの学習で得られたモデルを利用して、モデルの活用方法だけを 表の4種類比較 • 探索方法にCEMを用いて、DEENによってエネルギー関数の追加報酬 を加えたものが一番高い報酬値となった 13
14.
モデルの学習を含むゼロからの学習曲線 • PETS, GPと比較をしている •
比較対象(赤、黄)よりサンプル効率よく学習していることがわかる 14
15.
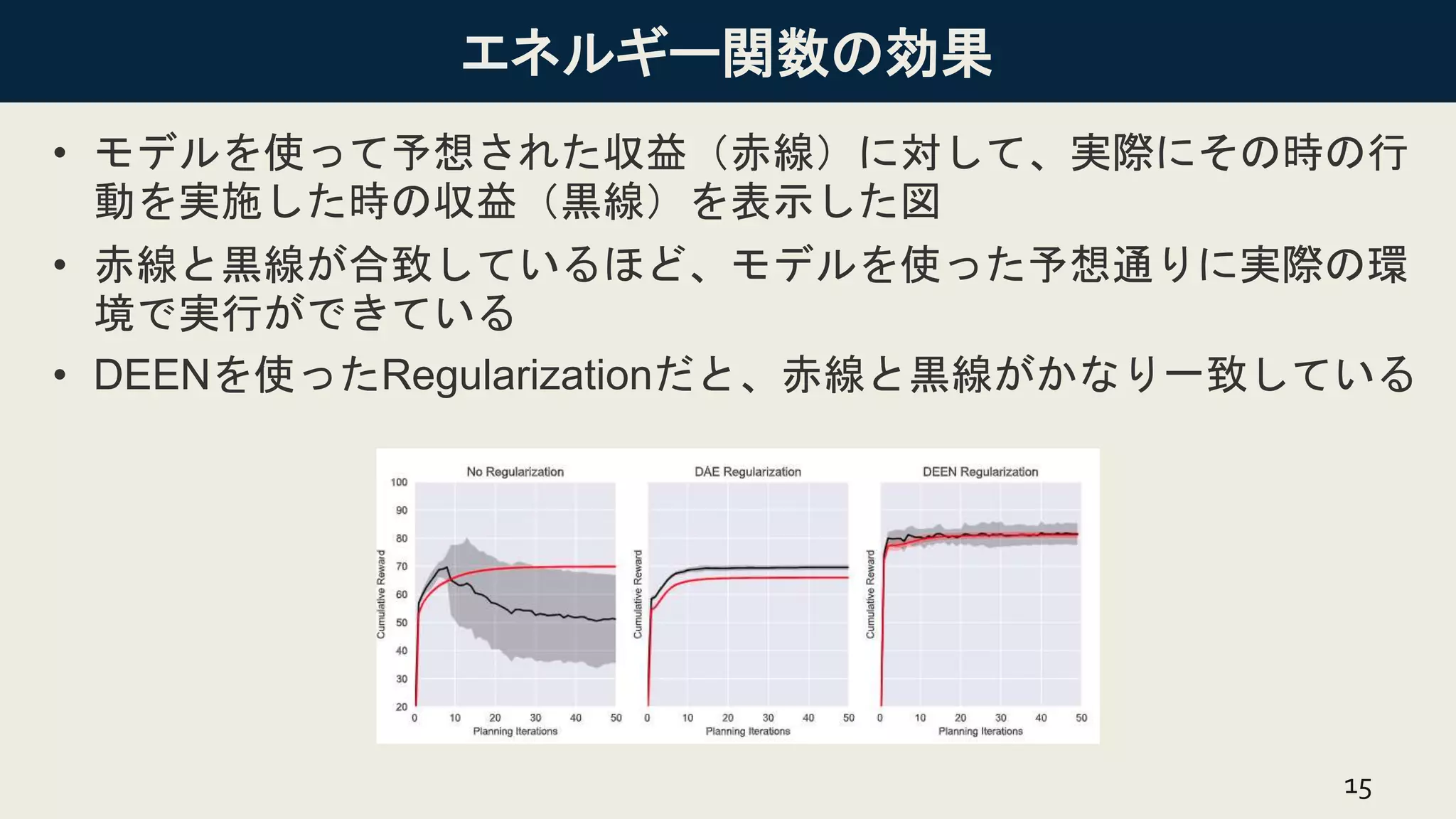
エネルギー関数の効果 • モデルを使って予想された収益(赤線)に対して、実際にその時の行 動を実施した時の収益(黒線)を表示した図 • 赤線と黒線が合致しているほど、モデルを使った予想通りに実際の環 境で実行ができている •
DEENを使ったRegularizationだと、赤線と黒線がかなり一致している 15
16.
Regularizing Model-Based Planning
with Energy-Based Modelsまとめ • 学習済みモデルが存在する時に、エネルギー関数を考えることで、性 能を向上させることができた • フルスクラッチで学習する場合においても、エネルギー関数での Regularizingによって高いサンプル効率で学習が可能ということがわ かった 16
17.
Model-Based Planning with
Energy-Based Models • モデルの学習を陽に行わずに、状態の遷移(状態と次状態のタプル) に関してエネルギー関数を学習し、エネルギー関数を最小化しながら、 最終目的状態との距離も最小化 – エネルギー関数の計算に行動の項は一切入らない。状態に対してのみ – 最終的な行動の選択の際は、状態系列を入力としてそれを達成する行動を出力する ネットワークを用いる 17
18.
エネルギー関数について • 状態のタプルについての正規化されていない対数尤度 • エネルギー関数は、GANのような形で学習され、実際にサンプルされ たデータに対するエネルギーを最小化し、エネルギー関数を用いてサ ンプルされたデータに対するエネルギーを最大化するように学習する 18
19.
MPPI • エネルギー関数からのデータをサンプルする際、MCMCやランジュバ ン方程式を使ったものではなく、重要度重み付けを使ったMPPIを用 いてサンプルを行なう • 一つまえの変数からガウシアンノイズを加えて、エネルギー関数の重 み付けで足し合わせる 19
20.
最終的な目的関数 • 最終状態で目的とする状態に到達することを条件付けることで、下の 確率分布からサンプルされるような状態系列を達成すればよい 20
21.
オンラインでの学習 • 障害物などがある場合、障害物によって進めなかったというデータを 元にオンラインで学習することで、障害物を回避するような新たな状 態系列がサンプリングされるようになる 21
22.
アルゴリズム 22
23.
実験 • 色々やっているので、以下を抜粋 – Energy
Based ModelとActionFF(状態と行動を受け取って次状態を出力する順モデ ル)の比較 – 学習データセットにない障害物に対する対処 23
24.
Energy Based ModelとActionFFの比較 •
Sawyer Arm(7DoFのロボットアーム)で目的の位置に到達させる • モデルを学習させるか、オンライン学習させるかによらず、EBMの方 が良い結果 • 特に、オンライン学習させる時に大幅に改善 24
25.
学習データセットにない障害物に対する対処 • Particle:粒子を目的の位置まで運ぶ • オンライン学習を組み込んだEBMでは、学習時になかった障害物が あったとしても、タスクを成功させた 25
26.
Model-Based Planning with
Energy-Based Modelsまとめ • Energy Based Modelによるプランニングは有望である • オンライン学習の設定を入れることでパフォーマンスを向上させるこ とができた 26
27.
感想 • Regularizing Model-Based
Planning with Energy-Based Models – モデルの不確かさについて、分散等が直接計算できる手法がよく提案されているが、 EBMでうまく表現していて、興味深い – EBMがOODデータに対して高い尤度を持たないという特性によってこれが実現され ているのだと思う • Model-Based Planning with Energy-Based Models – モデルベース強化学習を考える上で、陽にモデルを構築しないというのは面白い発 想だった(ただ、あんまりこの方向で考えすぎると、モデルフリー強化学習に帰着する のでは?) – 著者が謎にオンライン学習押しだったが、どれくらい使えるシチュエーションがあるだ ろうか気になる – あとこの手法はリーチング系以外厳しそう 27
Download
![1
DEEP LEARNING JP
[DL Papers]
http://deeplearning.jp/
モデルベース強化学習とEnergy Based Model
Reiji Hatsugai, DeepX](https://image.slidesharecdn.com/energybasedmodel-191129002008/75/DL-Energy-Based-Model-1-2048.jpg)





























![[DL輪読会]近年のエネルギーベースモデルの進展](https://cdn.slidesharecdn.com/ss_thumbnails/energybasedmodel-200124020855-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DL輪読会]`強化学習のための状態表現学習 -より良い「世界モデル」の獲得に向けて-](https://cdn.slidesharecdn.com/ss_thumbnails/20181026staterepresenration-181127055206-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DL輪読会]Learning Latent Dynamics for Planning from Pixels](https://cdn.slidesharecdn.com/ss_thumbnails/taniguchi20181221-190104064850-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会]Model soups: averaging weights of multiple fine-tuned models improves ...](https://cdn.slidesharecdn.com/ss_thumbnails/dl0401-220405031053-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]近年のオフライン強化学習のまとめ —Offline Reinforcement Learning: Tutorial, Review, an...](https://cdn.slidesharecdn.com/ss_thumbnails/20200626journalclubpub-200630064755-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]“SimPLe”,“Improved Dynamics Model”,“PlaNet” 近年のVAEベース系列モデルの進展とそのモデルベース...](https://cdn.slidesharecdn.com/ss_thumbnails/20190426akuzawa-190426020057-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]Learning Transferable Visual Models From Natural Language Supervision](https://cdn.slidesharecdn.com/ss_thumbnails/dlkobayashi0115-210115012308-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]World Models](https://cdn.slidesharecdn.com/ss_thumbnails/20180427-180427003856-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]NeRF: Representing Scenes as Neural Radiance Fields for View Synthesis](https://cdn.slidesharecdn.com/ss_thumbnails/nerfdlseminar1-200327021512-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DL輪読会]相互情報量最大化による表現学習](https://cdn.slidesharecdn.com/ss_thumbnails/20190913iwasawa-190913002312-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会]Swin Transformer: Hierarchical Vision Transformer using Shifted Windows](https://cdn.slidesharecdn.com/ss_thumbnails/swintransformer-210514020542-thumbnail.jpg?width=640&height=640&fit=bounds)





![[DL輪読会]Learning to Adapt: Meta-Learning for Model-Based Control](https://cdn.slidesharecdn.com/ss_thumbnails/20180511dl-180511004107-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DL輪読会]Model-Based Reinforcement Learning via Meta-Policy Optimization](https://cdn.slidesharecdn.com/ss_thumbnails/model-basedreinforcementlearningviameta-policyoptimization-190705000247-thumbnail.jpg?width=640&height=640&fit=bounds)





![[DL輪読会]SOLAR: Deep Structured Representations for Model-Based Reinforcement L...](https://cdn.slidesharecdn.com/ss_thumbnails/20190816-190816001737-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]Meta Reinforcement Learning](https://cdn.slidesharecdn.com/ss_thumbnails/metarl-190201005548-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会]Energy-based generative adversarial networks](https://cdn.slidesharecdn.com/ss_thumbnails/energy-basedgenerativeadversarialnetworks-171030102253-thumbnail.jpg?width=640&height=640&fit=bounds)






![[DL輪読会]Deep Dynamics Models for Learning Dexterous Manipulation](https://cdn.slidesharecdn.com/ss_thumbnails/dljpdeepdynamicsmodelsforlearningdexterousmanipulation-191011001618-thumbnail.jpg?width=640&height=640&fit=bounds)

























