Distributed system unit II according to syllabus of RGPV, Bhopal
•Download as DOCX, PDF•
8 likes•4,783 views

Distributed Share Memory And Distributed File System Basic Concept of Distributed Share Memory (DSM), DSM Architecture & its Types, Design & Implementations issues In DSM System, Structure of Share Memory Space, Consistency Model, and Thrashing. Desirable features of good Distributed File System, File Model, File Service Architecture, File Accessing Model, File Sharing Semantics, File Catching Scheme, File Application & Fault tolerance. Naming: - Features, System Oriented Names, Object Locating Mechanism, Human Oriented Name.

More Related Content
What's hot
What's hot (20)
Viewers also liked
Viewers also liked (11)
Similar to Distributed system unit II according to syllabus of RGPV, Bhopal
Similar to Distributed system unit II according to syllabus of RGPV, Bhopal (20)
More from NANDINI SHARMA
More from NANDINI SHARMA (20)
Recently uploaded
Recently uploaded (20)
Distributed system unit II according to syllabus of RGPV, Bhopal
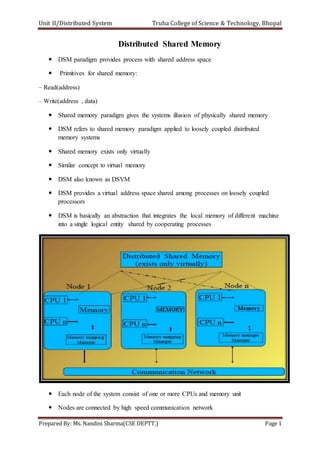
- 1. Unit II/Distributed System Truba College of Science & Technology, Bhopal Prepared By: Ms. Nandini Sharma(CSE DEPTT.) Page 1 Distributed Shared Memory DSM paradigm provides process with shared address space Primitives for shared memory: – Read(address) – Write(address , data) Shared memory paradigm gives the systems illusion of physically shared memory DSM refers to shared memory paradigm applied to loosely coupled distributed memory systems Shared memory exists only virtually Similar concept to virtual memory DSM also known as DSVM DSM provides a virtual address space shared among processes on loosely coupled processors DSM is basically an abstraction that integrates the local memory of different machine into a single logical entity shared by cooperating processes Each node of the system consist of one or more CPUs and memory unit Nodes are connected by high speed communication network
- 2. Unit II/Distributed System Truba College of Science & Technology, Bhopal Prepared By: Ms. Nandini Sharma(CSE DEPTT.) Page 2 Simple message passing system for nodes to exchange information Main memory of individual nodes is used to cache pieces of shared memory space Memory mapping manager routine maps local memory to shared virtual memory Shared memory of DSM exist only virtually Shared memory space is partitioned into blocks Data caching is used in DSM system to reduce network latency The basic unit of caching is a memory block The missing block is migrate from the remote node to the client process’s node and operating system maps into the application’s address space Data block keep migrating from one node to another on demand but no communication is visible to the user processes If data is not available in local memory network block fault is generated. Designand implementation issues Granularity Structure of Shared memory Memory coherence and access synchronization Data location and access Replacement strategy Thrashing Heterogeneity Granularity: Granularity refers to the block size of DSM The unit of sharing and the unit of data transfer across the network when a network block fault occurs Possible unit are a few word , a page or a few pages Structure of Shared memory: Structure refers to the layout of the shared data in memory Dependent on the type of applications that the DSM system is intended to support
- 3. Unit II/Distributed System Truba College of Science & Technology, Bhopal Prepared By: Ms. Nandini Sharma(CSE DEPTT.) Page 3 Memory coherence and access synchronization: In a DSM system that allows replication of shared data item, copies of shared data item may simultaneously be available in the main memories of a number of nodes To solve the memory coherence problem that deal with the consistency of a piece of shared data lying in the main memories of two or more nodes Data location and access: To share data in a DSM, should be possible to locate and retrieve the data accessed by a user process. Replacement strategy: If the local memory of a node is full, a cache miss at that node implies not only a fetch of accessed data block from a remote node but also a replacement Data block must be replaced by the new data block Thrashing: Data block migrate between nodes on demand. Therefore if two nodes compete for write access to a single data item the corresponding data block may be transferred back. Heterogeneity: The DSM system built for homogeneous system need not address the heterogeneity issue Granularity Most visible parameter in the design of DSM system is block size Factors influencing block size selection: Sending large packet of data is not much more expensive than sending small ones Paging overhead: A process is likely to access a large region of its shared address space in a small amount of time Therefore the paging overhead is less for large block size as compared to the paging overhead for small block size Directory size: The larger the block size, the smaller the directory Ultimately result in reduced directory management overhead for larger block size
- 4. Unit II/Distributed System Truba College of Science & Technology, Bhopal Prepared By: Ms. Nandini Sharma(CSE DEPTT.) Page 4 Thrashing: The problem of thrashing may occur when data item in the same data block are being updated by multiple node at the same time Problem may occur with any block size, it is more likely with larger block size False sharing: Occur when two different processes access two unrelated variable that reside in the same data block The larger is the block size the higher is the probability of false sharing False sharing of a block may lead to a thrashing problem Using page size as block size: Relative advantage and disadvantages of small and large block size make it difficult for DSM designer to decide on a proper block size Following advantage: It allows the use of existing page fault schemes to trigger a DSM page fault It allows the access right control Page size do not impose undue communication overhead at the time of network page fault Page size is a suitable data entity unit with respect to memory contention Structure of shared-memory space Structure defines the abstract view of the shared memory space The structure and granularity of a DSM system are closely related
- 5. Unit II/Distributed System Truba College of Science & Technology, Bhopal Prepared By: Ms. Nandini Sharma(CSE DEPTT.) Page 5 Three approach: No structuring Structuring by data type Structuring as a database No structuring: The shared memory space is simply a linear array of words Advantage: Choose any suitable page size as the unit of sharing and a fixed grain size may be used for all application Simple and easy to design such a DSM system Structuring by data type: The shared memory space is structured either as a collection of variables in the source language The granularity in such DSM system is an object or a variable DSM system use variable grain size to match the size of the object/variable being accessed by the application Structuring as a database: Structure the shared memory like a database Shared memory space is ordered as an associative memory called tuple space To perform update old data item in the DSM are replaced by new data item Processes select tuples by specifying the number of their fields and their values or type Access to shared data is nontransparent. Most system they are transparent Consistency Models Consistency requirement vary from application to application A consistency model basically refers to the degree of consistency that has to be maintained for the shared memory data Defined as a set of rules that application must obey if they want the DSM system to provide the degree of consistency guaranteed by the consistency model
- 6. Unit II/Distributed System Truba College of Science & Technology, Bhopal Prepared By: Ms. Nandini Sharma(CSE DEPTT.) Page 6 If a system support the stronger consistency model then the weaker consistency model is automatically supported but the converse is not true Consistency Models Types: Strict Consistency model Sequential Consistency model Causal consistency model Pipelined Random Access Memory consistency model(PRAM) Processor Consistency model Weak consistency model Release consistency model Strict consistency model This is the strongest form of memory coherence having the most stringent consistency requirement Value returned by a read operation on a memory address is always same as the value written by the most recent write operation to that address All writes instantaneously become visible to all processes Implementation of the strict consistency model requires the existence of an absolute global time Absolute synchronization of clock of all the nodes of a distributed system is not possible Implementation of strict consistency model for a DSM system is practically impossible If the three operations read(r1), write(w1), read(r2) are performed on a memory location in that order Only acceptable ordering for a strictly consistency memory is (r1, w1, r2) Sequential Consistency model Proposed by Lamport [1979] A shared memory system is said to support the sequential consistency model if all processes see the same order Exact order of access operations are interleaved does not matter If the three operations read(r1), write(w1), read(r2) are performed on a memory location in that order
- 7. Unit II/Distributed System Truba College of Science & Technology, Bhopal Prepared By: Ms. Nandini Sharma(CSE DEPTT.) Page 7 Any of the orderings (r1, w1, r2), (r1, r2, w1), (w1, r1, r2), (w1, r2, r1), (r2, r1, w1), (r2, w1, r1) is acceptable provided all processes see the same ordering The consistency requirement of the sequential consistency model is weaker than that of the strict consistency model A sequentially consistency memory provide one-copy /single-copy semantics sequentially consistency is acceptable by most applications Causal Consistency Model Proposed by Hutto and Ahamad (1990) All processes see only those memory reference operations in the correct order that are potentially causally related Memory reference operations not related may be seen by different processes in different order Memory reference operation is said to be related to another memory reference operation if one might have been influenced by the other Maintaining dependency graphs for memory access operations Pipelined Random Access Memory Consistency model Proposed by Lipton and Sandberg (1988) Provides a weaker consistency semantics than the consistency model described so far Ensures that all write operations performed by a single process are seen by all other processes in the order in which they were performed All write operations performed by a single process are in a pipeline Write operations performed by different processes can be seen by different processes in different order If w11 and w12 are two write operations performed by a process P1 in that order, and w21 and w22 are two write operations performed by a process P2 in that order A process P3 may see them in the order [(w11,w12), (w21,w22)] and another process P4 may see them in the order [(w21,w22), (w11,w12)] Simple and easy to implement and also has good performance PRAM consistency all processes do not agree on the same order of memory reference operations Processor consistency model Proposed by Goodman [1989] Very similar to PRAM model with additional restriction of memory coherence Memory coherence means that for any memory location all processes agree on the same order of all write operations performed on the same memory location (no matter by which process they are performed) are seen by all processes in the same order If w12 and w22 are write operations for writing the same memory location x, all processes must see them in the same order- w12 before w22 or w22 before w12
- 8. Unit II/Distributed System Truba College of Science & Technology, Bhopal Prepared By: Ms. Nandini Sharma(CSE DEPTT.) Page 8 Processes P3 and P4 must see in the same order, which may be either [(w11,w12), (w21,w22)] or [(w21,w22), (w11,w12)] Weak consistency model Proposed by Dubois [1988] Common characteristics to many application: 1 It is not necessary to show the change in memory done by every write operation to other processes eg. when a process executes in a critical section 2 Isolated accesses to shared variable are rare Better performance can be achieved if consistency is enforced on a group of memory reference operations rather than on individual memory reference operations. DSM system that support the weak consistency model uses a special variable called a synchronization variable . Requirements 1. All accesses to synchronization variables must obey sequential consistency semantics 2. All previous write operations must be completed everywhere before an access to a synchronization variable is allowed 3. All previous accesses to synchronization variables must be completed before access to a non synchronization variable is allowed 4. All previous data access operations performed by a process must be completed successfully before a release access done by the process is allowed A variation of release consistency is lazy release consistency proposed by Keleher [1992] Implementing sequential consistency model Most commonly used model Protocols for implementing the sequential consistency model in the DSM system depend to a great extent on whether the DSM system allows replication and/or migration of shared memory data blocks Strategies: Nonreplicated, Nonmigrating blocks (NRNMB) Nonreplicated, migrating blocks (NRMB) Replicated, migrating blocks (RMB) Replicated, Nonmigrating blocks (RNMB)
- 9. Unit II/Distributed System Truba College of Science & Technology, Bhopal Prepared By: Ms. Nandini Sharma(CSE DEPTT.) Page 9 NRNMBs Simplest strategy for implementing a sequentially consistency DSM system Each block of the shared memory has a single copy whose location is always fixed Enforcing sequential consistency is simple in this case Method is simple and easy to implement and suffers following drawback: Serializing data access creates a bottleneck Parallelism, which is a major advantage of DSM is not possible with this method Data locating in the NRNMB strategy There is a single copy of each block in the entire system The location of a block never changes Hence use Mapping Function Each block of the shared memory has a single copy in the entire system In this strategy only the processes executing on one node can read or write a given data item at any one time and ensures sequential consistency
- 10. Unit II/Distributed System Truba College of Science & Technology, Bhopal Prepared By: Ms. Nandini Sharma(CSE DEPTT.) Page 10 Advantage : No communications cost are incurred when a process accesses data currently held locally It allows the applications to take advantage of data access locality Drawbacks: It is prone to thrashing problem The advantage of parallelism cannot be availed in this method also Data locating in the NRMB strategy There is a single copy of each block, the location of a block keeps changing dynamically Following method used : 1. Broadcasting 2. Centralized server algorithm 3. Fixed distributed server algorithm 4. Dynamic distributed server algorithm Broadcasting Each node maintains an owned blocks table that contains an entry for each block for which the node is the current owner When a fault occurs , the fault handler of the faulting node broadcasts a read/write request on the network
- 11. Unit II/Distributed System Truba College of Science & Technology, Bhopal Prepared By: Ms. Nandini Sharma(CSE DEPTT.) Page 11 Disadvantage: It does not scale well Centralized server algorithm A centralized server maintains a block table that contains the location information for all block in the shared memory space Drawback: A centralized server serializes location queries, reducing parallelism The failure of the centralized server will cause the DSM system to stop functioning Scheme is a direct extension of the centralized server scheme
- 12. Unit II/Distributed System Truba College of Science & Technology, Bhopal Prepared By: Ms. Nandini Sharma(CSE DEPTT.) Page 12 It overcomes the problems of the centralized server scheme by distributing the role of the centralized server Whenever a fault occurs, the mapping functions is used by the fault handler of the faulting node to find out the node whose block manager is mapping the currently accessed block Does not use any block manager and attempts to keep track of the ownership information of all block in each node Each node has a block table that contains the ownership information for all block A field gives the node a hint on the location of the owner of a block and hence is called the probable owner When fault occurs, the faulting node extracts from its block table the node information Replicated, migrating blocks A major disadvantage of the non replication strategies is lack of parallelism To increase parallelism, virtually all DSM system replicate blocks Replication tends to increase the cost of write operation because for a write to a block all its replica must be invalidated or updated to maintain consistency If the read/write ratio is large, the extra expense for the write operation may be more than offset by the lower average cost of the read operation
- 13. Unit II/Distributed System Truba College of Science & Technology, Bhopal Prepared By: Ms. Nandini Sharma(CSE DEPTT.) Page 13 Two basic protocols that may be used for ensuring sequential consistency in this case are: write-invalidate: When a write fault occurs fault handler copies the accessed block If one of the nodes that had a copy of the block before invalidation tries to perform a memory access operation (read/write) on the block after invalidation, a cache miss will occur and the fault handler of that node will have to fetch the block again from a node having a valid copy of the block, therefore the scheme achieves sequential consistency Write-update A write operation is carried out by updating all copies of the data on which the write is perform When write fault occurs the fault handler copies the accessed block from one of the block’s current node to its owe node The write operation completes only after all the copies of the block have been successfully updated Sequentially consistency can be achieved by using a mechanism to totally order the write operations of all the node The intended modification of each write operation is first sent to the global sequencer
- 14. Unit II/Distributed System Truba College of Science & Technology, Bhopal Prepared By: Ms. Nandini Sharma(CSE DEPTT.) Page 14 Sequence number to the modification and multicasts the modification with this sequence number to all the nodes where a replica of the data block to be modified is located The write operations are processed at each node in sequence number order If the verification fails, node request the sequencer for a retransmission of the missing modification Write-update approach is very expensive In write-invalidate approach, updates are only propagated when data are read and several updates can take place before communication is necessary
- 15. Unit II/Distributed System Truba College of Science & Technology, Bhopal Prepared By: Ms. Nandini Sharma(CSE DEPTT.) Page 15 Read request: If there is a local block containing the data and if it is valid, the request is satisfied by accessing the local copy of data Otherwise, the fault handler of the requesting node generates a read fault Write request: If there is a local block containing the data and if it is valid and writable, the request is immediately satisfied by accessing the local copy of the data Otherwise, the fault handler of the requesting node generates a write fault and obtain a valid copy of the block Data Locating in the RMB strategy Data-locating issues are involved in the write-invalidate protocol used with the RMB strategy: 1. Locating the owner of a block, the most recent node to have write access to it 2. Keeping track of the node that are currently have a valid copy of the block Following algorithms may be used: 1. Broadcasting 2. Centralized-server algorithm 3. Fixed distributed-server algorithm 4. Dynamic distributed-server algorithm Replacement strategy In DSM system that allow shared memory block to be dynamically migrated/replicated Following issue: 1. Which block should be replaced to make space for a newly required block? 2. Where should the replaced block be placed? Which block to replace Classification of replacement algorithms: 1. Usage based verses non-usage based 2. Fixed space verses variable space
- 16. Unit II/Distributed System Truba College of Science & Technology, Bhopal Prepared By: Ms. Nandini Sharma(CSE DEPTT.) Page 16 Usage based verses non-usage based: 1. Uses based algorithms keep track of the history of usage of a cache line and use this information to make replacement decisions eg. LRU algorithm 2. Non-usage-based algorithms do not take the record of use of cache lines into account when doing replacement. First in first out and Random (random or pseudorandom) belong to this class Fixed space versus variable space: Fixed-space algorithms assume that the cache size is fixed while variable space algorithm are based on the assumption that the cache size can be changed dynamically depending on the need In a variable space algorithm, a fetch does not imply a replacement, and a swap-out can take place without a corresponding fetch Variable space algorithms are not suitable for a DSM system In DSM system of IVY, each memory block of a node is classified into one of the following five types: 1. Unused: a free memory block that is not currently being used 2. Nil: a block that has been invalidated 3. Read-only: a block for which the node has only read access right 4. Read-owned: a block for which the node has only read access right but is also the owner of the block 5. Writable: a block for which the node has write access permission Based on this classification of block, priority is used: 1. Both unused and nil block have the highest replacement priority 2. The read-only block have the next replacement priority 3. Read-owned and writable block for which replica(s) exist on some other node(s) have the next replacement priority 4. Read-owned and writable block for which only this node has a copy have the lowest replacement priority Where to place a replaced block Once a memory block has been selected for replacement, it should be ensured that if there is some useful information in the block , it should not be lost.
- 17. Unit II/Distributed System Truba College of Science & Technology, Bhopal Prepared By: Ms. Nandini Sharma(CSE DEPTT.) Page 17 The two commonly used approaches for storing a useful block as follow: Using secondary store: The block is simply transferred on to a local disc. Advantages: it does not waste any memory space Using the memory space of other nodes: It may be faster to transfer a block over the network than to transfer it to a local disc. Methods require each node to maintain a table of free memory space in all other nodes. Thrashing Thrashing is said to occur when the system spends a large amount of time transferring shared data blocks from one node to another Thrashing may occur in following situation: 1. When interleaved data accesses made by processes on two or more nodes 2. When blocks with read only permissions are repeatedly invalidated soon after they are replicated Thrashing degrades system performance considerably Methods for solving Thrashing problems: Providing application controlled locks. locking data to prevent other node from accessing that data for a short period of time can reduce Thrashing. Nailing a block to a node for a minimum amount of time disallow a block to a be taken away from a node until a minimum amount of time t elapses after its allocation to that node. Drawback: It is very difficult to choose the appropriate value for the time. Other approaches to DSM There are three main approaches for designing a DSM system 1. Data caching managed by the operating system 2. Data caching managed by MMU hardware 3. Data caching managed by the language runtime system
- 18. Unit II/Distributed System Truba College of Science & Technology, Bhopal Prepared By: Ms. Nandini Sharma(CSE DEPTT.) Page 18 In the first approach each node has its own memory and access to a word in another nodes memory causes a trap to the operating system then fetches and acquires the page. The second approach is to manage caching by MMU 1. Used in multiprocessors having hardware caches 2. DSM implementation is done either entirely or mostly in hardware The third approach is manage caching by language runtime system 1. The DSM is structured not as a raw linear memory of bytes from zero to total size of the combined memory of all machine 2. Placement and migration of shared variables/objects are handled by the language runtime system in cooperation with the operating system. 3. Advantage :Programming language may be provided with features to allow programmers to specify the uses patterns of shared variables/objects for their application Heterogeneous DSM A heterogeneous computing environment allow the applications to exploit the best of all characteristics features of several different types of computers. Measurements made on their experimental prototype heterogeneous DSM, called Mermaid. Heterogeneous DSM is not only feasible but can also be comparable in performance to its homogeneous counterpart The two issues in building a DSM system: Data conversion and selection of block size Machines of different architecture may used different bytes ordering and floating point representation. Structuring the DSM systemas a collection of source language objects It is structured as a collection of variables or object so that the unit of data migration is an object instead of a block A suitable conversion runtime is used to translate the object before migrating its to requesting node. This method of data conversion is used in the Agora shared memory system. Array may easily be too large to be treated as unit of sharing and data migration.
- 19. Unit II/Distributed System Truba College of Science & Technology, Bhopal Prepared By: Ms. Nandini Sharma(CSE DEPTT.) Page 19 Allowing only one type of data in a block This mechanism is used in Mermaid which uses a page size as its block size therefore , a page can contain only one type of data. Whenever a page is moved between two machines of different architecture, a routine converts the data in the page to the appropriate format Limitations : Allowing a page to content data of only one type may lead to wastage of memory due to fragmentation, resulting increased paging activity Compilers used of different types of machine must be compatible Another problem that entire pages are converted even thought only a small portion may be accessed before it is transferred away The mechanism is not fully transparent Another serious problem associated, accuracy of floating point value in numerical applications Block size selection In the Homogeneous DSM system, the block size is usually the same size as a native virtual memory (VM) MMU hardware can be used to trigger a DSM block fault. In heterogeneous, the virtual memory page size may be different for machine of different types. Block size selection become a complicated task Following algorithm for block size selection: 1. Largest page size algorithm 2. Smallest page size algorithm 3. Intermediate page size algorithm In this method the DSM block size is taken as the largest VM page size of all machines Algorithm suffers from the same false sharing and thrashing problem The DSM block size is taken as the smallest VM page size of all machines
- 20. Unit II/Distributed System Truba College of Science & Technology, Bhopal Prepared By: Ms. Nandini Sharma(CSE DEPTT.) Page 20 This algorithm reduced data contention, its suffer from the increase communication and block table management over heads. To balance between the problem of large and small size blocks a heterogeneous DSM system, choose largest VM page size and smallest VM page size Advantage of DSM Simpler Abstraction: The shared memory programming paradigm shields the application programmers from many such low level concern Advantage: It is simple abstraction its provide to the application programmers of loosely coupled distributed memory machine. Better portability of distributed application programs: The access protocol used in case of DSM is consistent with the way sequential application access data this allows for a more natural transition from sequential to distributed application. Better performance of some application: The performance of application that use DSM is expected to worse then if they use message passing directly Not always true, and it found that sub application using DSM can even out perform their message passing counterparts This is possible for three reasons Locality of data : the computation model of DSM is to make the data more accessible by moving it around Ultimately results in reduce overall communication cost for such application On demand data moment: The computation data modeled of DSM also facilitates on demand moment of data as they are being accessed Time needed for the data exchange phase is often dictated by the throughput of existing communication bottlenecks On demand data movements facility provided by DSM eliminates the data exchange phase
- 21. Unit II/Distributed System Truba College of Science & Technology, Bhopal Prepared By: Ms. Nandini Sharma(CSE DEPTT.) Page 21 Large memory space: DSM facility, the total memory size is the sum of the memory size of all the nodes in the system Paging and swapping activities, which involve disk access, are greatly reduced Flexible communication environment The message passing paradigm requires recipients identification and coexistence of the sender and receiver processes The shard memory paradigm of DSM provides a more flexible communication environment in which the sender process need not specify the identity of the receiver processes of data Ease of process migration Migration of a process from one node to another in a distributed system to be tedious and time consuming The computation model of DSM provides the facility of on demand migration of data between processors Distributed File System Two main purposes of using files: 1. Permanent storage of information on a secondary storage media. 2. Sharing of information between applications. A file system is a subsystem of the operating system that performs file management activities such as organization, storing, retrieval, naming, sharing, and protection of files. A file system frees the programmer from concerns about the details of space allocation and layout of the secondary storage device. The design and implementation of a distributed file system is more complex than a conventional file system due to the fact that the users and storage devices are physically dispersed. In addition to the functions of the file system of a single-processor system, the distributed file system supports the following: 1. Remote information sharing - Thus any node, irrespective of the physical location of the file, can access the file. 2. User mobility - User should be permitted to work on different nodes.
- 22. Unit II/Distributed System Truba College of Science & Technology, Bhopal Prepared By: Ms. Nandini Sharma(CSE DEPTT.) Page 22 3. Availability - For better fault-tolerance, files should be available for use even in the event of temporary failure of one or more nodes of the system. Thus the system should maintain multiple copies of the files, the existence of which should be transparent to the user. 4. Diskless workstations - A distributed file system, with its transparent remote-file accessing capability, allows the use of diskless workstations in a system. A distributed file systemprovides the following types of services 1. Storage service - Allocation and management of space on a secondary storage device thus providing a logical view of the storage system. 2. True file service - Includes file-sharing semantics, file-caching mechanism, file replication mechanism, concurrency control, multiple copy update protocol etc. 3. Name/Directory service - Responsible for directory related activities such as creation and deletion of directories, adding a new file to a directory, deleting a file from a directory, changing the name of a file, moving a file from one directory to another etc. Desirable features of a distributed file system 1. Transparency Structure transparency - Clients should not know the number or locations of file servers and the storage devices. Note: multiple file servers provided for performance, scalability, and reliability. Access transparency - Both local and remote files should be accessible in the same way. The file system should automatically locate an accessed file and transport it to the client’s site. Naming transparency - The name of the file should give no hint as to the location of the file. The name of the file must not be changed when moving from one node to another. Replication transparency - If a file is replicated on multiple nodes, both the existence of multiple copies and their locations should be hidden from the clients. 2. User mobility - Automatically bring the user’s environment (e.g. user’s home directory) to the node where the user logs in. 3. Performance - Performance is measured as the average amount of time needed to satisfy client requests. This time includes CPU time + time for accessing secondary storage + network access time. It is desirable that the performance of a distributed file system be comparable to that of a centralized file system. 4. Simplicity and ease of use - User interface to the file system be simple and number of commands should be as small as possible. 5. Scalability - Growth of nodes and users should not seriously disrupt service. 6. High availability - A distributed file system should continue to function in the face of partial failures such as a link failure, a node failure, or a storage device crash. A highly reliable and
- 23. Unit II/Distributed System Truba College of Science & Technology, Bhopal Prepared By: Ms. Nandini Sharma(CSE DEPTT.) Page 23 scalable distributed file system should have multiple and independent file servers controlling multiple and independent storage devices. 7. High reliability - Probability of loss of stored data should be minimized. System should automatically generate backup copies of critical files. 8. Data integrity - Concurrent access requests from multiple users who are competing to access the file must be properly synchronized by the use of some form of concurrency control mechanism. Atomic transactions can also be provided. 9. Security - Users should be confident of the privacy of their data. 10. Heterogeneity - There should be easy access to shared data on diverse platforms (e.g. Unix workstation, Wintel platform etc). File Models 1.Unstructured and Structured files In the unstructured model, a file is an unstructured sequence of bytes. The interpretation of the meaning and structure of the data stored in the files is up to the application (e.g. UNIX and MS-DOS). Most modern operating systems use the unstructured file model. In structured files (rarely used now) a file appears to the file server as an ordered sequence of records. Records of different files of the same file system can be of different sizes. 2. Mutable and immutable files Based on the modifiability criteria, files are of two types, mutable and immutable. Most existing operating systems use the mutable file model. An update performed on a file overwrites its old contents to produce the new contents. In the immutable model, rather than updating the same file, a new version of the file is created each time a change is made to the file contents and the old version is retained unchanged. The problems in this model are increased use of disk space and increased disk activity. File Accessing Models This depends on the method used for accessing remote files and the unit of data access. 1. Accessing remote files - A distributed file system may use one of the following models to service a client’s file access request when the accessed file is remote: a. Remote service model - Processing of a client’s request is performed at the server’s node. Thus, the client’s request for file access is delivered across the network as a message to the server, the server machine performs the access request, and the result is sent to the client. Need to minimize the number of messages sent and the overhead per message.
- 24. Unit II/Distributed System Truba College of Science & Technology, Bhopal Prepared By: Ms. Nandini Sharma(CSE DEPTT.) Page 24 b. Data-caching model - This model attempts to reduce the network traffic of the previous model by caching the data obtained from the server node. This takes advantage of the locality feature of the found in file accesses. A replacement policy such as LRU is used to keep the cache size bounded. While this model reduces network traffic it has to deal with the cache coherency problem during writes, because the local cached copy of the data needs to be updated, the original file at the server node needs to be updated and copies in any other caches need to be updated. Advantage of Data-caching model over the Remote service model: The data-caching model offers the possibility of increased performance and greater system scalability because it reduces network traffic, contention for the network, and contention for the file servers. Hence almost all distributed file systems implement some form of caching. Example, NFS uses the remote service model but adds caching for better performance. Unit of Data Transfer In file systems that use the data-caching model, an important design issue is to decide the unit of data transfer. This refers to the fraction of a file that is transferred to and from clients as a result of single read or write operation. File-level transfer model - In this model when file data is to be transferred, the entire file is moved. Advantages: file needs to be transferred only once in response to client request and hence is more efficient than transferring page by page which requires more network protocol overhead. Reduces server load and network traffic since it accesses the server only once. This has better scalability. Once the entire file is cached at the client site, it is immune to server and network failures. Disadvantage: requires sufficient storage space on the client machine. This approach fails for very large files, especially when the client runs on a diskless workstation. If only a small fraction of a file is needed, moving the entire file is wasteful. Block-level transfer model - File transfer takes place in file blocks. A file block is a contiguous portion of a file and is of fixed length (can also be a equal to a virtual memory page size). Advantages: Does not require client nodes to have large storage space. It eliminates the need to copy an entire file when only a small portion of the data is needed. Disadvantages: When an entire file is to be accessed, multiple server requests are needed, resulting in more network traffic and more network protocol overhead. NFS uses block-level transfer model. Byte-level transfer model - Unit of transfer is a byte. Model provides maximum flexibility because it allows storage and retrieval of an arbitrary amount of a file, specified by an offset
- 25. Unit II/Distributed System Truba College of Science & Technology, Bhopal Prepared By: Ms. Nandini Sharma(CSE DEPTT.) Page 25 within a file and length. Drawback is that cache management is harder due to the variable- length data for different access requests. Record-level transfer model This model is used with structured files and the unit of transfer is the record. File-Sharing Semantics Multiple users may access a shared file simultaneously. An important design issue for any file system is to define when modifications of file data made by a user are observable by other users. UNIX semantics: This enforces an absolute time ordering on all operations and ensures that every read operation on a file sees the effects of all previous write operations performed on that file. UNIX File-sharing semantics The UNIX semantics is implemented in file systems for single CPU systems because it is the most desirable semantics and because it is easy to serialize all read/write requests. Implementing UNIX semantics in a distributed file systemis not easy. One may think that this can be achieved in a distributed system by disallowing files to be cached at client nodes and allowing a shared file to be managed by only one file server that processes all read and write requests for the file strictly in the order in which it receives them. However, even with this approach, there is a possibility that, due to network delays, client requests from different nodes may arrive and get processed at the server node in an order different from the actual order in which the requests were made. Also, having all file access requests processed by a single server and disallowing caching on client nodes is not desirable in practice due to poor performance, poor scalability, and poor reliability of the distributed file system. Hence distributed file systems implement a more relaxed semantics of file sharing. Method Comment UNIX semantics Every operation on a file is instantly visible to all processes Session semantics No changes are visible to other processes until the file is closed Immutable files No updates are possible; simplifies sharing and replication Transactions All changes have the all-or-nothing property File Caching Schemes - Every distributed file system uses some form of caching. The reasons are:
- 26. Unit II/Distributed System Truba College of Science & Technology, Bhopal Prepared By: Ms. Nandini Sharma(CSE DEPTT.) Page 26 1. Better performance since repeated accesses to the same information is handled additional network accesses and disk transfers. This is due to locality in file access patterns 2. .2. It contributes to the scalability and reliability of the distributed file system since data can be remotely cached on the client node. Key decisions to be made in file-caching scheme for distributed systems: 1. Cache location 2. Modification Propagation 3. Cache Validation Cache Location This refers to the place where the cached data is stored. Assuming that the original location of a file is on its server’s disk, there are three possible cache locations in a distributed file system: 1. Server’s main memory In this case a cache hit costs one network access. It does not contribute to scalability and reliability of the distributed file system. Since we every cache hit requires accessing the server. Advantages: a. Easy to implement b. Totally transparent to clients c. Easy to keep the original file and the cached data consistent.
- 27. Unit II/Distributed System Truba College of Science & Technology, Bhopal Prepared By: Ms. Nandini Sharma(CSE DEPTT.) Page 27 2. Client’s disk In this case a cache hit costs one disk access. This is somewhat slower than having the cache in server’s main memory. Having the cache in server’s main memory is also simpler. Advantages: a. Provides reliability against crashes since modification to cached data is lost in a crash if the cache is kept in main memory. b. Large storage capacity. c. Contributes to scalability and reliability because on a cache hit the access request can be serviced locally without the need to contact the server. 3. Client’s main memory Eliminates both network access cost and disk access cost. This technique is not preferred to a client’s disk cache when large cache size and increased reliability of cached data are desired. Advantages: a. Maximum performance gain. b. Permits workstations to be diskless. c. Contributes to reliability and scalability. Modification Propagation When the cache is located on clients nodes, a file’s data may simultaneously be cached on multiple nodes. It is possible for caches to become inconsistent when the file data is changed by one of the clients and the corresponding data cached at other nodes are not changed or discarded. There are two design issues involved: 1. When to propagate modifications made to a cached data to the corresponding file server. 2. How to verify the validity of cached data. The modification propagation scheme used has a critical affect on the system’s performance and reliability. Techniques used include: Write-through scheme. When a cache entry is modified, the new value is immediately sent to the server for updating the master copy of the file. Advantage: High degree of reliability and suitability for UNIX-like semantics.
- 28. Unit II/Distributed System Truba College of Science & Technology, Bhopal Prepared By: Ms. Nandini Sharma(CSE DEPTT.) Page 28 This is due to the fact that the risk of updated data getting lost in the event of a client crash is very low since every modification is immediately propagated to the server having the master copy. Disadvantage: This scheme is only suitable where the ratio of read-to-write accesses is fairly large. It does not reduce network traffic for writes. This is due to the fact that every write access has to wait until the data is written to the master copy of the server. Hence the advantages of data caching are only read accesses because the server is involved for all write accesses. Delayed-write scheme. To reduce network traffic for writes the delayed-write scheme is used. In this case, the new data value is only written to the cache and all updated cache entries are sent to the server at a later time. There are three commonly used delayed-write approaches: 1. Write on ejection from cache - Modified data in cache is sent to server only when the cache-replacement policy has decided to eject it from clients cache. This can result in good performance but there can be a reliability problem since some server data may be outdated for a long time. 2. Periodic write - The cache is scanned periodically and any cached data that has been modified since the last scan is sent to the server. 3. Write on close - Modification to cached data is sent to the server when the client closes the file. This does not help much in reducing network traffic for those files that are open for very short periods or are rarely modified. Advantages of delayed-write scheme: 1. Write accesses complete more quickly because the new value is written only client cache. This results in a performance gain. 2. Modified data may be deleted before it is time to send to send them to the server (e.g. temporary data). Since modifications need not be propagated to the server this results in a major performance gain. 3. Gathering of all file updates and sending them together to the server is more efficient than sending each update separately. Disadvantage of delayed-write scheme: Reliability can be a problem since modifications not yet sent to the server from a client’s cache will be lost if the client crashes.
- 29. Unit II/Distributed System Truba College of Science & Technology, Bhopal Prepared By: Ms. Nandini Sharma(CSE DEPTT.) Page 29 Cache Validation schemes - The modification propagation policy only specifies when the master copy of a file on the server node is updated upon modification of a cache entry. It does not tell anything about when the file data residing in the cache of other nodes is updated. A file data may simultaneously reside in the cache of multiple nodes. A client’s cache entry becomes stale as soon as some other client modifies the data corresponding to the cache entry in the master copy of the file on the server. It becomes necessary to verify if the data cached at a client node is consistent with the master copy. If not, the cached data must be invalidated and the updated version of the data must be fetched again from the server. There are two approaches to verify the validity of cached data: the client-initiated approach and the server-initiated approach. Client-initiated approach The client contacts the server and checks whether its locally cached data is consistent with the master copy. Two approaches may be used: 1. Checking before every access. - This defeats the purpose of caching because the server needs to be contacted on every access. 2. Periodic checking. - A check is initiated every fixed interval of time. Disadvantage of client-initiated approach: If frequency of the validity check is high, the cache validation approach generates a large amount of network traffic and consumes precious server CPU cycles. Server-initiated approach A client informs the file server when opening a file, indicating whether a file is being opened for reading, writing, or both. The file server keeps a record of which client has which file open and in what mode. So server monitors file usage modes being used by different clients and reacts whenever it detects a potential for inconsistency. E.g. if a file is open for reading, other clients may be allowed to open it for reading, but opening it for writing cannot be allowed. So also, a new client cannot open a file in any mode if the file is open for writing. When a client closes a file, it sends intimation to the server along with any modifications made to the file. Then the server updates its record of which client has which file open in which mode. When a new client makes a request to open an already open file and if the server finds that the new open mode conflicts with the already open mode, the server can deny the request, queue the request, or disable caching by asking all clients having the file open to remove that file from their caches. Note: On the web, the cache is used in read-only mode so cache validation is not an issue.
- 30. Unit II/Distributed System Truba College of Science & Technology, Bhopal Prepared By: Ms. Nandini Sharma(CSE DEPTT.) Page 30 Disadvantage: It requires that file servers be stateful. Stateful file servers have a distinct disadvantage over stateless file servers in the event of a failure. File Replication - High availability is a desirable feature of a good distributed file system and file replication is the primary mechanism for improving file availability. A replicated file is a file that has multiple copies, with each file on a separate file server. Difference Between Replication and Caching 1. A replica of a file is associated with a server, whereas a cached copy is normally associated with a client. 2. The existence of a cached copy is primarily dependent on the locality in file access patterns, whereas the existence of a replica normally depends on availability and performance requirements. 3. As compared to a cached copy, a replica is more persistent, widely known, secure, available, complete, and accurate. 4. A cached copy is contingent upon a replica. Only by periodic revalidation with respect to a replica can a cached copy be useful. Advantages of Replication 1. Increased Availability - Alternate copies of a replicated data can be used when the primary copy is unavailable. 2. Increased Reliability - Due to the presence of redundant data files in the system, recovery from catastrophic failures (e.g. hard drive crash) becomes possible. 3. Improved response time - It enables data to be accessed either locally or from a node to which access time is lower than the primary copy access time. 4. Reduced network traffic - If a file’s replica is available with a file server that resides on a client’s node, the client’s access request can be serviced locally, resulting in reduced network traffic. 5. Improved system throughput - Several clients request for access to a file can be serviced in parallel by different servers, resulting in improved system throughput. 6. Better scalability - Multiple file servers are available to service client requests since due to file replication. This improves scalability. Replication Transparency Replication of files should be transparent to the users so that multiple copies of a replicated file appear as a single logical file to its users. This calls for the assignment of a single identifier/name to all replicas of a file.
- 31. Unit II/Distributed System Truba College of Science & Technology, Bhopal Prepared By: Ms. Nandini Sharma(CSE DEPTT.) Page 31 In addition, replication control should be transparent, i.e., the number and locations of replicas of a replicated file should be hidden from the user. Thus replication control must be handled automatically in a user-transparent manner. Multicopy Update Problem Maintaining consistency among copies when a replicated file is updated is a major design issue of a distributed file system that supports file replication. 1. Read-only replication - In this case the update problem does not arise. This method is too restrictive. 2. Read-Any-Write-All Protocol - A read operation on a replicated file is performed by reading any copy of the file and a write operation by writing to all copies of the file. Before updating any copy, all copies need to be locked, then they are updated, and finally the locks are released to complete the write. Disadvantage: A write operation cannot be performed if any of the servers having a copy of the replicated file is down at the time of the write operation. 3. Available-Copies Protocol - A read operation on a replicated file is performed by reading any copy of the file and a write operation by writing to all available copies of the file. Thus if a file server with a replica is down, its copy is not updated. When the server recovers after a failure, it brings itself up to date by copying from other servers before accepting any user request. 4. Primary-Copy Protocol - For each replicated file, one copy is designated as the primary copy and all the others are secondary copies. Read operations can be performed using any copy, primary or secondary. But write operations are performed only on the primary copy. Each server having a secondary copy updates its copy either by receiving notification of changes from the server having the primary copy or by requesting the updated copy from it. E.g. for UNIX-like semantics, when the primary-copy server receives an update request, it immediately orders all the secondary-copy servers to update their copies. Some form of locking is used and the write operation completes only when all the copies have been updated. In this case, the primary-copy protocol is simply another method of implementing the read-any-write-all protocol. Naming The naming facility of a distributed operating system enables users and programs to assign character-string names to objects and subsequently use these names to refer to those objects. • The locating facility, which is an integral part of the naming facility, maps an object's name to the object's location in a distributed system . • The naming and locating facilities jointly form a naming system that provides the users with an abstraction of an object that hides the details of how and where an object is actually located in the network.
- 32. Unit II/Distributed System Truba College of Science & Technology, Bhopal Prepared By: Ms. Nandini Sharma(CSE DEPTT.) Page 32 • It provides a further level of abstraction when dealing with object replicas. Given an object name, it returns a set of the locations of the object's replicas. • The naming system plays a very important role in achieving the goal of location transparency, facilitating transparent migration and replication of objects, object sharing. DESIRABLE FEATURES OF A GOOD NAMING SYSTEM 1. Location transparency. Location transparency means that the name of an object should not reveal any hint as to the physical location of the object. That is, an object's name should be independent of the physical connectivity or topology of the system, or the current location of the object. 2. Location independency. For performance, reliability, availability, and security reasons, distributed systems provide the facility of object migration that allows the movement and relocation of objects dynamically among the various nodes of a system. Location independency means that the name of an object need not be changed when the object's location changes. Furthermore, a user should be able to access an object by its same name irrespective of the node from where he or she accesses it ( user migration). Therefore, the requirement of location independency calls for a global naming facility with the following two features: An object at any node can be accessed without the knowledge of its physical location (location independency of request-receiving objects). An object at any node can issue an access request without the knowledge of its own physical location (location independency of request-issuing objects). This property is also known as user mobility 3. Scalability -Distributed systems vary in size ranging from one with a few nodes to one with many nodes. Moreover, distributed systems are normally open systems, and their size changes dynamically. Therefore, it is impossible to have an a priori idea about how large the set of names to be dealt with is liable to get. Hence a naming system must be capable of adapting to the dynamically changing scale of a distributed system that normally leads to a change in the size of the name space. That is, a change in the system scale should not require any change in the naming or locating mechanisms. 4. Uniform naming convention - In many existing systems, different ways of naming objects, called naming conventions, are used for naming different types of objects. For example, file names typically differ from user names and process names. Instead of using such non uniform naming conventions, a good naming system should use the same naming convention for all types of objects in the system. 5. Multiple user-defined names for the same object. For a shared object, it is desirable that different users of the object can use their own convenient names for accessing it. Therefore, a naming system must provide the flexibility to assign multiple user-defined names to the same object. In this case, it should
- 33. Unit II/Distributed System Truba College of Science & Technology, Bhopal Prepared By: Ms. Nandini Sharma(CSE DEPTT.) Page 33 be possible for a user to change or delete his or her name for the object without affecting those of other users. 6. Group naming - A naming system should allow many different objects to be identified by the same name. Such a facility is useful to support broadcast facility or to group objects for conferencing or other applications . 7. Meaningful names. A name can be simply any character string identifying some object. However, for users, meaningful names are preferred to lower level identifiers such as memory pointers, disk block numbers, or network addresses. This is because meaningful names typically indicate something about the contents or function of their referents , are easily transmitted between users, and are easy to remember and use. Therefore, a good naming system should support at least two level of object identifiers, one convenient for human users and one convenient for machines. 8. Performance. The most important performance measurement of a naming system is the amount of time needed to map an object's name to its attributes, such as its location. In a distributed environment, this performance is dominated by the number of messages exchanged during the name-mapping operation. Therefore, a naming system should be efficient in the sense that the number of messages exchanged in a name-mapping operation should be as small as possible. 9. Fault tolerance - A naming system should be capable of tolerating, to some extent, faults that occur due to the failure of a node or a communication link in a distributed svstem network. That is, the naming system should continue functioning, perhaps in a degraded form, in the event of these failures. The degradation can be in performance. functionality, or both but should be proportional, in some sense, to the failures causing it. 10. Replication transparency - In a distributed system, replicas of an object are generally created to improve performance and reliability. A naming system should support the use of multiple copies of the same object in a user- transparent manner. That is, if not necessary, a user should not be aware that multiple copies of an object are in use. 11. Locating the nearest replica - When a naming system supports the use of multiple copies of the same object, it is important that the object-locating mechanism of the naming system should always supply the location of the nearest replica of the desired object. This is because the efficiency of the object accessing operation will be affected if the object-locating mechanism does not take this point into consideration. Human – Oriented Vs System – Oriented Names Names are used to designate or refer to objects at all levels of system architecture. It have various purposes, forms and properties depending on the levels at which they are defined. An informal distinction can be made between two basic classes of names widely used in operating systems human-oriented names and system-oriented names.
- 34. Unit II/Distributed System Truba College of Science & Technology, Bhopal Prepared By: Ms. Nandini Sharma(CSE DEPTT.) Page 34 A human-oriented name is generally a character string that is meaningful to its users. For example, users project1 file1 is a human-oriented name. Human-oriented names are defined by their users. For a shared object, different users of the object must have the flexibility to define their own human-oriented names for the object for accessing it. Flexibility must also be provided so that a user can change or delete their own name for the object without affecting those of other users. For transparency, human-oriented names should be independent of the physical location or the structure of objects they designate. Human- oriented names are also known as high-level names because they can be easily remembered by their users. Human-oriented names are not unique for an object and are normally variable in length not only for different objects but also for different names for the same object. They cannot be easily manipulated, stored and used by the machines for identification purpose. It must be possible at some level to uniquely identify every object in the entire system. Therefore in addition to human-oriented names which are useful for users, system-oriented names are needed to be used efficiency by the system. There names generally bit patterns of fixed size that can be easily manipulated and stored by machines. They are automatically generated by the system. They should be generated in a distributed manner to avoid the problems of efficiency and reliability of a centralized unique identifier generator. They are basically meant for use by the system but may also be used by the users. They are also known as unique identifiers and low-level names. A simple naming model based on these two types of names. In this naming model, a human-oriented name is first mapped to a system-oriented name that is then mapped to the physical locations of the corresponding object's replicas. Approaches of System – Oriented Names Centralized Approach for generating System-Oriented Names Distributed Approach for generating System – Oriented Names Generating Unique Identifiers in the event of Crashes Approaches of Human- Oriented Names Combining an Object’s Local Name with its Host Name Interlinking Isolated Name Spaces into a Single Name Space Sharing Remote name Spaces an Explicit Request A Single Global Name Space Object Locating Mechanisms Object Locating is the process of mapping an object’s system-oriented unique identifier to the replica locations of the object. It may be noted here that the Object-oriented operation is different and independent of the object-accessing operation. Broadcasting Expanding ring broadcast Encoding Location of object within its UID Searching Creator Node first and Then Broadcasting Using forward Location Pointers Using Hint Cache and Broadcasting.