






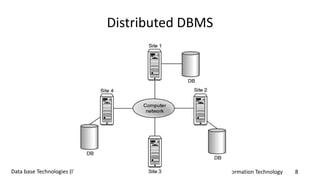
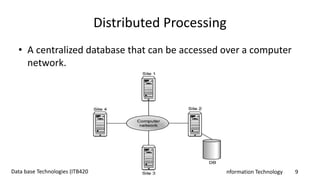


















































The document discusses distributed databases and distributed database management systems (DDBMS), emphasizing key concepts, architectures, advantages, and disadvantages. It outlines the characteristics of homogeneous and heterogeneous DDBMS, as well as various strategies for data fragmentation, allocation, and replication. Additionally, it covers transparency aspects such as distribution and transaction transparency, alongside Date's 12 rules for effective DDBMS implementation.























































































