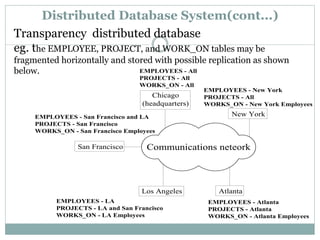
A distributed database management system (DDBMS) governs logically related data distributed across interconnected computer systems. A DDBMS manages a distributed database while making the distribution transparent to users. Distributed databases provide advantages like improved performance through storing data closer to where it is needed, easier expansion, and increased reliability through redundancy. However, distributed databases also introduce challenges around increased complexity, lack of standards, and security concerns.


















































































































![ict_presentation_final_final_final[1].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/ictpresentationfinalfinalfinal1-251230145259-2b4839bd-thumbnail.jpg?width=640&height=640&fit=bounds)









