Downloaded 83 times




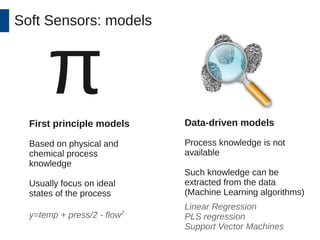






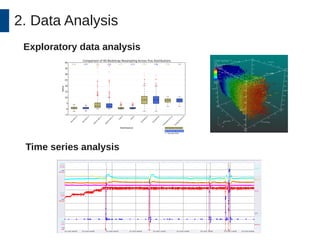
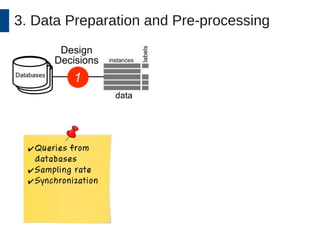
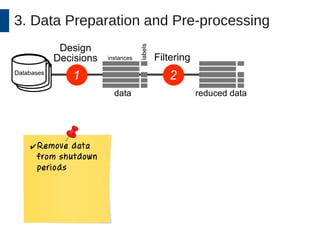
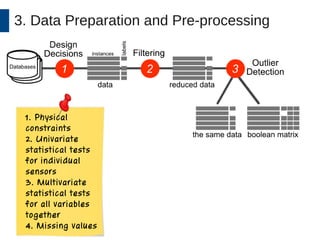
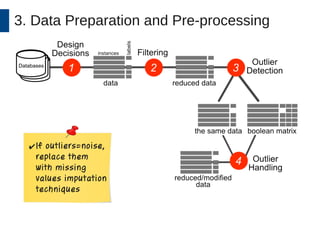
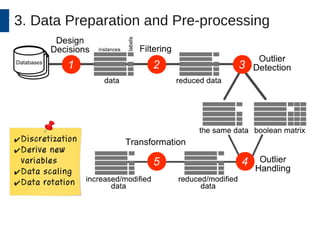
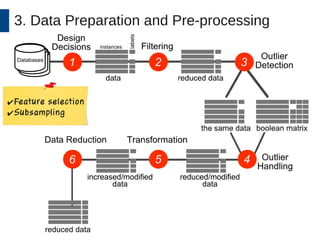
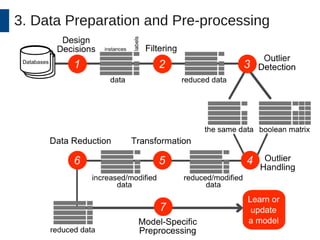
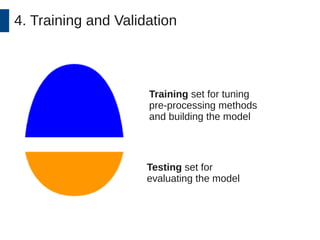

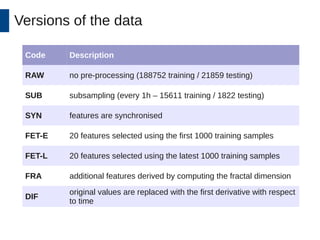
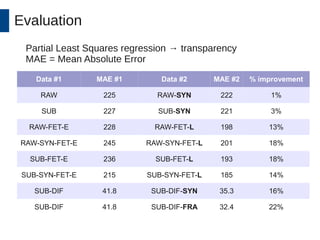




This document discusses the development and application of soft sensors, which are computational models that utilize sensor data to predict difficult-to-measure variables in the industrial process. It outlines a framework for building successful soft sensors, emphasizing the importance of data analysis, preparation, and validation, and presents a case study demonstrating these concepts. The document concludes with insights into the benefits of adaptive pre-processing and future directions for enhancing soft sensor technology.











































































































