Download as PDF, PPTX




























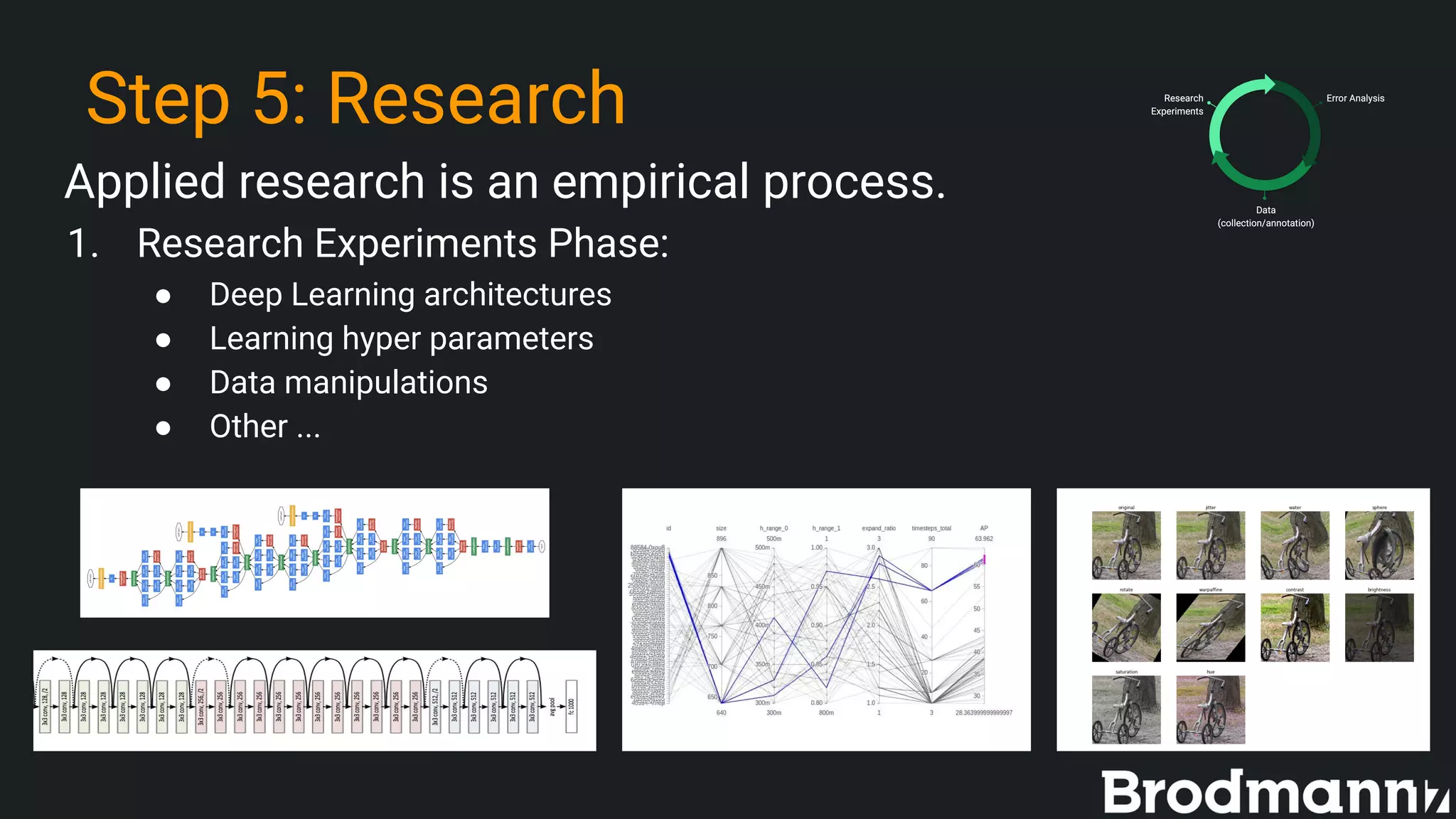










The document outlines five practical steps for successful deep learning research from Amir Alush, CTO of Brodmann17. These steps include setting clear product requirements, collecting and annotating data effectively, establishing research evaluation metrics, and optimizing the research process. The aim is to inform and guide researchers in developing perception software, particularly for autonomous driving applications.











































































