Download to read offline





![TO DO
How to increase the number of pre-processing methods in OpenML?
- The only way right now is using FilteredClassifier in Weka
- What about R, MOA, RapidMiner?
Improving flow representation
- Right now is difficult to see how components are connected
- Clear distinction of parameters
- What about including Weka flows (XML based) and ADAMS flows?
- PMML support?
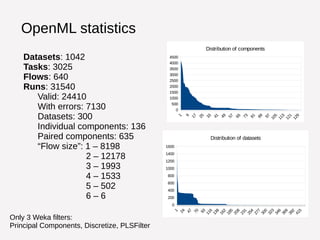
Statistics for available data, tasks, flows and runs
Flow recommendation system for a given dataset
[dataset, data characteristics, prediction accuracy, flow_id]
Flow validation before executing it
[dataset, data characteristics, flow characteristics, failure]](https://image.slidesharecdn.com/manuel-openml-141027125952-conversion-gate02/85/Quick-presentation-for-the-OpenML-workshop-in-Eindhoven-2014-9-320.jpg)



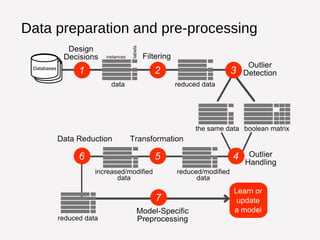
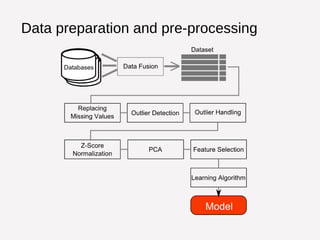
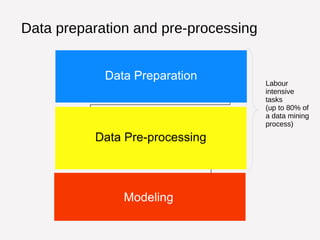
This document summarizes Manuel Martín Salvador's background and research interests in automated and adaptive data pre-processing for building predictive models. It discusses how data pre-processing makes up a large portion of the data mining process but is labor intensive. The document also outlines OpenML, a scientific workflow platform and repository for machine learning experiments, and highlights opportunities to increase the number and types of pre-processing methods available on the platform as well as improve flow representation and recommendation.




















































![Task A. [20 marks] Data Choice. Name the chosen data set(s) .docx](https://cdn.slidesharecdn.com/ss_thumbnails/taska-230122114958-f5b837f5-thumbnail.jpg?width=640&height=640&fit=bounds)










































