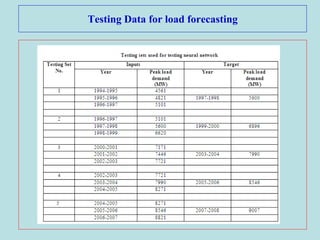
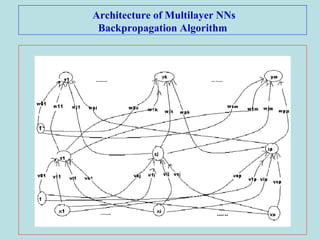
This document describes the backpropagation algorithm for training multilayer artificial neural networks (ANNs). It discusses the key aspects of the backpropagation algorithm including: the initialization of weights and biases, feedforward propagation, backpropagation of error to calculate weight updates, and updating weights and biases. It provides pseudocode for the backpropagation training algorithm and discusses factors that affect learning like learning rate and momentum. It also gives an example of using backpropagation for load forecasting in power systems, showing the network architecture, training algorithm, and results.








![Momentum factor
Momentum is a parameter that is used to improve the rate of convergance.
If the momentum is added to the weight update formula, the convergence is
faster.
Using momentum, the net does not proceed in the direction of the gradient,
but travels in the direction of the combination of the current gradient and
the previous direction for which the weight correction is made.
The main purpose of momentum is to accelerate the convergence of error
propagation algorithm.
)]1()([)()1(
)]1()([)()1(
tvtvxtvtv
twtwztwtw
ijijijijij
jkjkjkjkjk
](https://image.slidesharecdn.com/ann-2-200425092017/85/Back-propagation-10-320.jpg)