対比学習 (ContrastiveLearning)によるpre-trained model
4億枚の画像とテキストのペアから学習
非常に優れたembeddingが得られる。言語と画像を接続。
6
https://openai.com/blog/clip/
Radford et al., Learning Transferable Visual Models From Natural Language Supervision, ICML 2021.
7.
CLIP embedding(画像、動画像)をハブとして、
7種類の異なるモダリティをアラインメント
◦ 直接のペアデータがないモダリティ間での変換・検索が可能
7
GirdHar et al., IMAGEBIND: One Embedding Space
To Bind Them All, CVPR 2023.
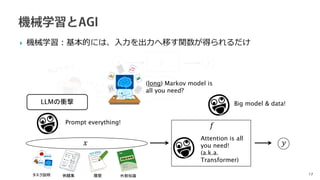
マルチモーダル +long, general-form prompting (context)
どうやって画像をLLMに接続するか?
◦ 1.画像特徴を言語ドメインへ変換
◦ 2.LLMで外部の画像基盤モデル(VFM)を呼び出す
10
Flamingo [Alayrac+, 2022]
Alayrac et al., Flamingo: a Visual Language Model for Few-Shot Learning, NeurIPS 2022.
11.
単純な射影によるトークンの変換
11
BLIP2 [Li+,2023]
LLaVa [Liu+, 2023]
学習に基づくクエリ+Transformer
Liu et al., Visual Instruction Tuning, arXiv, 2023.
Li et al., BLIP-2: Bootstrapping Language-Image Pre-training with
Frozen Image Encoders and Large Language Models, arXiv, 2023.


![3
オープンセット画像生成
[CVPR’22]
医用画像生成
[CIKM’19]
手書き文字生成
[ACMMM’22]
物語生成・評価
[EMNLP’22]
論文生成
[EMNLP’21
(Findings)]
文字消去
[WACV’20]
動画生成・制御
[MIRU’23]
コミットログ生成
[ACL’22]
非自己回帰型デコーダ
[AAAI’20]
画像生成 テキスト生成
機械翻訳
[ACL’19&18] ICLR’18]](https://image.slidesharecdn.com/random-230908040143-ec09c8e5/85/slide-3-320.jpg)
![4
a woman is slicing some vegetables
ゼロショット画像キャプショニング
[CVPR’22]
マルチモーダル対話 [EMNLP’20]
未来キャプショニング [CVPR’23]
マルチモーダル
動画キャプショニング [COLING’16]
画像ストーリー生成 [AAAI’21]
ストーリー可視化 [EMNLP’22]](https://image.slidesharecdn.com/random-230908040143-ec09c8e5/85/slide-4-320.jpg)
![5
2012
AlexNet
(ConvNet)
2016
Jigsaw
2015
ResNet
2020
SimCLR
2020
ViT
2021
Swin
Vision
NLP
2022
Stable Diffusion
2013
Skip-gram
2015
Seq2seq
+attention
2017
Trans
former
2018
ELMo
BERT
GPT-1
2020
GPT-3
2022
ChatGPT
2023
GPT-4
Bard
2018
BigGAN
2021
DALL-E
2021
CLIP
ALIGN
2022
BLIP
Florence
2023
IMAGEBIND
2021
CLIPSeg
2023
SAM
(古典的画像認識)
(テキストによるプロンプティング)
(さまざまなモダリティによるプロンプティング)
2022
Flamingo
2023
BLIP-2
LLaVA
GPT-4
(Adapted from [Awais+, 2023])
教師あり学習
(ImageNet)
教師なし表現学習
text-to-image生成
Image-text アラインメント
マルチモーダルLLM
汎用的セグメンテーションモデル
注:代表的かつ講演者が把握
しているごく一部の研究です。
まとめ方は主観含みます。](https://image.slidesharecdn.com/random-230908040143-ec09c8e5/85/slide-5-320.jpg)




![ マルチモーダル + long, general-form prompting (context)
どうやって画像をLLMに接続するか?
◦ 1.画像特徴を言語ドメインへ変換
◦ 2.LLMで外部の画像基盤モデル(VFM)を呼び出す
10
Flamingo [Alayrac+, 2022]
Alayrac et al., Flamingo: a Visual Language Model for Few-Shot Learning, NeurIPS 2022.](https://image.slidesharecdn.com/random-230908040143-ec09c8e5/85/slide-10-320.jpg)
![ 単純な射影によるトークンの変換
11
BLIP2 [Li+, 2023]
LLaVa [Liu+, 2023]
学習に基づくクエリ+Transformer
Liu et al., Visual Instruction Tuning, arXiv, 2023.
Li et al., BLIP-2: Bootstrapping Language-Image Pre-training with
Frozen Image Encoders and Large Language Models, arXiv, 2023.](https://image.slidesharecdn.com/random-230908040143-ec09c8e5/85/slide-11-320.jpg)
![ 外部モデル(画像キャプショニング
等)により画像をテキストに変換し、
LLMへ入力
12
LLaMA-Adapter V2
[Gao+, 2023]
Gao et al., LLaMA-Adapter V2: Parameter-Efficient Visual Instruction Model, arXiv, 2023.](https://image.slidesharecdn.com/random-230908040143-ec09c8e5/85/slide-12-320.jpg)
![13
LLaVa [Liu+, 2023]](https://image.slidesharecdn.com/random-230908040143-ec09c8e5/85/slide-13-320.jpg)
![ Visual ChatGPT [Wu+, 2023]
◦ LLM (ChatGPT) により適切なVFMの
選択と操作を行う
◦ Step-by-stepな推論(ループ)
◦ クエリに加え、各VFMの使い方、推
論・対話履歴をプロンプティング
14
Wu et al., Visual ChatGPT: Talking, Drawing and Editing with Visual Foundation Models, 2023.](https://image.slidesharecdn.com/random-230908040143-ec09c8e5/85/slide-14-320.jpg)

![ 10億トークンあったら何ができる?(妄想)
18
Ding et al., LONGNET: Scaling Transformers
to 1,000,000,000 Tokens, 2023.
200 (単語/分) × 60 (分) × 16 (時間) × 365 (日) × 80 (年)
LONGNET [Ding+, 2023]
◦ Transformerの入力長を10億トークンまで拡張
◦ さまざまなレンジ・解像度のアテンションを組み合わせる(dilated attention)
≒ 56億](https://image.slidesharecdn.com/random-230908040143-ec09c8e5/85/slide-18-320.jpg)
![[DL輪読会]Learning Transferable Visual Models From Natural Language Supervision](https://cdn.slidesharecdn.com/ss_thumbnails/dlkobayashi0115-210115012308-thumbnail.jpg?width=640&height=640&fit=bounds)





![[DL輪読会]ICLR2020の分布外検知速報](https://cdn.slidesharecdn.com/ss_thumbnails/iclr2020ood-190927011524-thumbnail.jpg?width=640&height=640&fit=bounds)



![SSII2021 [OS2-01] 転移学習の基礎:異なるタスクの知識を利用するための機械学習の方法](https://cdn.slidesharecdn.com/ss_thumbnails/os2-02final-210610091211-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DL輪読会]GLIDE: Guided Language to Image Diffusion for Generation and Editing](https://cdn.slidesharecdn.com/ss_thumbnails/glide2-220107030326-thumbnail.jpg?width=640&height=640&fit=bounds)







![[DL輪読会]ドメイン転移と不変表現に関するサーベイ](https://cdn.slidesharecdn.com/ss_thumbnails/20190614iwasawa-190614005939-thumbnail.jpg?width=640&height=640&fit=bounds)


![SSII2022 [SS2] 少ないデータやラベルを効率的に活用する機械学習技術 〜 足りない情報をどのように補うか?〜](https://cdn.slidesharecdn.com/ss_thumbnails/ss2ssii2022-220607054716-2760bd30-thumbnail.jpg?width=640&height=640&fit=bounds)




































