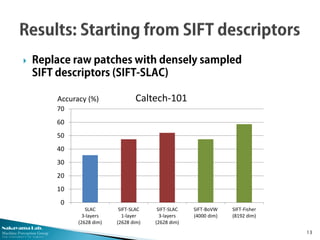
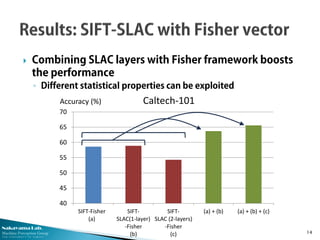
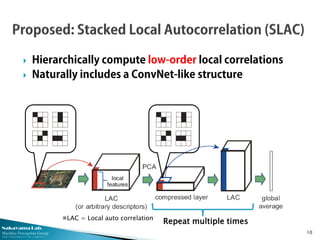
This document describes research from the Nakayama Lab at the University of Tokyo on deep learning approaches for computer vision tasks. It discusses stacked local autocorrelation (SLAC) features, which involve iteratively computing local autocorrelations and compressing with PCA. The SLAC approach achieves better performance than standard higher-order local autocorrelation features while using lower-dimensional representations. Combining SLAC with other frameworks like Fisher vectors can further boost performance on datasets like Caltech-101. Overall, the document advocates for deep learning by stacking different single-layer modules as a simple but powerful framework.

![Nakayama Lab.
Machine Perception Group
The University of Tokyo
Deep learning
◦ Successive local response filters and pooling layers
◦ State-of-the-art performance on many tasks & benchmarks
Traditional BoW-based models are often referred to as
“shallow learning” (interpreted as a single-layer network)
2
[A. Krizhevsky et al., NIPS’12]](https://image.slidesharecdn.com/slac-140731102349-phpapp02/85/MIRU2014-SLAC-2-320.jpg)
![Nakayama Lab.
Machine Perception Group
The University of Tokyo
To achieve a certain level of representational power...
Deep models are believed to require fewer free parameters
or neurons [Larochelle et al., 2007] [Bengio, 2009] [Delalleau and Bengio, 2011]
(not fully proved except for some specific cases, though.)
However, optimization of deep models is challenging
◦ Non-convex, local minima, many heuristic hyperparameters...
◦ Optimizing shallow network is relatively easy (convex in many cases)
3
(If successfully
trained) Better generalization
Computational efficiency
Scalability
Objection:
“Do Deep Nets Really
Need to be Deep?”
[Ba & Caruana, 2014]](https://image.slidesharecdn.com/slac-140731102349-phpapp02/85/MIRU2014-SLAC-3-320.jpg)
![Nakayama Lab.
Machine Perception Group
The University of Tokyo
Suboptimal (layer-wise)
Reasonable performance
◦ Even random weights
could work! [Jarrette, 2009]
Easiness in tuning
Stability in learning
Flexibility in the choice of
layer modules
Global optimality through
the entire network
State-of-the-art performance
Difficulty in optimization
Computational cost
Constraints on layer modules
4
Fine-tuning (back propagation)
through the entire network is
the key to the best performance!
Structure of the deep network
itself has the primary importance!
Global training of deep models Stacking single-layer
learning modules
◎
◎△
○](https://image.slidesharecdn.com/slac-140731102349-phpapp02/85/MIRU2014-SLAC-4-320.jpg)
![Nakayama Lab.
Machine Perception Group
The University of Tokyo
Suboptimal (layer-wise)
Reasonable performance
◦ Even random weights
could work! [Jarrette, 2009]
Easiness in tuning
Stability in learning
Flexibility in the choice of
layer modules
Global optimality through
the entire network
State-of-the-art performance
Difficulty in optimization
Computational cost
Constraints on layer modules
5
Fine-tuning (back propagation)
through the entire network is
the key to the best performance!
Structure of the deep network
itself has the primary importance!
Global training of deep models Stacking single-layer
learning modules
◎
◎△
○](https://image.slidesharecdn.com/slac-140731102349-phpapp02/85/MIRU2014-SLAC-5-320.jpg)
![Nakayama Lab.
Machine Perception Group
The University of Tokyo
Empirically studied on top of the bag-of-words framework
Hyperfeatures [Agarwal et al., ECCV’06]
◦ Hierarchically stack bag-of-visual-words layers
Deep Fisher Network [Simonyan et al., NIPS’13]
Deep Sparse Coding [He et al., SDM’14]
6](https://image.slidesharecdn.com/slac-140731102349-phpapp02/85/MIRU2014-SLAC-6-320.jpg)

![Nakayama Lab.
Machine Perception Group
The University of Tokyo
Sum-product network [Poon and Domingos, UAI’11]
◦ A deep network where each node (neuron) outputs the sum or
product of input variables
To represent the same functions, the number of nodes
has to grow: [Delalleau & Bengio, NIPS’11]
◦ Exponentially in a shallow network
◦ Linearly in a deep network
8](https://image.slidesharecdn.com/slac-140731102349-phpapp02/85/MIRU2014-SLAC-8-320.jpg)

![Nakayama Lab.
Machine Perception Group
The University of Tokyo
Datasets
◦ MNIST [LeCun,1999]
Digit recognition
60k training/10k testing samples
28x28 pixels
◦ CIFAR-10 [Krizhevsky, 2009]
Object recognition
50k training/10k testing samples
32x32 pixels
◦ Caltech-101 [Fei-Fei, 2004]
Object recognition
30 training/15 testing samples
(per class)
Classifier
◦ Logistic regression
11](https://image.slidesharecdn.com/slac-140731102349-phpapp02/85/MIRU2014-SLAC-11-320.jpg)