











![Deep Learning Theory
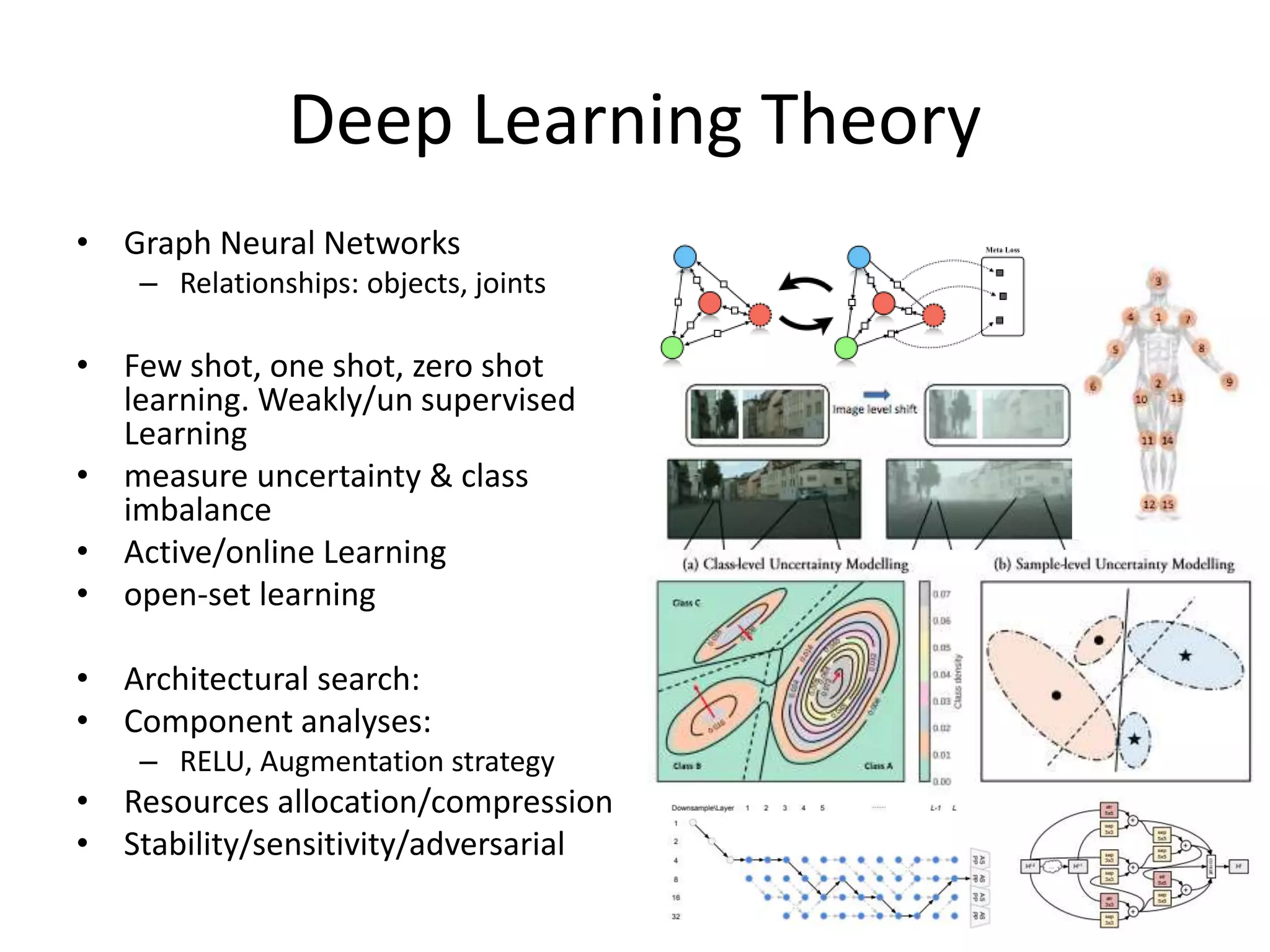
• Graph Convolutional Networks [https://arxiv.org/pdf/1609.02907.pdf]
– http://openaccess.thecvf.com/content_CVPR_2019/papers/Kim_Edge-Labeling_Graph_Neural_Network_for_Few-
Shot_Learning_CVPR_2019_paper.pdf
• Few shot, one shot, zero shot learning. Weakly/un
supervised Learning
– http://openaccess.thecvf.com/content_CVPR_2019/papers/Wang_Few-Shot_Adaptive_Faster_R-CNN_CVPR_2019_paper.pdf
• Active Learning
• measure uncertainty & class imbalance
– http://openaccess.thecvf.com/content_CVPR_2019/papers/Khan_Striking_the_Right_Balance_With_Uncertainty_CVPR_2019_paper.pdf
• Online learning, open-set
• Architectural search:– http://openaccess.thecvf.com/content_CVPR_2019/papers/Liu_Auto-DeepLab_Hierarchical_Neural_Architecture_Search_for_Semantic_Image_Segmentation_CVPR_2019_paper.pdf
• Component analyses:
– RELU, Augmentation strategy
– http://openaccess.thecvf.com/content_CVPR_2019/papers/Cubuk_AutoAugment_Learning_Augmentation_Strategies_From_Data_CVPR_2019_paper.pdf
• Resources allocation/compression:– http://openaccess.thecvf.com/content_CVPR_2019/papers/Qiao_Neural_Rejuvenation_Improving_Deep_Network_Training_by_Enhancing_Computational_Resource_CVPR_2019_paper.pdf
• Stability/sensitivity/adversarial](https://image.slidesharecdn.com/dataconla2019presentation-190901003646/75/Data-Con-LA-2019-State-of-the-Art-of-Innovation-in-Computer-Vision-by-Christian-Siagian-16-2048.jpg)






1) The document summarizes state-of-the-art topics in computer vision, including recognition, reconstruction, deep learning theory, and trends moving forward. 2) Contemporary computer vision topics discussed include graph neural networks, few-shot learning, active learning, architectural search, and measuring uncertainty. 3) Overarching trends include larger datasets dictating research activities and smaller manually annotated datasets catching up in performance through techniques like few and no shot training.



























































![[BDD 2025 - Full-Stack Development] Agentic AI Architecture: Redefining Syste...](https://cdn.slidesharecdn.com/ss_thumbnails/fs-agenticaiarchitectureredefiningsystemcommunication-251124030838-e6c70cc2-thumbnail.jpg?width=640&height=640&fit=bounds)

![[BDD 2025 - Mobile Development] Crafting Immersive UI with E2E and AGSL Shade...](https://cdn.slidesharecdn.com/ss_thumbnails/md-craftingimmersiveuiwithe2eandagslshaderveronicaputrianggraini-251124030840-0c677f44-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DevFest Strasbourg 2025] - NodeJs Can do that !!](https://cdn.slidesharecdn.com/ss_thumbnails/devfeststrasbourg2025-nodejscandothat-251127142731-da65b6fd-thumbnail.jpg?width=640&height=640&fit=bounds)



![[BDD 2025 - Full-Stack Development] PHP in AI Age: The Laravel Way. (Rizqy Hi...](https://cdn.slidesharecdn.com/ss_thumbnails/fs-phpinaiagethelaravelway-251125012602-ef9d330e-thumbnail.jpg?width=640&height=640&fit=bounds)









