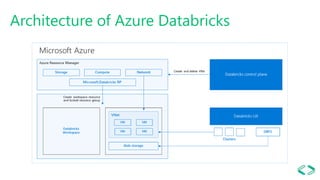
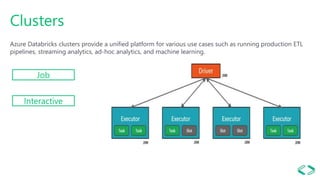
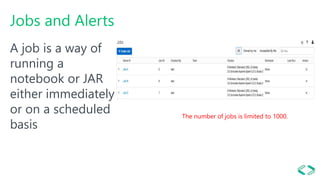
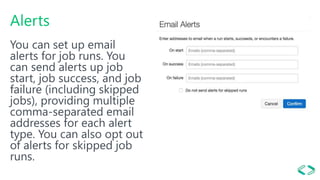
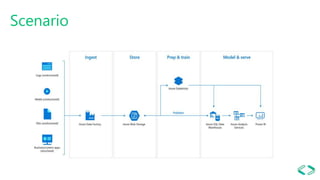
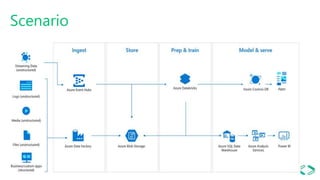
This document provides an overview of Azure Databricks, a Apache Spark-based analytics platform optimized for Microsoft Azure cloud services. It discusses key components of Azure Databricks including clusters, workspaces, notebooks, visualizations, jobs, alerts, and the Databricks File System. It also outlines how data engineers can leverage Azure Databricks for scenarios like running ETL pipelines, streaming analytics, and connecting business intelligence tools to query data.