Download as PDF, PPTX




























![Example: Spark’s Declarative DataFrame API
Users write DataFrame code in Python, R or Java
users = spark.table(“users”)
buyers = users[users.kind == “buyer”]
train_set = buyers[“start_date”, “zip”, “quantity”]
.fillna(0)](https://image.slidesharecdn.com/futuredata-lakehouse-200910170722/75/Making-Data-Timelier-and-More-Reliable-with-Lakehouse-Technology-39-2048.jpg)
![Example: Spark’s Declarative DataFrame API
Users write DataFrame code in Python, R or Java
...
model.fit(train_set)
Lazily evaluated query plan
Optimized execution using
cache, statistics, index, etc
users
SELECT(kind = “buyer”)
PROJECT(start_date, zip, …)
PROJECT(NULL → 0)users = spark.table(“users”)
buyers = users[users.kind == “buyer”]
train_set = buyers[“start_date”, “zip”, “quantity”]
.fillna(0)](https://image.slidesharecdn.com/futuredata-lakehouse-200910170722/75/Making-Data-Timelier-and-More-Reliable-with-Lakehouse-Technology-40-2048.jpg)

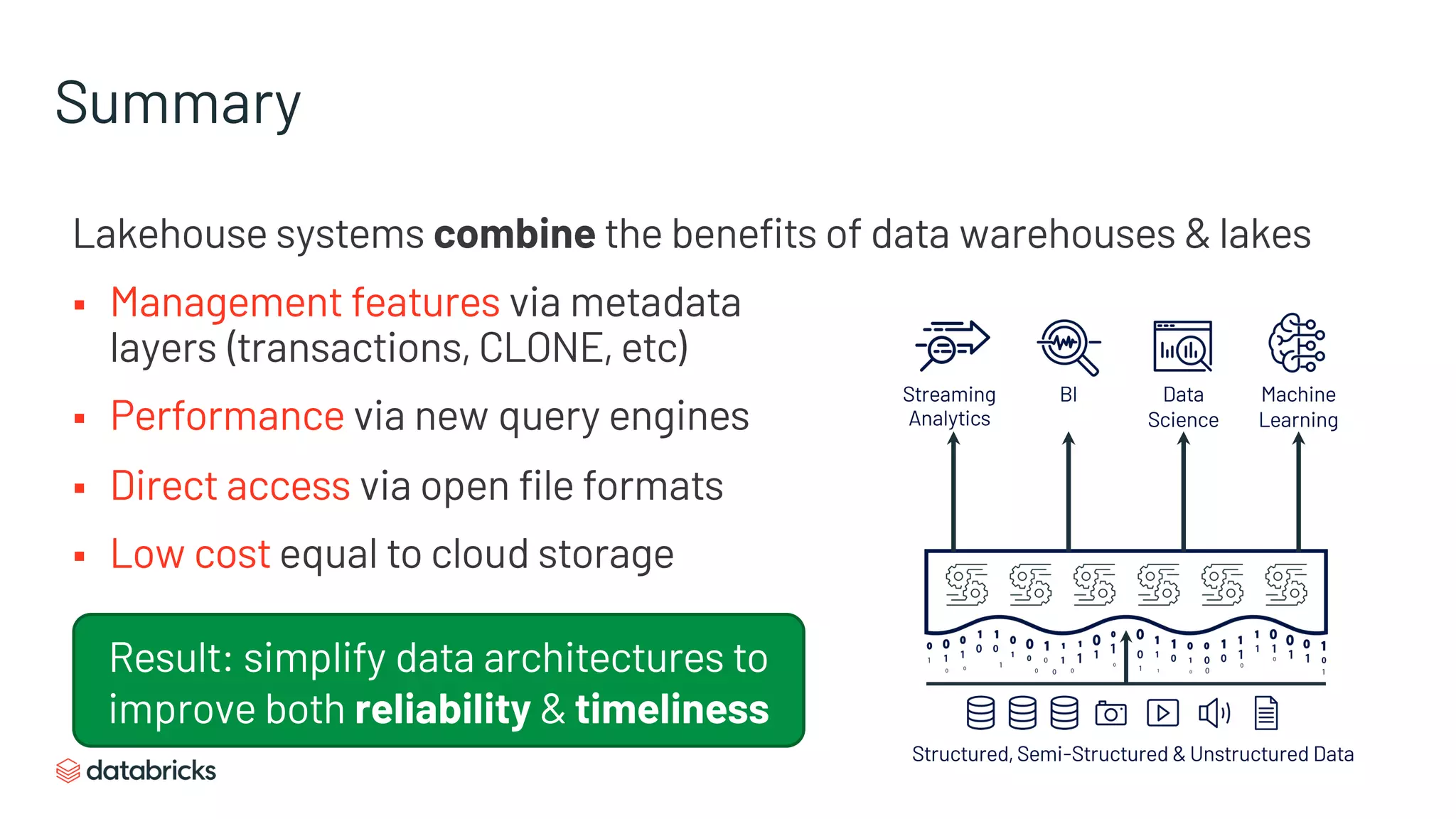
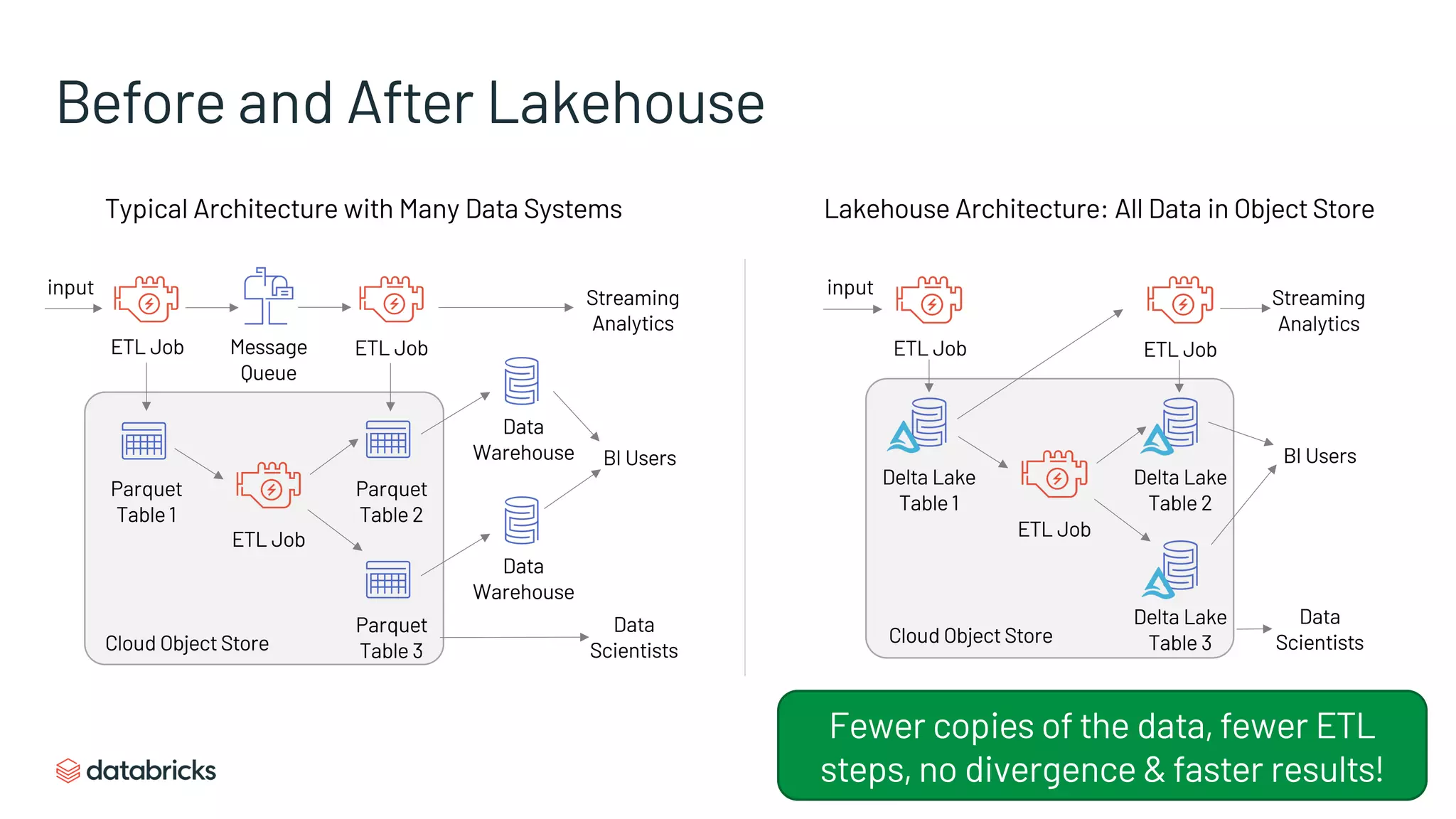


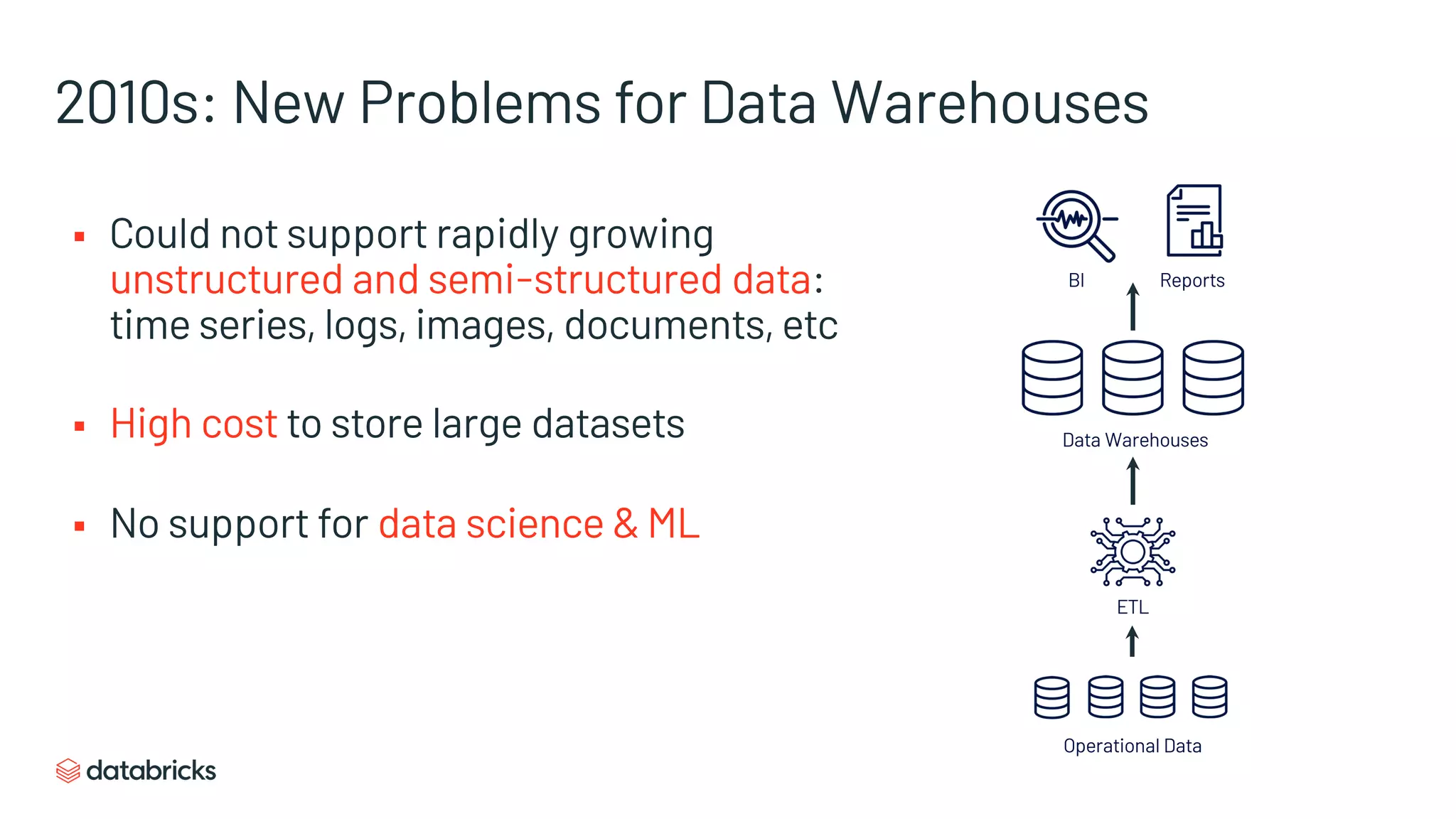
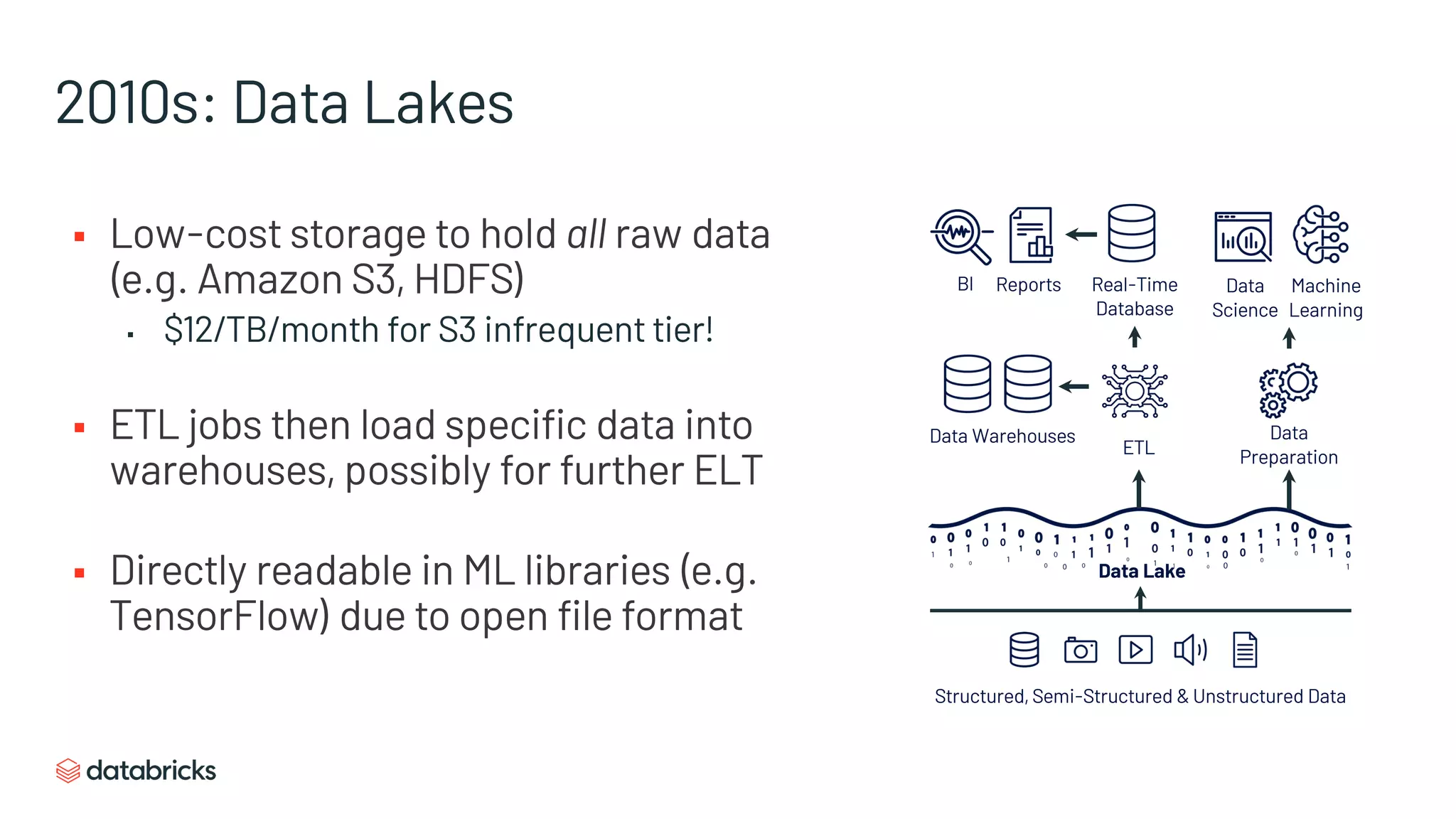
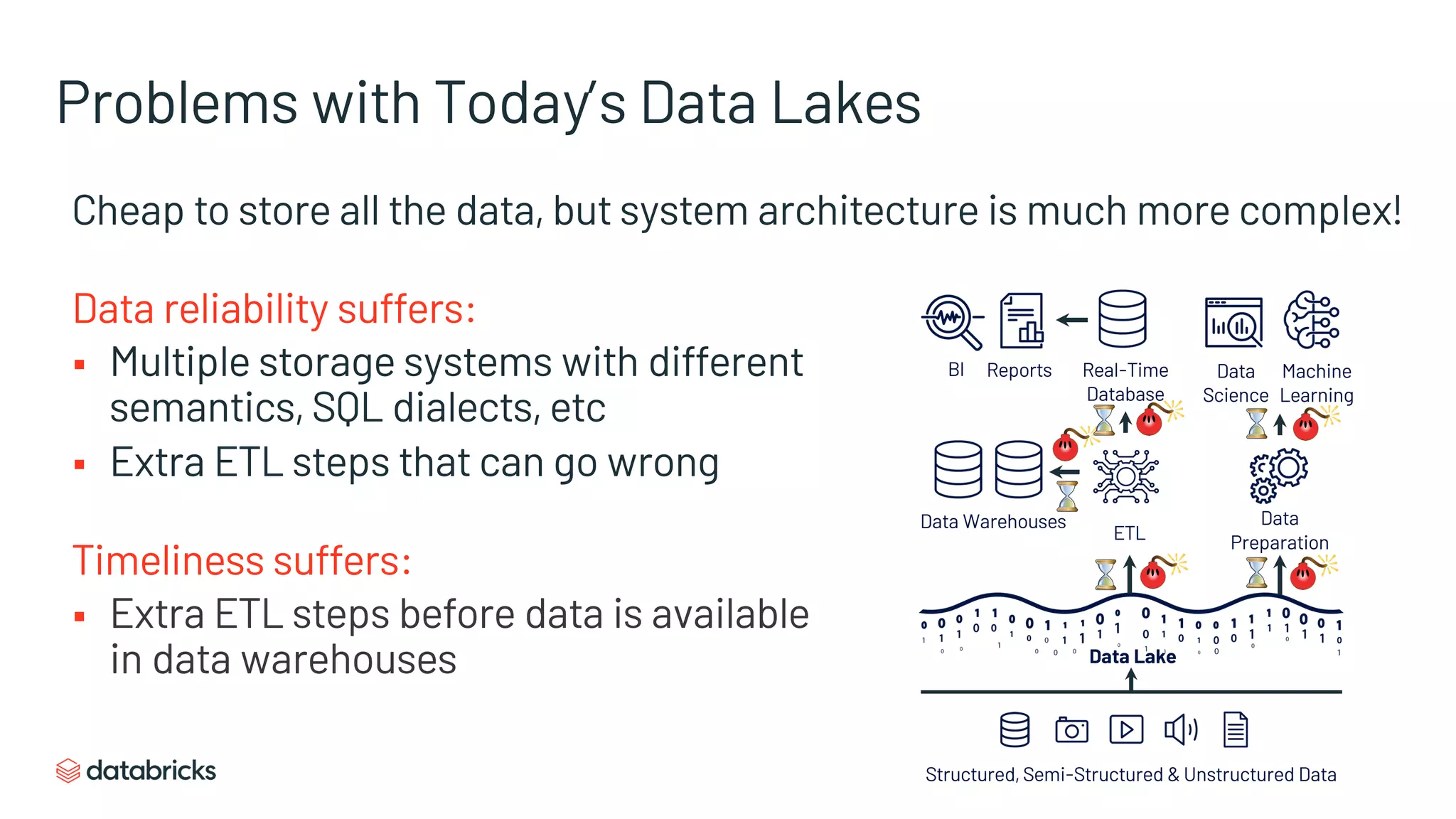
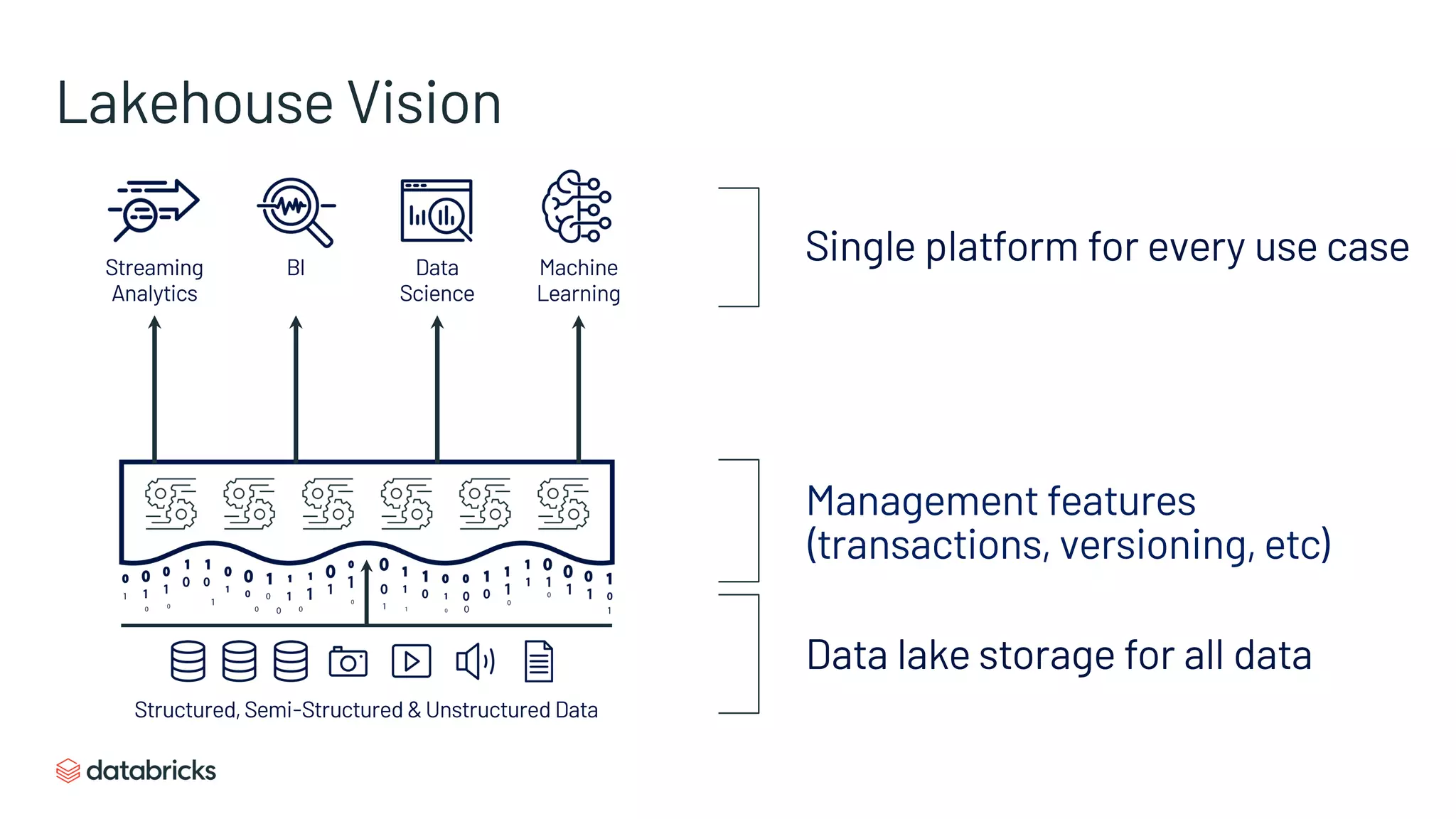
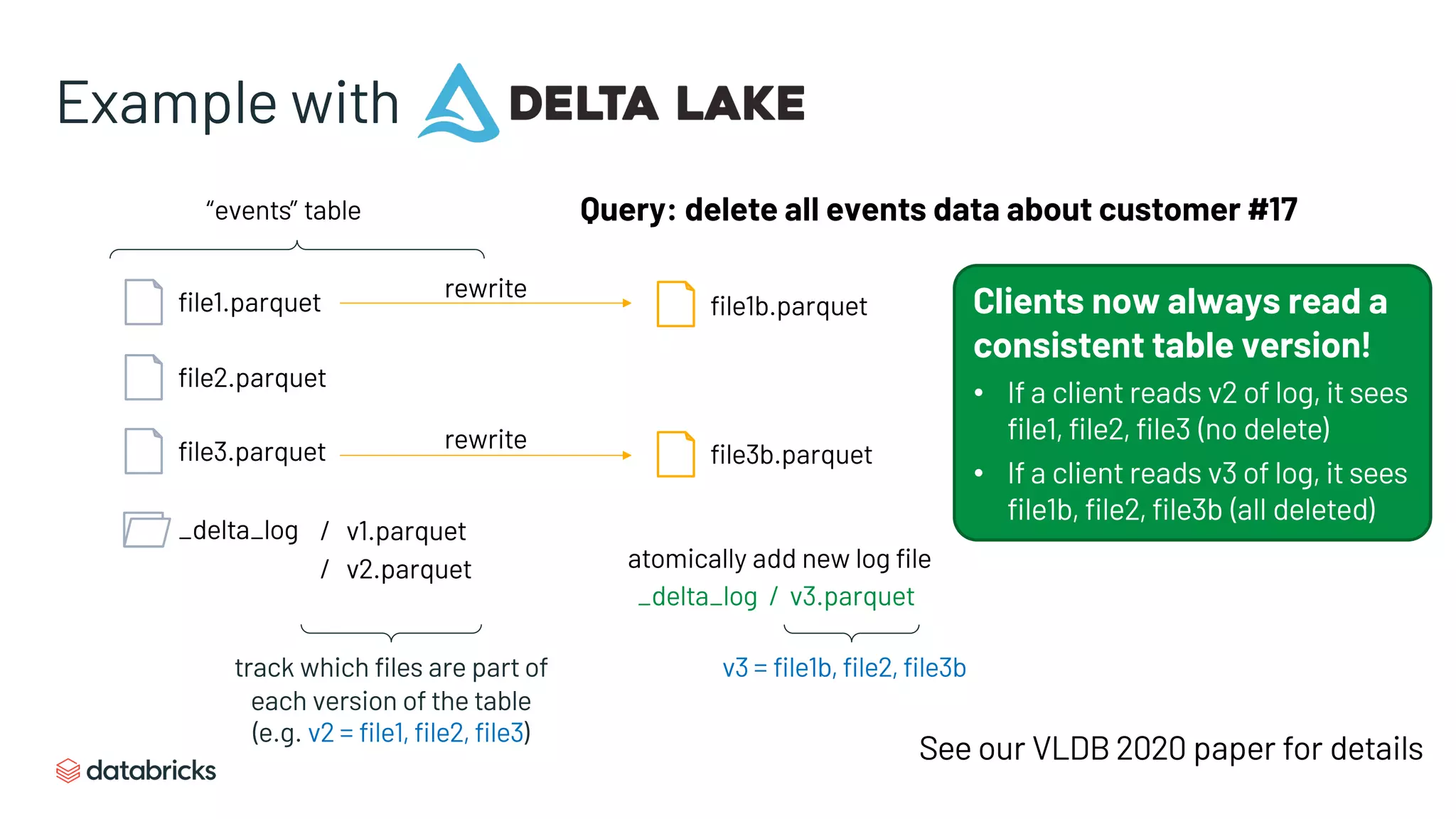
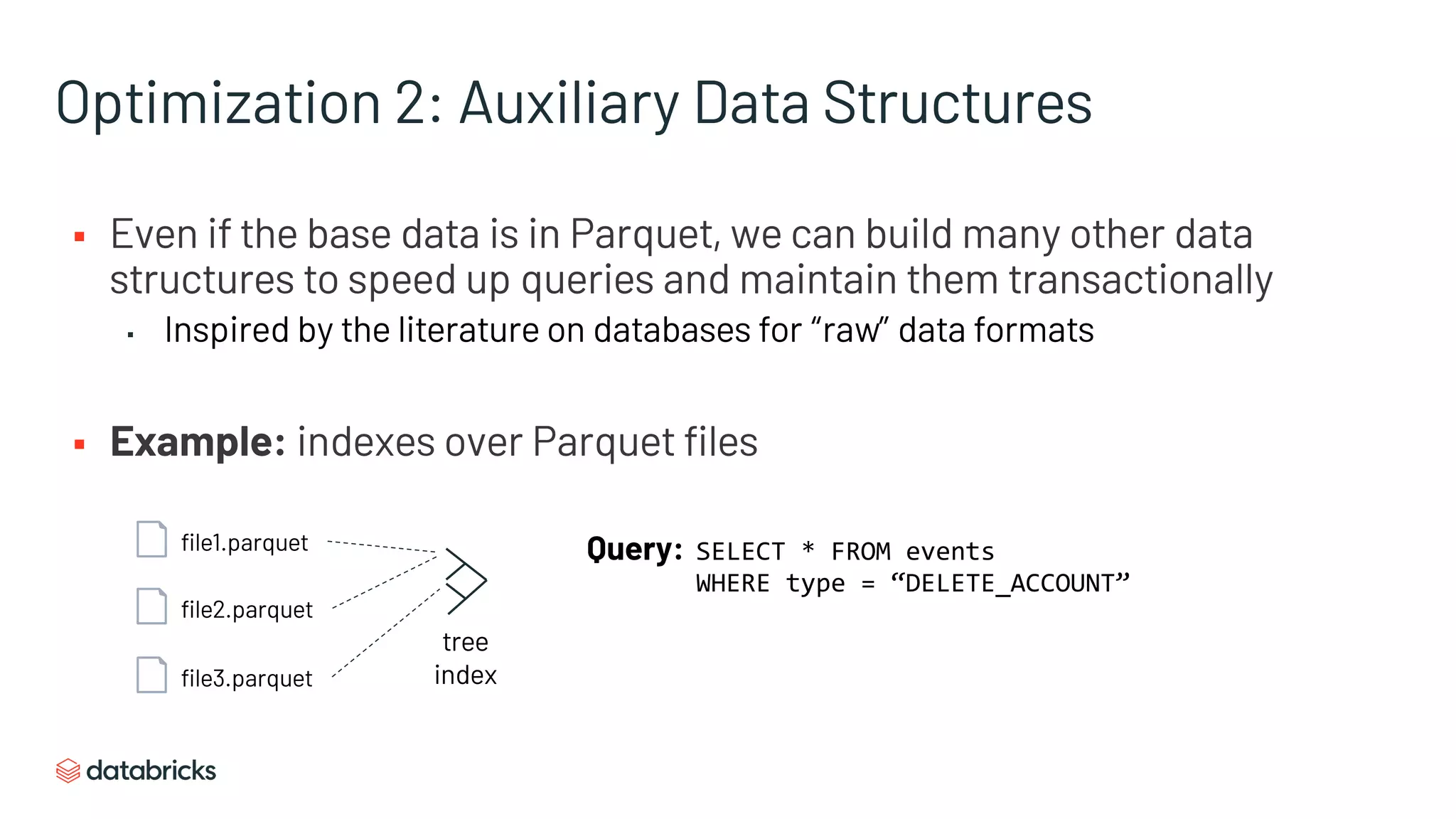
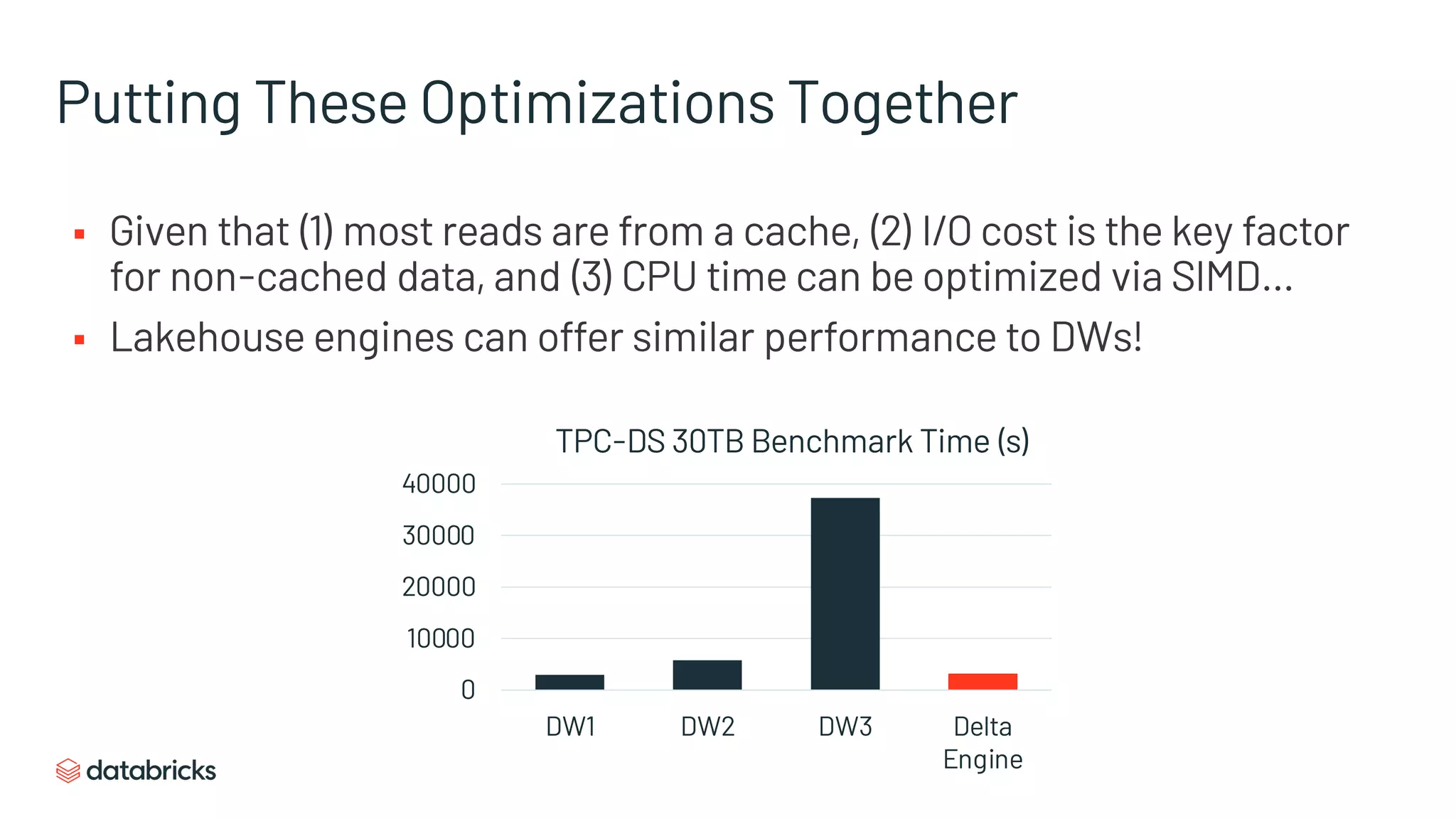
The document discusses the challenges of modern data analytics due to complex architectures and how lakehouse technology can simplify these systems by combining data warehousing and data lake features. It highlights that current issues like data quality and timeliness arise from unnecessary complexity and multiple storage systems. Lakehouse technologies, such as metadata layers and optimized query engines, aim to provide reliable, timely access to both structured and unstructured data while reducing costs and ETL steps.
![[DSC Europe 22] Lakehouse architecture with Delta Lake and Databricks - Draga...](https://cdn.slidesharecdn.com/ss_thumbnails/draganberic-lakehousearchitecturewithdeltalakeanddatabricks-221130080712-6e817e95-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DSC Europe 22] Overview of the Databricks Platform - Petar Zecevic](https://cdn.slidesharecdn.com/ss_thumbnails/petarzecevic-databricksoverview-221130080703-c60d93de-thumbnail.jpg?width=640&height=640&fit=bounds)






























































