Downloaded 24 times





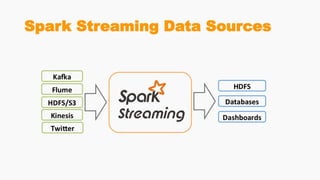

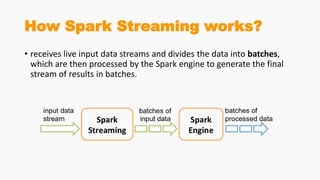



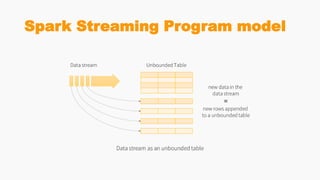

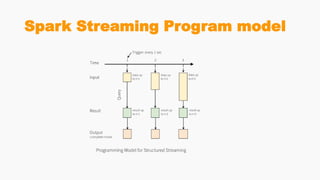



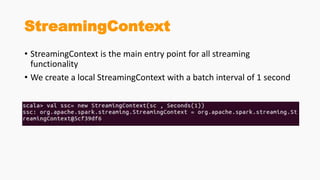










Spark Streaming allows for scalable, fault-tolerant stream processing of data ingested from sources like Kafka. It works by dividing the data streams into micro-batches, which are then processed using transformations like map, reduce, join using the Spark engine. This allows streaming aggregations, windows, and stream-batch joins to be expressed similarly to batch queries. The example shows a streaming word count application that receives text from a TCP socket, splits it into words, counts the words, and updates the result continuously.
























































![[DSC Europe 25] Elena Menshikova - AI-Powered Operational Excellence: Revolut...](https://cdn.slidesharecdn.com/ss_thumbnails/es6nholbqy3zaao2c2yd-2-elena-menshikova-data-ai-in-decision-making-260115093812-4fba8b38-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DSC Europe 25] Bojan Djuricic - Predictive Design Process.pdf](https://cdn.slidesharecdn.com/ss_thumbnails/5awdrbedqdek3gqu2ezy-4-the-predictive-design-bojan-djuricic-260120105856-6c399e9b-thumbnail.jpg?width=640&height=640&fit=bounds)




![[DSC Europe 25] Slobodan Dolinic - Smart and Intelligent Green Region.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/0bribinjsp6ghwtvsvor-2-sigre-slobodan-dolinic-260115093812-c9c10e90-thumbnail.jpg?width=640&height=640&fit=bounds)

