Download as PDF, PPTX





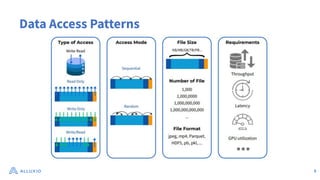
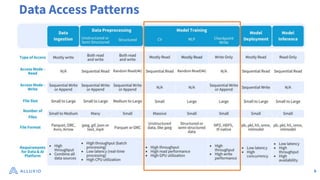
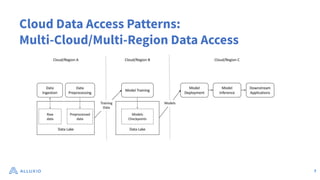
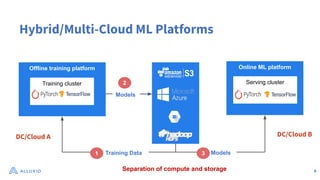





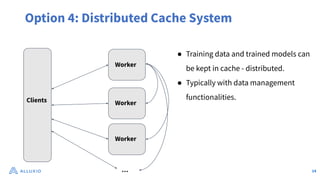

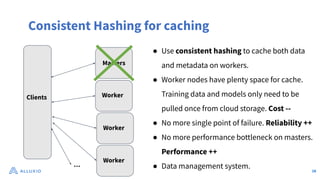


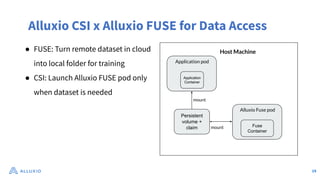

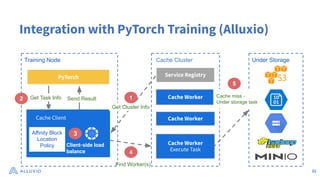
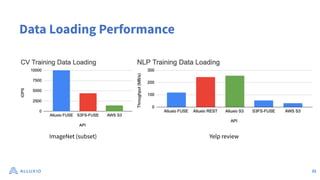
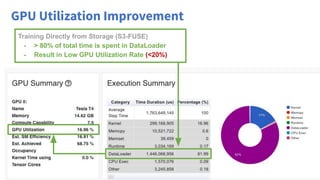
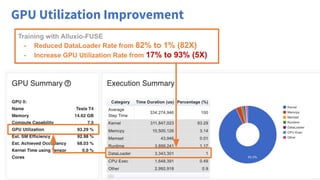

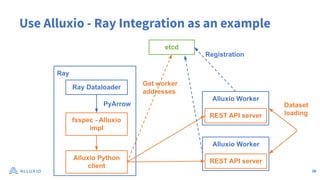
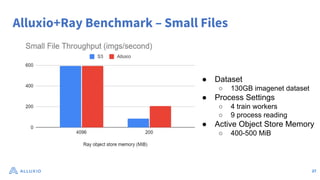
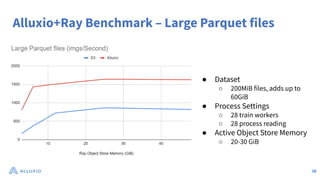
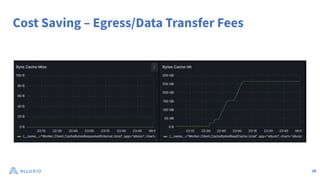


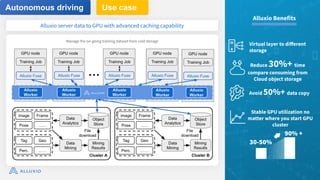




The document discusses optimizing data access for AI workloads in a multi-cloud environment, highlighting the importance of efficient data access to reduce costs and improve performance. It outlines various data access patterns and challenges, such as latency and reliability, while proposing solutions like local caching and distributed cache systems using Alluxio. The content emphasizes the benefits of Alluxio in enhancing GPU utilization and managing training datasets effectively across cloud storage.



































































